SpringAI 를 활용하여 문서를 기반으로 답변하는 챗봇을 만드는 과정 정리.
🧠 RAG 구조 간단 정리
RAG는 크게 두 단계로 나뉘어져 있다.
- Retrieval (검색): 질문과 관련된 문서를 벡터 검색을 통해 가져옴
- Generation (생성): 검색된 문서를 기반으로 답변 생성
Spring-AI는 이걸 아주 간단하게 구성할 수 있도록 DocumentRetriever, EmbeddingModel, VectorStore 같은 컴포넌트 및 상위 인터페이스를 제공한다.
- 아래 그림은 기본적은 RAG 의 흐름을 볼 수 있는 예시이다. 그림에서는 llamaindex, langchain 을 이용했지만, 그 구조는 SpringAI 와 같다.
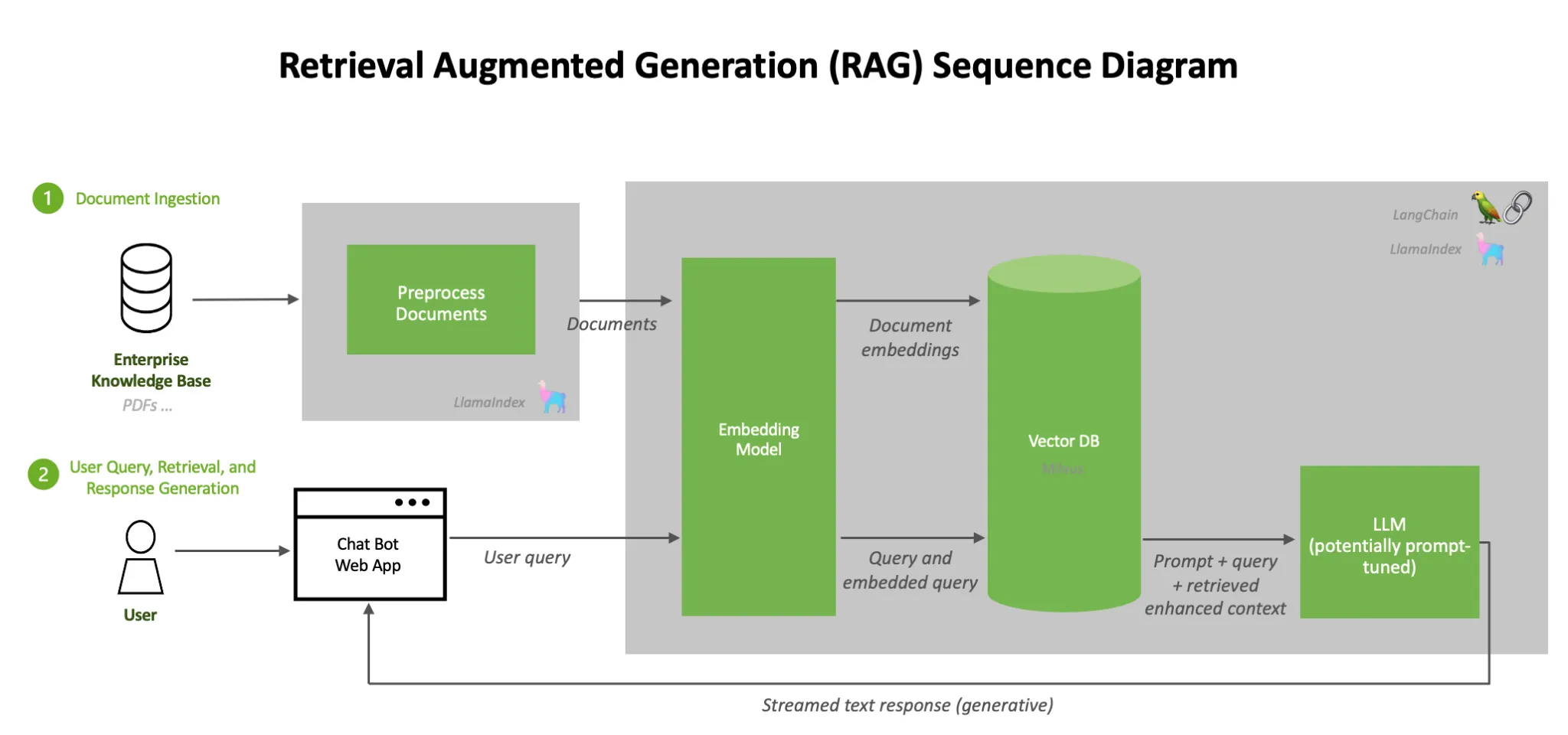
🔧 준비 사항
0. PgVector 설치
- Local 환경에 Pgvector 를 설치하기 위해서는 Postgresql 과 pgvector와 관련된 확장들도 설치해야 하므로 복잡하다. 따라서
Docker를 통해 설치하면 편리하다. - 참고: Pgvector for SpringAI
docker-compose.yml
version: '3.8'
services:
pgvector-db:
image: pgvector/pgvector:pg16 # PostgreSQL with pgvector support
container_name: pgvector-db
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: postgres
ports:
- "5432:5432"
volumes:
- ./postgres/data:/var/lib/postgresql/data1. 의존성 추가
repositories {
mavenCentral()
}
ext {
set('springAiVersion', "1.0.0")
}
dependencies {
implementation 'org.springframework.ai:spring-ai-advisors-vector-store'
implementation 'org.springframework.ai:spring-ai-starter-model-ollama'
implementation 'org.springframework.ai:spring-ai-starter-vector-store-pgvector'
}
dependencyManagement {
imports {
mavenBom "org.springframework.ai:spring-ai-bom:${springAiVersion}"
}
}2. application.yml 설정
spring:
datasource:
url: jdbc:postgresql://localhost:5432/postgres
username: postgres
password: postgres
ai:
ollama:
base-url: http://localhost:11434 # Ollama 서버 URL
chat:
options:
model: gemma3:4b # 사용할 chat 모델
embedding:
options:
model: # RAG 위한 임베딩 모델
vectorstore:
pgvector:
index-type: HNSW
distance-type: COSINE_DISTANCE
# dimensions: 1536 <- 없으면 각 임베딩 모델에 맞는 적절한 dimensions 로 적용됨
max-document-batch-size: 10000 # Optional: 각 배치 마다 처리될 수 있는 최대 document 수📄 문서 임베딩 & 저장
SpringAI 에서는 검색 증강 생성 패턴을 구현하기 위한, ETL(Extract, Transform, and Load) 데이터 엔지니어링과 관련된 컴포넌트 및 인터페이스를 제공한다.
- 문서 데이터를 로드하여 가공 후 Vector DB 에 저장하는 흐름

위 그림과 같이 ETL 을 위한 인터페이스는 크게 DocumentReader, DocumentTransformer, DocumentWriter 가 존재하고, 아래의 클래스 다이어그램은 해당 인터페이스의 구현이 나와 있다.
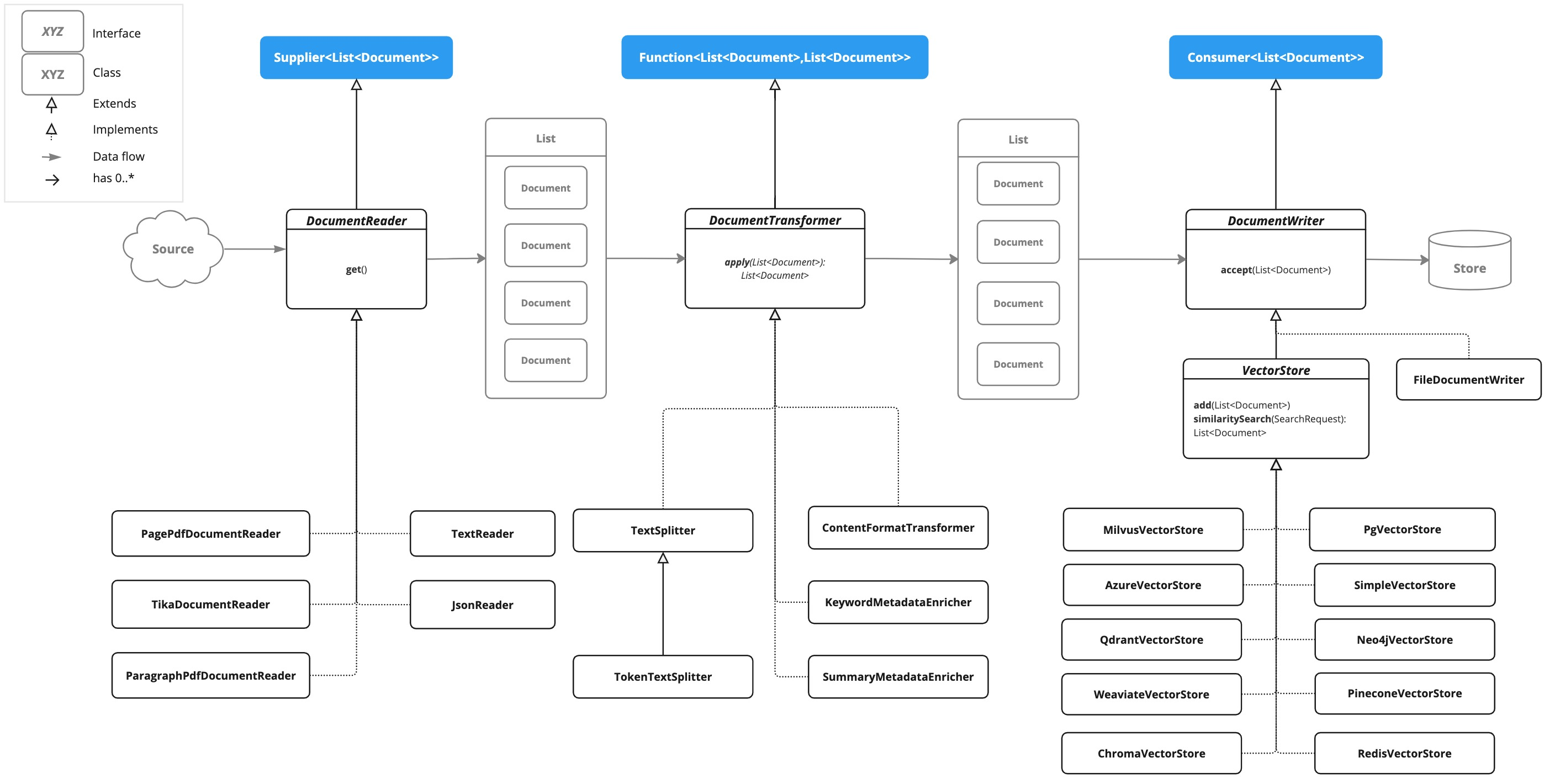
각 구현체를 통해, 문서의 특성 및 상황을 고려하여 ETL 파이프라인을 구성할 수 있다. 또한, 각 문서 특성에 맞는 의존성을 설치하여야 한다. 예를 들어, pdf 문서를 로드하기 위해서는 아래의 의존성을 추가하면 된다.
dependencies {
implementation 'org.springframework.ai:spring-ai-pdf-document-reader'
}- pdf를 로드하고 Vector DB 에 저장하는 예시
@Component
public class MyPagePdfDocumentReader {
private final VectorStore vectorStore;
void getDocsFromPdf() {
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader("classpath:/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
List<Document> docs = pdfReader.get();
vectorStore.add(docs);
}
}💬 Advisor API for RAG
SpringAI 는 RAG 패턴을 쉽게 적용하기 위해 Advisor API를 사용한다.
RAG 패턴은 사용자 프롬프트와 문서의 유사성을 평가하고 비슷한 문서 chunk 를 조합하여 사용자 프롬프트에 추가하는 방식이다. 이를 위해 SearchRequest 를 사용하여 문서 필터 및 유사도 옵션을 설정 가능하다.
QuestionAnswerAdvisor
- 모든 문서에 대한 유사성 검사
ChatResponse response = ChatClient.builder(chatModel)
.build().prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore))
.user(userText)
.call()
.chatResponse();SearchRequest를 사용
유사도 임계값을 0.8 으로 설정하고 검색된 상위 6개 결과를 반환
var qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore) .searchRequest(SearchRequest.builder().similarityThreshold(0.8d).topK(6).build()) .build();
ChatClient 에 Advisor 추가
ChatClient 의 기본 템플릿을 구성하여 Bean 을 설정할 수도 있다.
예를 들어, QuestionAnswerAdvisor 를 기본 Advisor 로 사용하려면 아래와 같이 작성할 수 있다.
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder
.defaultSystem(persona, StandardCharsets.UTF_8) //llm 의 페르소나, 기본 지시사항을 설정
.defaultAdvisors(QuestionAnswerAdvisor
.builder(vectorStore)
.searchRequest(SearchRequest.builder().build())
.build())
.build();
}위와 같이 ChatClient 에 Advisor 를 추가하여 쉽게 QA 챗봇을 구현 가능하다.
📌 마무리
지금까지 문서를 기반으로 답변하는 챗봇, 즉 RAG 시스템을 간단하게 구성해봤다. 실제 서비스에 적용하려면 문서 전처리, 인덱싱 전략, 프롬프트 튜닝 등이 더 필요하지만, 이 정도만 해도 기본 기능은 충분히 구현 가능하다.
다음 글에서는 각 문서 특성에 맞게 문서 처리 파이프라인을 고도화하고, VectorStore 에 문서 chunk 를 저장할 때 Metadata 추가하는 내용을 정리할 것이다.
⏭️ TODO
- 📂 문서 파이프라인 고도화: 분할, 요약, 필터링 전략
- 🧩 Modular-RAG 구조 설계: RAG 와 관련된 처리를 모듈화하여 쉽게 파이프라인 구성하기
- 🧠 LLM 응답 향상을 위한 페르소나 및 시스템 프롬프트 작성
