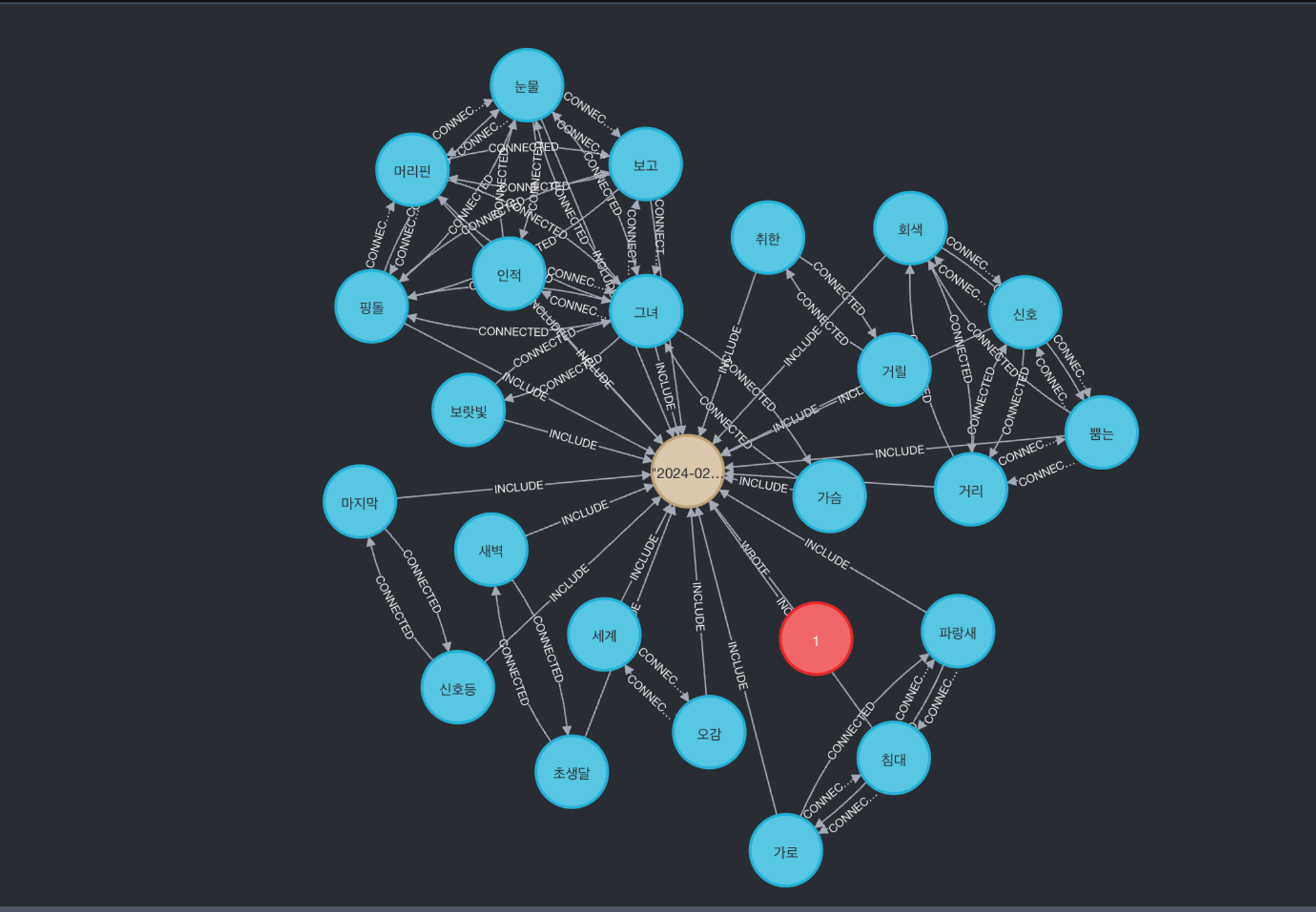
user → diary → (keyword → keyword)
형식으로 그래프가 이루어져 있고
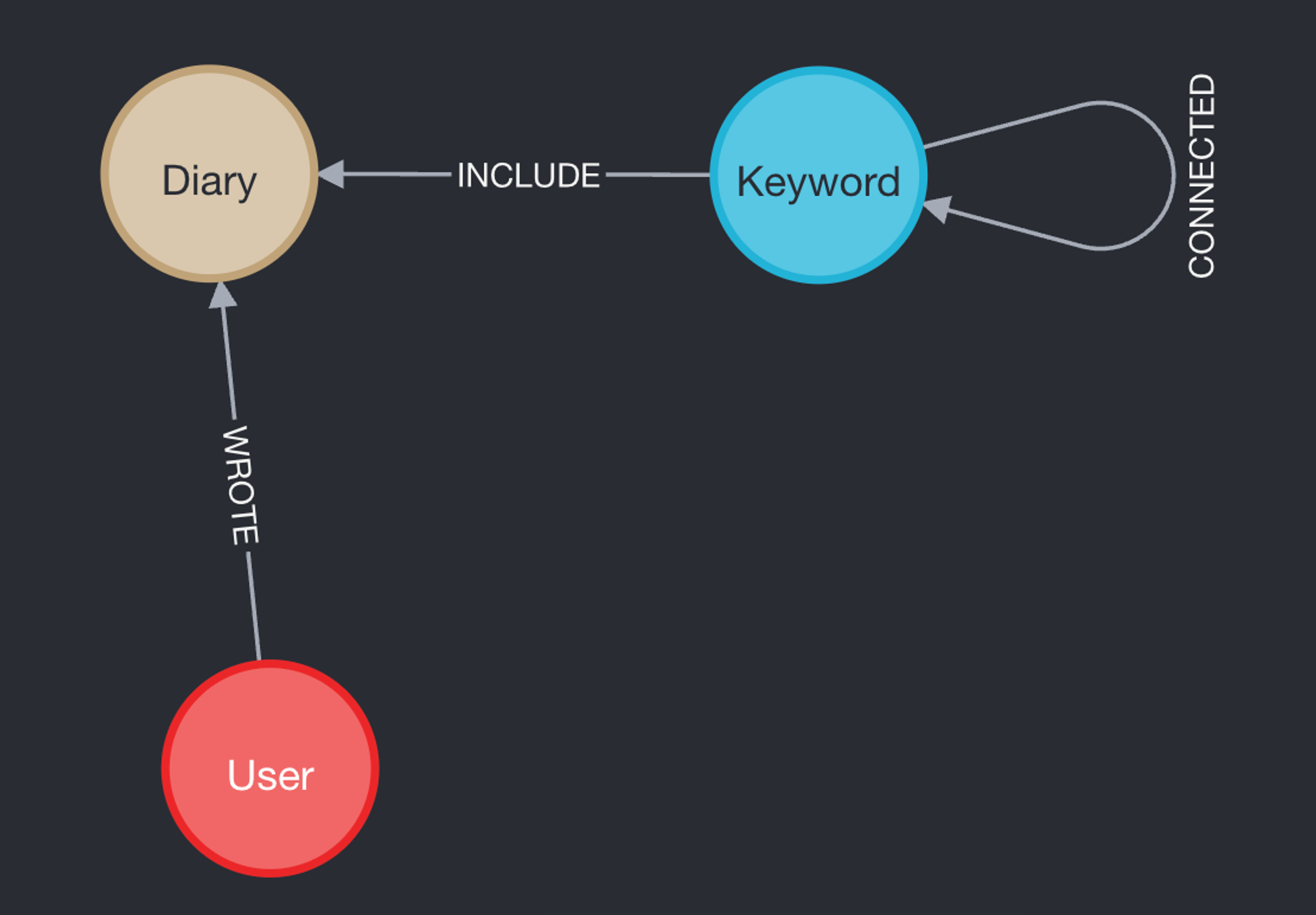
위 형태와 같다..
위 노드와 관계들을 python 으로 가져오는, 삽입하는 과정을 적으려 한다.
-
neo4j 와 통신하는 class 만들어 주기
먼저 graph db 와 통신을 담당하는 class 를 만들어 주자
class GraphDB: def __init__(self, uri, user, password): self._driver = GraphDatabase.driver(uri, auth=(user, password)) def close(self): self._driver.close()생성자로 driver 속성을 만들어 특정 작업때 사용하면 된다.
-
driver, session을 이용하기
def insert_node(self, user_id: int, diary_id: int, graph: np.ndarray, word_dict: dict, weights_dict: dict): """ Insert a node into the graph database. :param user_id: The user's ID. :param diary_id: The diary's ID. :param graph: The graph database. A Numpy array. row and column is the word. == TextRank.words_graph :param word_dict: The dictionary of words. {word_order: word_text} == TextRank.words_dict :param weights_dict: The weights of the words. {index: weight} == Rank.get_ranks(graph) """ with self._driver.session() as session: session.execute_write(self._create_and_link_nodes, user_id, diary_id, graph, word_dict, weights_dict)나같은 경우는 2차원 numpy 배열인 graph 를 받고 그에 맞는 dictionary 들을 받아 데이터를 저장하려 했다.
밑에 보이는
with절에서driver session을 열었다 닫았다 하며 특정 작업을 호출 가능하다.session의 execute_write 메서드를 이용하여 static 메서드를 호출한다.
execute_write메서드는 인자로 실행할 함수를 받고 함수에 넣을 인자도 같이 받는다예를 들어
아래와 같은 static 메서드가 있을때
@staticmethod def _create_and_link_nodes(tx, user_id, diary_id, graph, word_dict, weights): pass필요한 인자인 user_id, diary_id, graph, word_dict, weigths 등을
execute_write메서드 인자로 넣어주면 된다.또한 static 메서드는 session에 의해 실행 되므로 tx 인자를 받는다.
우리는 이 tx를 이용해 cypher 쿼리를 실행 할 것이다.
-
노드 만들기
user_node = tx.run("MERGE (u:User {user_id: $user_id}) " "RETURN u", user_id=user_id).single()[0]tx.run 메서드를 이용해 쿼리를 실행 가능하다 또한 return 구문이 있다면 실행 결과를
iterable 한 Result 객체를 return 받을 수 있다.
-
가져온 데이터 핸들링 하기
위에서 사용한 .single() 메서드는
iterable한 Result 객체에서 맨 처음 record만 가져온다.다른 유용한 메서드로는
.data()메서드로 노드의 모든 정보를list(dictionary)로 반환한다.예를 들어
tx.run("MATCH (k) RETURN k").data() 이런 쿼리는 [ 'k':{ ... }, 'k':{ ... }, ... ]이런식이다.
-
static method 마무리 하기
@staticmethod def _create_and_link_nodes(tx, user_id, diary_id, graph, word_dict, weights): # Create User node user_node = tx.run("MERGE (u:User {user_id: $user_id}) " "RETURN u", user_id=user_id).single()[0] # Create Diary node diary_node = tx.run("MERGE (d:Diary {diary_id: $diary_id, date: date()}) " "RETURN d", diary_id=diary_id).single()[0] # Create relationship between User and Diary tx.run("MATCH (u:User {user_id: $user_id}), (d:Diary {diary_id: $diary_id}) " "MERGE (u)-[:WROTE]->(d)", user_id=user_id, diary_id=diary_id) # graph[i][j] = weight of word i => word i # Create Keyword nodes and their relationships for i, row in enumerate(graph): # row[j] = weight of word i => word j for j, weight in enumerate(row): if i == j: continue if weight == 0: continue # Create Keyword node # Create i node i_node = tx.run("MERGE (k:Keyword {text: $text, weight: $weight}) " "RETURN k", text=word_dict[i], weight=weights[i]).single()[0] # Create j node j_node = tx.run("MERGE (k:Keyword {text: $text, weight: $weight}) " "RETURN k", text=word_dict[j], weight=weights[j]).single()[0] # Create relationship between Keyword and Diary tx.run("MATCH (k:Keyword {text: $text}), (d:Diary {diary_id: $diary_id}) " "MERGE (k)-[:INCLUDE]->(d)", text=word_dict[i], diary_id=diary_id) # Create relationship between Keyword and Keyword tx.run( "MATCH (k1:Keyword {text: $text1}), (k2:Keyword {text: $text2}) " "MERGE (k1)-[:CONNECTED {tfidf: $tfidf}]->(k2)", text1=word_dict[i], text2=word_dict[j], tfidf=graph[i][j] )다양한 키워드의 가중치를 노드에 저장하고 각 키워드별 관계 가중치를 관계를 만들어 저장한다.