아래 링크를 이어서 설명합니다.
What is Cypher?
Cypher는 Neo4j 데이터베이스를 쿼리하는 데 사용되는 그래프 쿼리 언어이다.
SQL을 사용하여 MySQL 데이터베이스를 쿼리하는 것과 마찬가지로
Cypher를 사용하여 Neo4j 데이터베이스를 쿼리할 수 있습니다.
간단하게 데이터 가져와 보기
MATCH (m:Movie)
WHERE m.released > 2000
RETURN m LIMIT 5⇒ 2000년대 이후 개봉한 영화의 정보를 가져오는데 5개만 가져와라!
- 실제 응답 데이터
[ { "keys": [ "m" ], "length": 1, "_fields": [ { "identity": { "low": 92, "high": 0 }, "labels": [ "Movie" ], "properties": { "tagline": "Based on the extraordinary true story of one man's fight for freedom", "title": "RescueDawn", "released": { "low": 2006, "high": 0 } }, "elementId": "4:3d177869-2afa-4110-bbf0-2b2dfa85be67:92" } ], "_fieldLookup": { "m": 0 } }, ... ]

MATCH (m:Movie)
WHERE m.released > 2005
RETURN count(m)⇒ 2005년대 이후 개봉한 영화의 갯수를 가져와라!
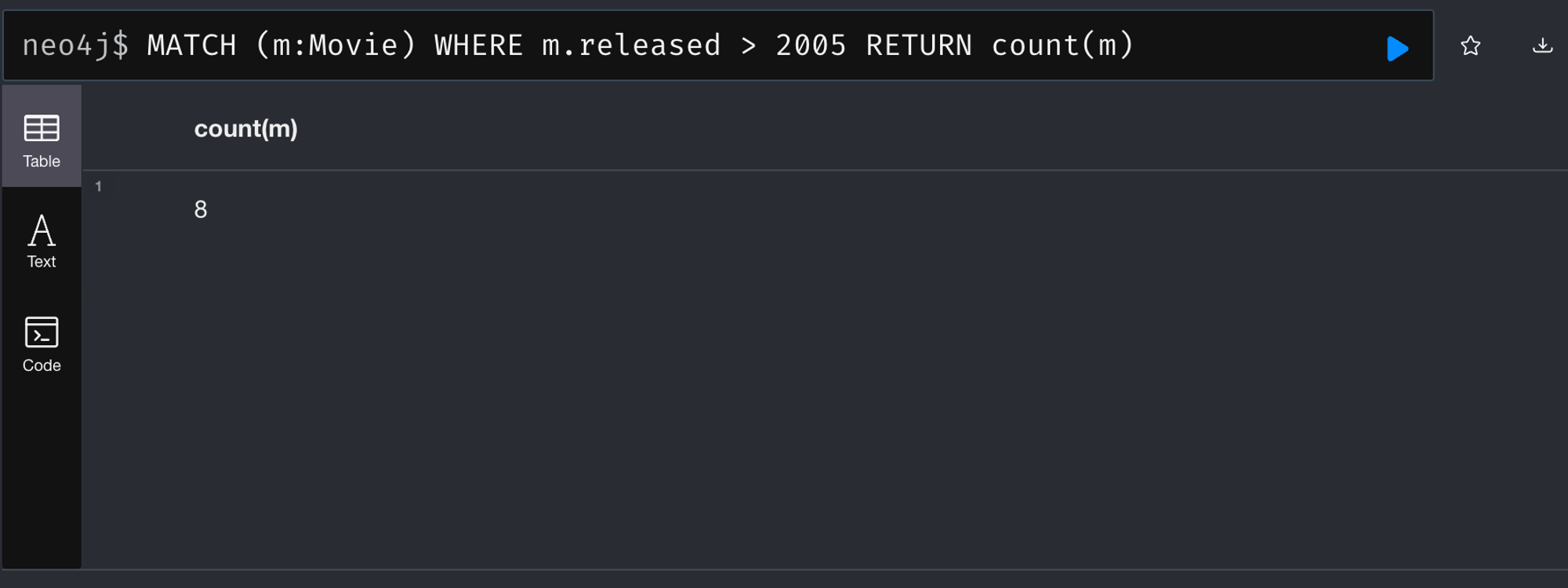
- 실제 응답 데이터
[ { "keys": [ "count(m)" ], "length": 1, "_fields": [ { "low": 8, "high": 0 } ], "_fieldLookup": { "count(m)": 0 } } ]
Node와 Relationships
노드와 관계는 그래프 데이터베이스의 기본 구성 요소이다.
Node
노드는 엔티티를 나타낸다.
그래프 데이터베이스의 노드는 관계형 데이터베이스의 row와 유사하다.
아래 그림에서는 Person과 Movie라는 두 가지 종류의 노드를 볼 수 있습니다.
Cypher 쿼리를 작성할 때 노드는 괄호 안에 괄호로 묶입니다.
(p:Person)과 같이,
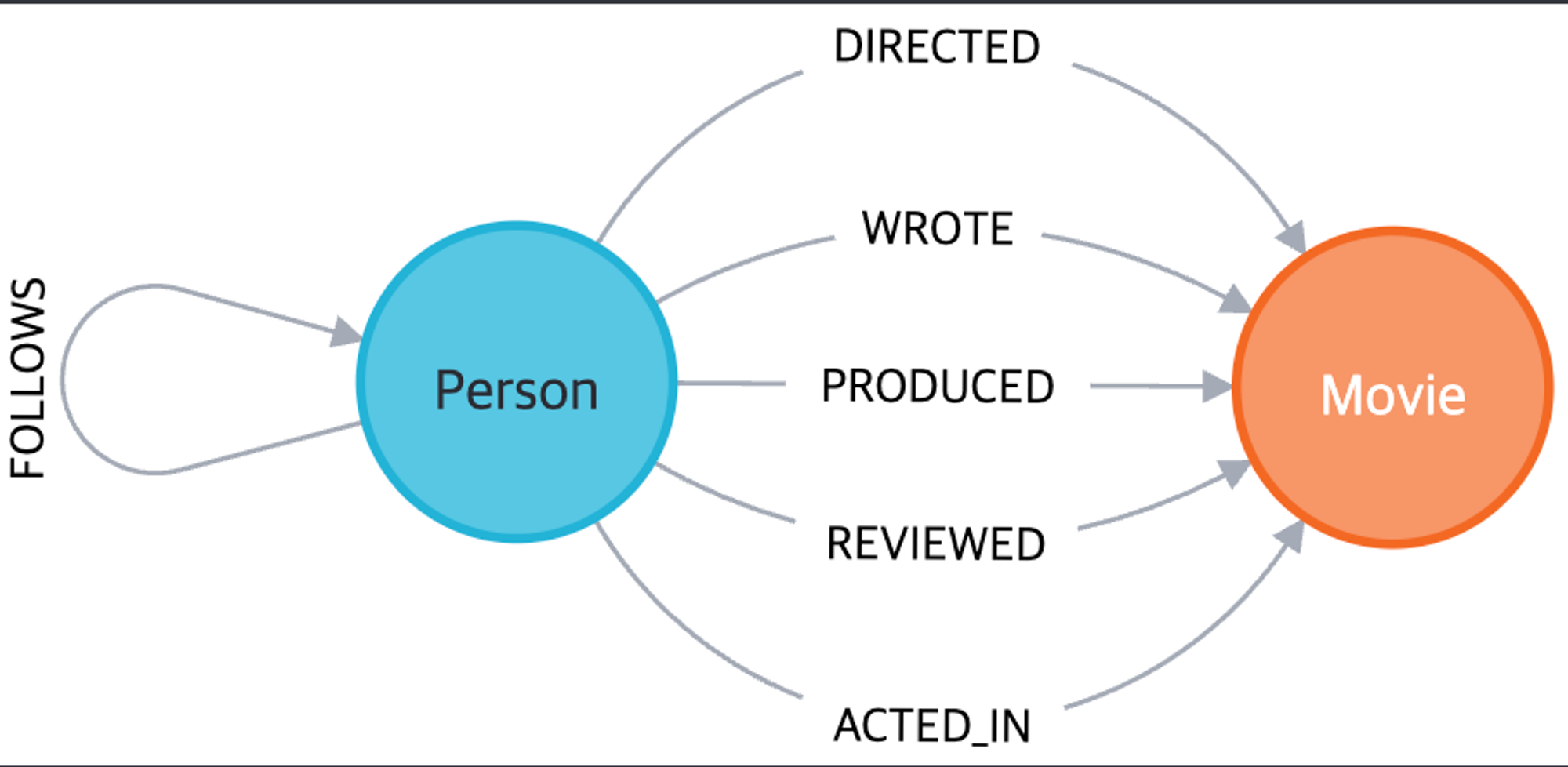
여기서 p는 변수이고 Person은 참조하는 노드 유형입니다.
Relationship
Person 과 Movie 는 하나의 관계로 연결 가능하다.
위 그림에서는 ACTED_IN, REVIEWED, PRODUCED, WROTE 및 DIRECTED 로 연결 되어있는데 이 모든 연결은 노드를 연결하는 관계이다.
Cypher 쿼리를 작성할 때, 관계는 [w:WORKS_FOR]와 같이 대괄호로 묶여 있으며, 여기서 w는 변수이고 WORKS_FOR는 참조하는 관계의 유형입니다.
두 노드는 둘 이상의 관계로 연결될 수 있습니다.
MATCH (p:Person)-[d:DIRECTED]-(m:Movie)
WHERE m.released > 2010
RETURN p,d,m⇒ 2010 이후에 개봉한 영화중에 DIRECTED로 연결되어 있는 Person, DIRECTED, Movie 를 가져와라!
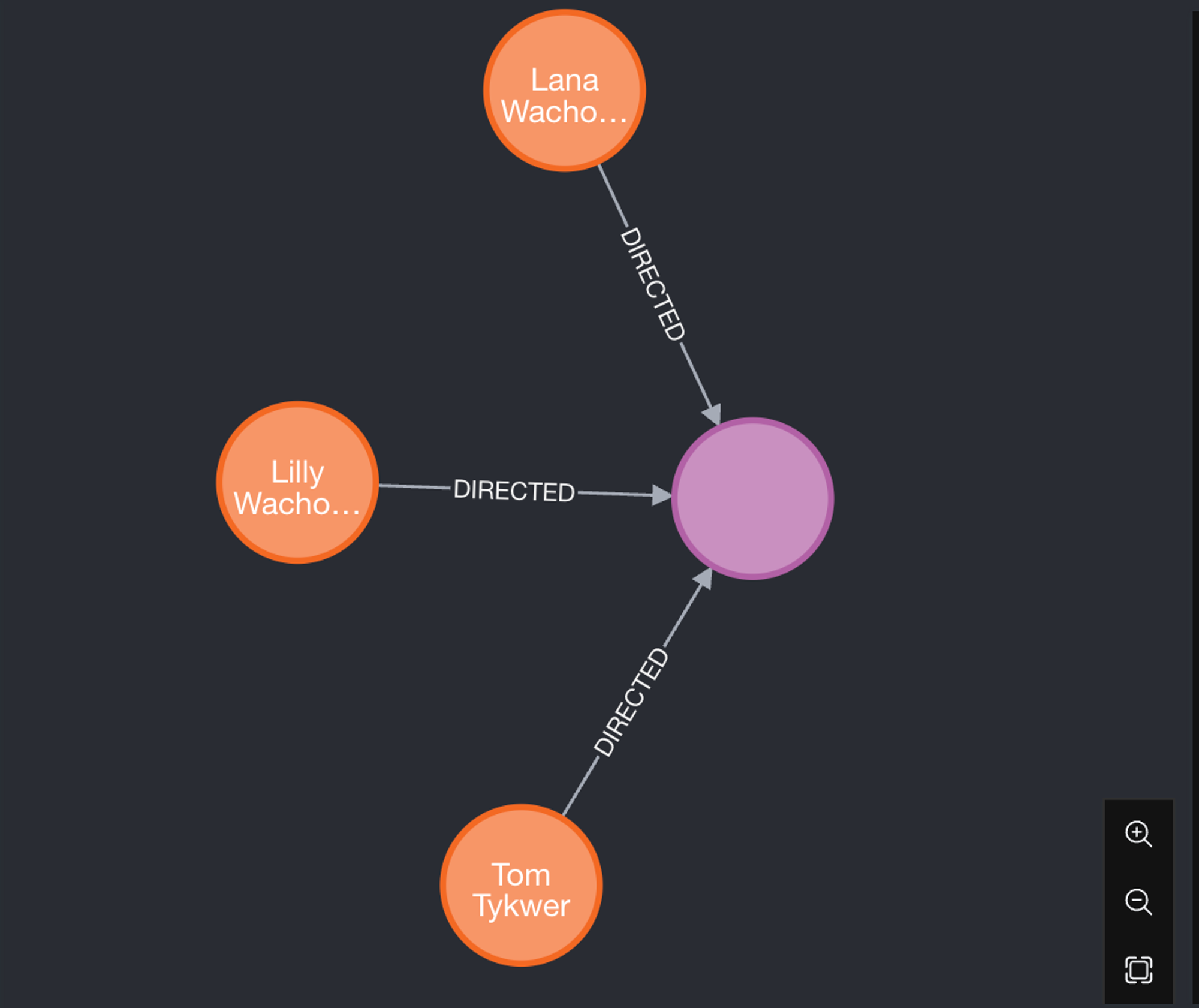
- 실제 응답 데이터
[ { "keys": [ "p", "d", "m" ], "length": 3, "_fields": [ { "identity": { "low": 108, "high": 0 }, "labels": [ "Person" ], "properties": { "born": { "low": 1965, "high": 0 }, "name": "Tom Tykwer" }, "elementId": "4:3d177869-2afa-4110-bbf0-2b2dfa85be67:108" }, { "identity": { "low": 141, "high": 0 }, "start": { "low": 108, "high": 0 }, "end": { "low": 105, "high": 0 }, "type": "DIRECTED", "properties": {}, "elementId": "5:3d177869-2afa-4110-bbf0-2b2dfa85be67:141", "startNodeElementId": "4:3d177869-2afa-4110-bbf0-2b2dfa85be67:108", "endNodeElementId": "4:3d177869-2afa-4110-bbf0-2b2dfa85be67:105" }, { "identity": { "low": 105, "high": 0 }, "labels": [ "Movie" ], "properties": { "tagline": "Everything is connected", "title": "Cloud Atlas", "released": { "low": 2012, "high": 0 } }, "elementId": "4:3d177869-2afa-4110-bbf0-2b2dfa85be67:105" } ], "_fieldLookup": { "p": 0, "d": 1, "m": 2 } }, ... ]
간단 문제
2010년 이후에 개봉한 영화에 출연한 모든 사람을 가져오는 쿼리?MATCH (p:Person)-[a:ACTED_IN]-(m:Movie)
WHERE m.released > 2010
RETURN p,a,m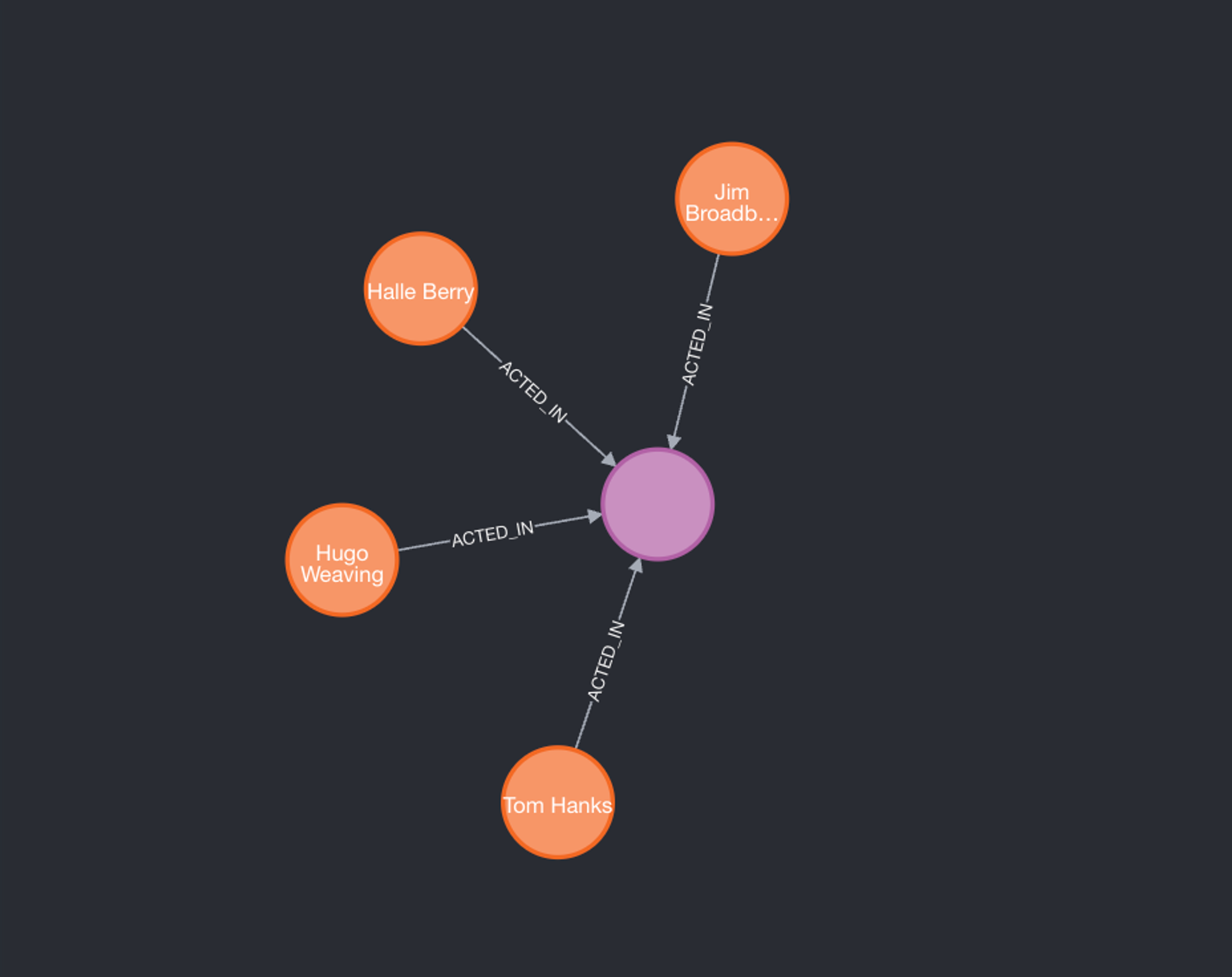
Labels
라벨은 노드 또는 관계의 이름 또는 식별자(별명!)입니다. 식별자는 여러개일수 있음!
아래 이미지에서 Movie와 Person은 노드 레이블이고 ACTED_IN, REVIEWED 등은 관계 유형입니다.
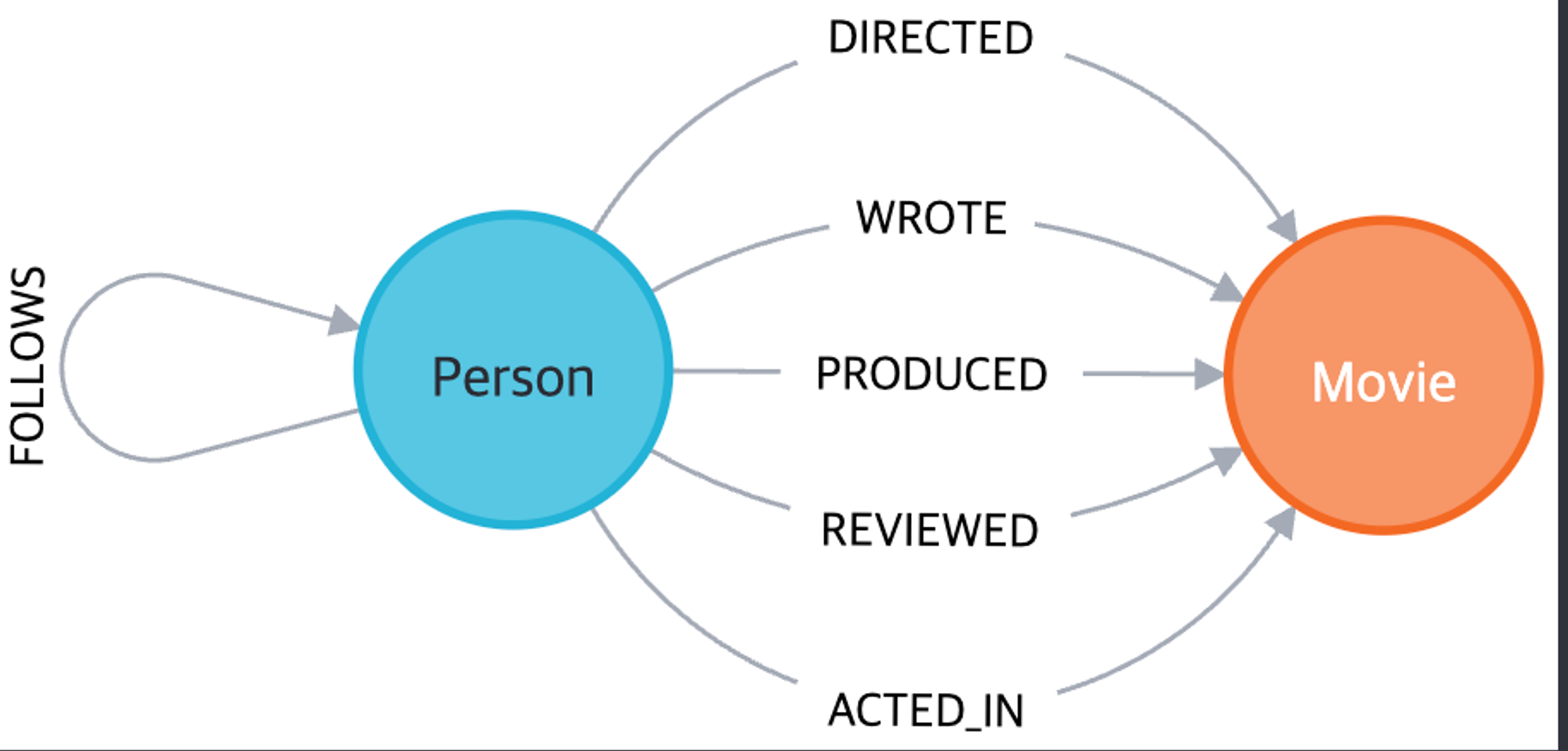
Cypher 쿼리를 작성할 때, 레이블 앞에 콜론이 붙는다(예: :Person 또는 :ACTED_IN)
구문 앞에 변수 이름을 붙여서 노드 레이블을 변수에 할당할 수 있다.
Like(p:Person)는 Person 레이블이 붙은 노드를 나타내는 p 변수를 의미합니다.
레이블은 특정 유형의 노드에서만 작업을 수행하려는 경우에 사용됩니다. Like
MATCH (p:Person)
RETURN p
LIMIT 20위 쿼리는 Person 노드 중 20개만 반환할 것이다.
MATCH (n)
RETURN n
LIMIT 20이 쿼리는 모든 노드중 20개만 반환할 것이다.
Properties
속성은 노드 및 관계에 속성을 추가하는 데 사용되는 name-value 쌍입니다.
노드의 특정 속성을 반환하려면 다음과 같이 작성할 수 있습니다.
MATCH (p:Person)
RETURN p.name, p.born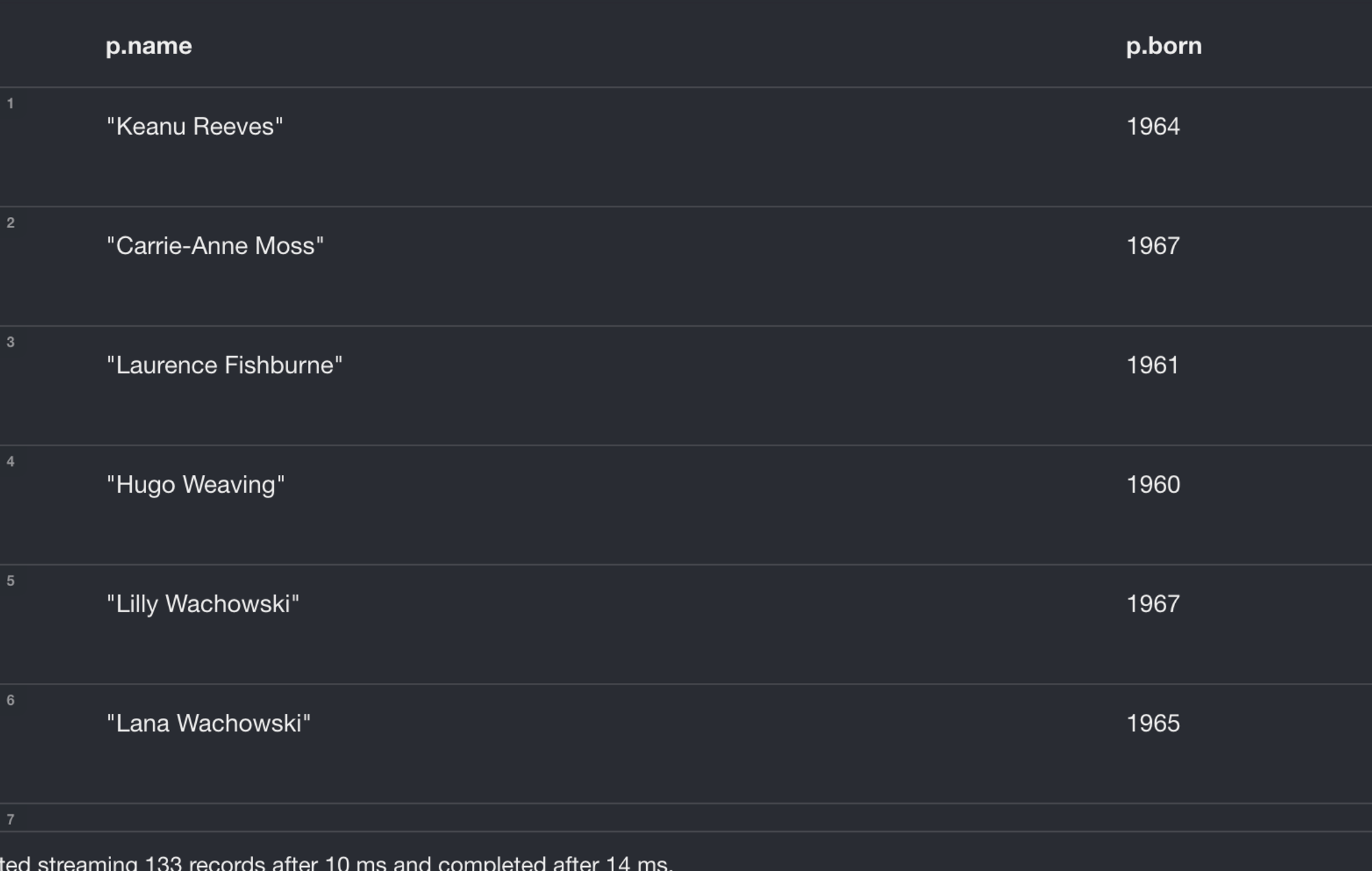
- 실제 응답값
[ { "keys": [ "p.name", "p.born" ], "length": 2, "_fields": [ "Keanu Reeves", { "low": 1964, "high": 0 } ], "_fieldLookup": { "p.name": 0, "p.born": 1 } }, ... ]
Create a Node
CREATE 절을 사용하여 새 노드 또는 관계를 만들 수 있다.
CREATE (p:Person {name: 'John Doe'})
RETURN p⇒ 이름이 John Doe인 새 Person 노드를 생성합니다. 그리고 생성된 노드를 반환한다.
- 실제 응답 데이터
[ { "keys": [ "p" ], "length": 1, "_fields": [ { "identity": { "low": 173, "high": 0 }, "labels": [ "Person" ], "properties": { "name": "John Doe" }, "elementId": "4:3d177869-2afa-4110-bbf0-2b2dfa85be67:173" } ], "_fieldLookup": { "p": 0 } } ]

Match 및 Where 절이 있는 노드 찾기
Match 절은 특정 패턴과 일치하는 노드를 찾는 데 사용됩니다. (마치 SQL의 SELECT 문)
Neo4j 데이터베이스에서 데이터를 가져오는 기본 방법이다!
대부분의 경우 Match는 특정 조건과 함께 사용되어 결과 범위를 좁힙니다. (WHERE 과 같이!)
Match 절
MATCH (p:Person {name: 'Tom Hanks'})
RETURN p⇒ name 이 Tom Hanks 인 노드를 찾아서 반환 하여라!
- 실제 응답 데이터
[ { "keys": [ "p" ], "length": 1, "_fields": [ { "identity": { "low": 71, "high": 0 }, "labels": [ "Person" ], "properties": { "born": { "low": 1956, "high": 0 }, "name": "Tom Hanks" }, "elementId": "4:3d177869-2afa-4110-bbf0-2b2dfa85be67:71" } ], "_fieldLookup": { "p": 0 } } ]

Match 절만 이용하여 필터링 한다면 기본 문자열로만 필터링 가능하다…
Where 절을 이용하여 복잡한 필터링을 해보자!
Where 절
MATCH (p:Person)
WHERE p.name = "Tom Hanks"
RETURN p⇒ name 이 Tom Hanks 인 노드를 찾아서 반환 하여라!
위 쿼리는 Match 절에서 했던 결과와 똑같이 반환된다.
자세한 Where 문법은 여기서 확인하자
간단 문제 : 2010년부터 2015년 사이에 개봉한 모든 영화를 가져오자
MATCH (m:Movie)
WHERE m.released > 2010 AND m.released < 2015
RETURN mMerge 절
MERGE 절은 다음 중 하나에 사용된다.
- 기존 노드를 일치시키고 바인딩하는데 사용
- 새 노드를 생성하고 바인딩하는 데 사용
간단하게 말하면
없으면 새로 생성하고 있으면 가져와서 작업을 수행한다는 뜻!!
ON MATCH와 ON CREATE의 조합으로, 데이터가 matched 하거나 created 된 경우 추가 작업을 지정 가능하다.
MERGE (p:Person {name: 'John Doe'})
ON CREATE SET p.createdAt = timestamp()
ON MATCH SET p.lastLoggedInAt = timestamp()
RETURN p⇒ Person 노드가 존재하지 않는 경우 생성합니다.
- 노드가 이미 존재하는 경우 lastLoggedInAt 속성을 현재 타임스탬프로 설정합니다.
- 노드가 존재하지 않고 대신 새로 생성된 경우, createdAt 속성을 현재 타임스탬프로 설정합니다.
간단 문제
Merge를 사용하여 쿼리를 작성하여 제목이 "Greyhound" 인 Movie 노드를 만듭니다.
노드가 존재하지 않는 경우 해당 노드의 released 속성을 2020으로 설정하고 lastUpdatedAt 속성을 현재 타임스탬프로 설정합니다.
노드가 이미 존재하는 경우 lastUpdatedAt만 현재 타임스탬프로 설정합니다.
동영상 노드를 반환합니다.
MERGE (p : Person { name : "Greyhound" })
ON CREATE SET p.released = 2020, p.lastUpdatedAt = timestamp()
ON MATCH SET p.lastUpdatedAt = timestamp()
RETURN pCreate a Relationship (관계 생성하기)
Relationship 은 두 Node를 연결한다.
MATCH (p:Person), (m:Movie)
WHERE p.name = "Tom Hanks" AND m.title = "Cloud Atlas"
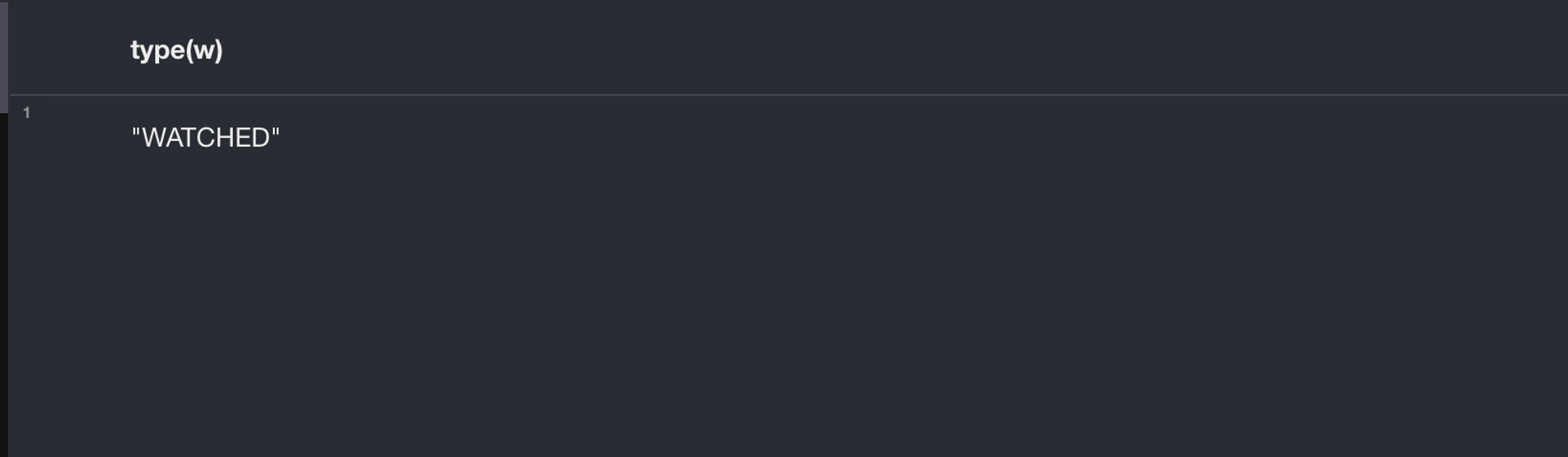
CREATE (p)-[w:WATCHED]->(m)
RETURN type(w)⇒ name이 “Tom Hanks” 인 Person 과 title이 “Cloud Atlas” 인 Movie의 관계중 WATCHED를 생성한다.
또한 WATCHED 의 type을 반환한다.
- 실제 응답 데이터
[ { "keys": [ "type(w)" ], "length": 1, "_fields": [ "WATCHED" ], "_fieldLookup": { "type(w)": 0 } } ]
Relationship Types (관계의 유형)
Neo4j에서는 두가지의 관계 유형이 있다.
- incoming
- outgoing.
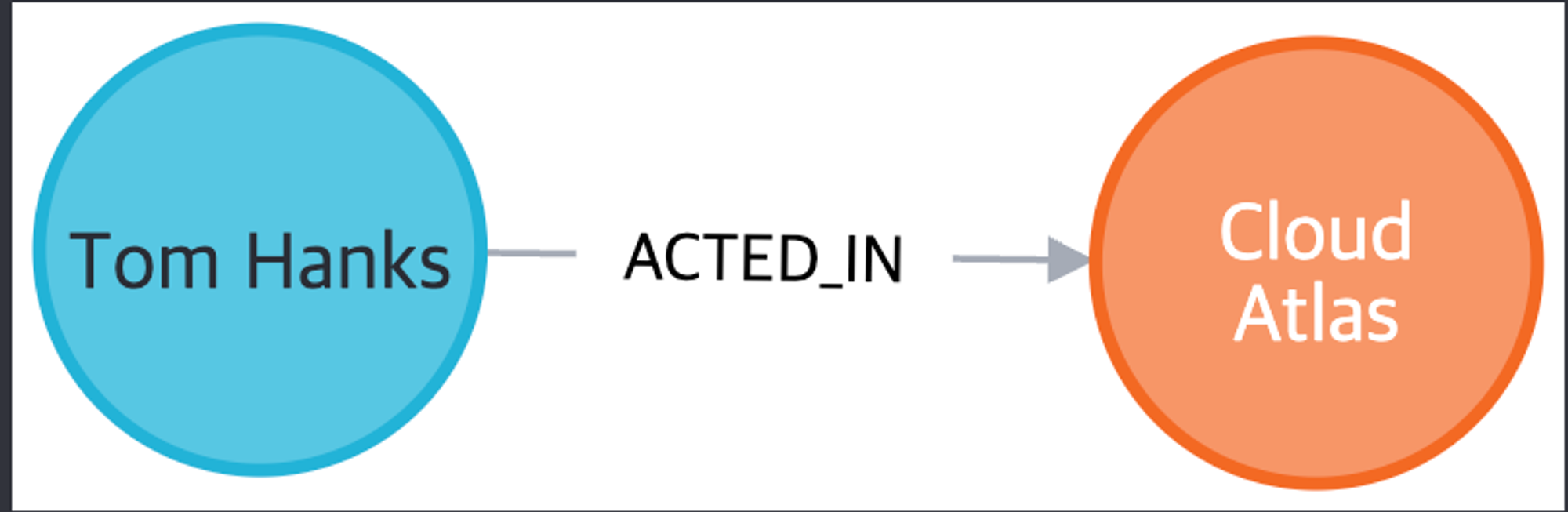
위 그림에서 Tom Hanks 노드는 outgoing 관계이고 Cloud Atlas 노드는 incoming 관계라고 합니다.
관계에는 항상 방향이 있다.
하지만 유용한 방향에만 주의를 기울이면 됩다!
사이퍼에서 나가는 관계 또는 들어오는 관계를 나타내기 위해 → 또는 ←를 사용한다.
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie)
RETURN p,r,m⇒ Person은 outgoing, Movie는 incoming 관계인 모든 Person, Movie

Advanced Cypher queries ( 고급 Cypher 쿼리 )
Cloud Atlas영화를 감독한 사람을 쿼리
MATCH (m:Movie {title: 'Cloud Atlas'})<-[d:DIRECTED]-(p:Person)
RETURN p.nameTom Hanks 와 같이 영화에 출연한 사람들 이름 쿼리
MATCH (tom:Person {name: "Tom Hanks"})-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(p:Person)
RETURN p.name어떤 식으로든 영화 '클라우드 아틀라스'와 관련된 모든 Person 쿼리
MATCH (p:Person)-[relatedTo]-(m:Movie {title: "Cloud Atlas"})
RETURN p.name, type(relatedTo)위의 쿼리에서는 Person 노드와 Movie 노드 "Cloud Atlas" 사이의 모든 관계를 찾으려고 하는 **relatedTo** (아무거나 써도됌)
변수만 사용했습니다.
Kevin Bacon과 3홉 거리에 있는 영화 및 배우 찾기.
MATCH (p:Person {name: 'Kevin Bacon'})-[*1..3]-(hollywood)
RETURN DISTINCT p, hollywood위 쿼리에서 hollywood는 데이터베이스의 모든 노드(이 경우 Person 및 Movie 노드)
또한 중복을 제거하기 위해 DISTINCT 예약어를 이용함
