
- CatBoost
- gradient boosting algorithm
- Yandex (러시아 검색 엔진 운영 인터넷 기업)에서 개발
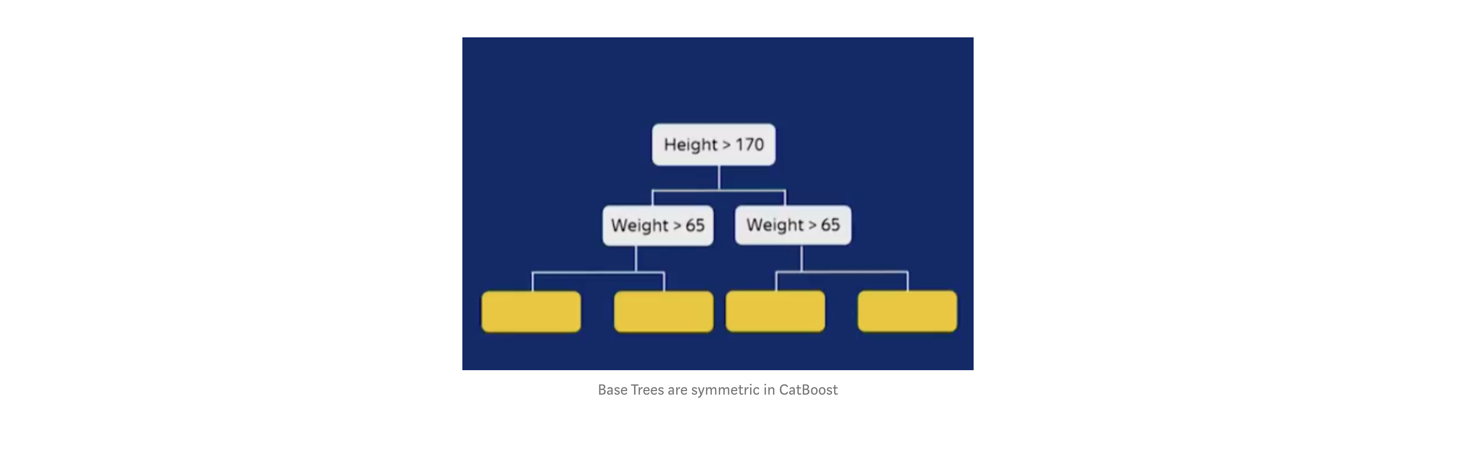
- Base tree structure
- symmetric trees 방식을 사용
- Level-wise 로 트리를 만듬
- prediction time 을 감소시킬 수 있다고함
- Default
max_depth = 6
-
XGBoost, LightGBM의 학습 방식
- 1) 실제 값들의 평균과 실제 값의 차이인 잔차(residual) 를 구한다.
- 2) 데이터로 이 잔차를 학습하는 모델을 만든다.
- 3) 만든 모델로 예측하여, 예측 값에 학습률(learning rate) 를 곱해 실제 예측 값을 업데이트 한다.
- 4) 1 ~ 3 반복
- 이와 같은 학습 방식은 동일한 데이터 포인트 집합에서 이미 훈련된 모형을 사용하여 각 데이터 포인트의 잔차를 계산하기 때문에 과적합의 위험이 있다.
-
CatBoost
- 시간 순으로 정렬된 아래와 같은 데이터가 있다고 해보자.
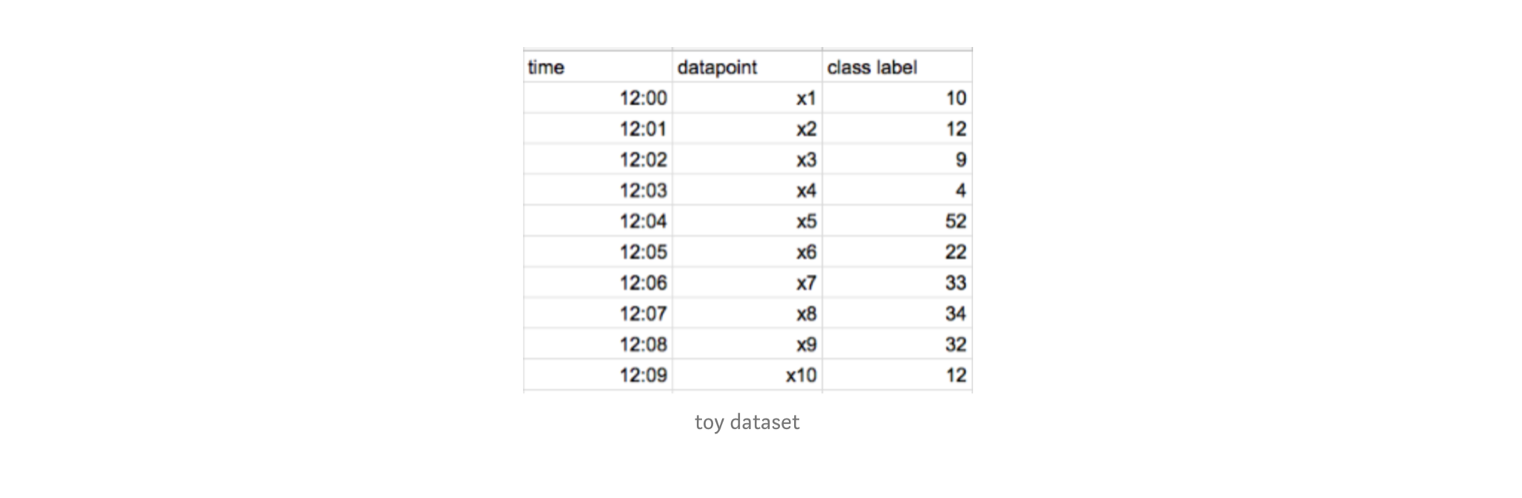
- CatBoost는 Ordered Boosting 방식이다.
- 1) 먼저 x1 의 잔차만 계산하고, 이를 기반으로 모델을 만든다. 그리고 x2 의 잔차를 이 모델로 예측한다.
- 2) x1, x2 의 잔차를 가지고 모델을 만든다. 이를 기반으로 x3, x4 의 잔차를 모델로 예측한다.
- 3) x1, x2, x3, x4 를 가지고 모델을 만든다. 이를 기반으로 x5, x6, z7, x8 의 잔차를 모델로 예측한다.
- 4) 1~3 반복
- 시간 순으로 정렬된 아래와 같은 데이터가 있다고 해보자.
- Ordered Target Encoding
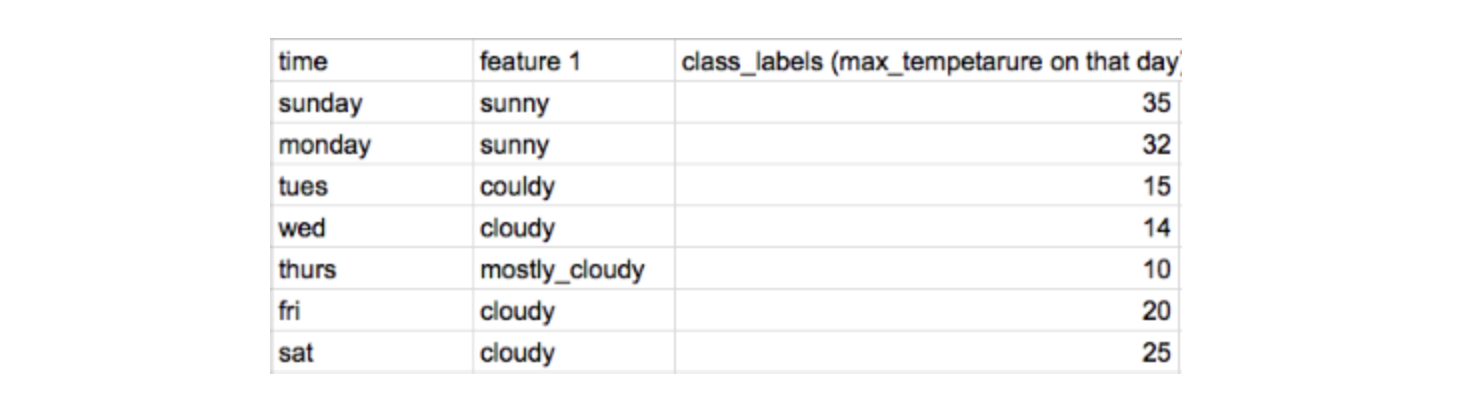
- 범주형 변수를 인코딩 해주는 방법 중 하나 (Target Encoding = Mean Encoding = Response Encoding)
- 위의 데이터에서 time, feature1 으로 class_laabel을 예측한다고 해보면 feature1의 cloudy는 아래와 같이 인코딩할 수 있음
cloudy = (15 +14 +20+25)/4 = 18.5
- 예측 변수가 학습에 들어가는 Data Leakeage 가 발생할 수 있음
- Catboost는 Data Leakage를 방지하기 위해 현재 데이터를 인코딩하기 위해서는 이전 데이터들의 인코딩된 값만 사용함
- Friday 에는
cloudy = (15+14)/2 = 15.5로 인코딩 된다. - Saturday 에는
cloudy = (15+14+20)/3 = 16.3로 인코딩 된다.
- Friday 에는
