Precision-Recall
https://scikit-learn.org/stable/auto_examples/model_selection/plot_precision_recall.html
→ 알고리즘의 성능을 평가하기위해서
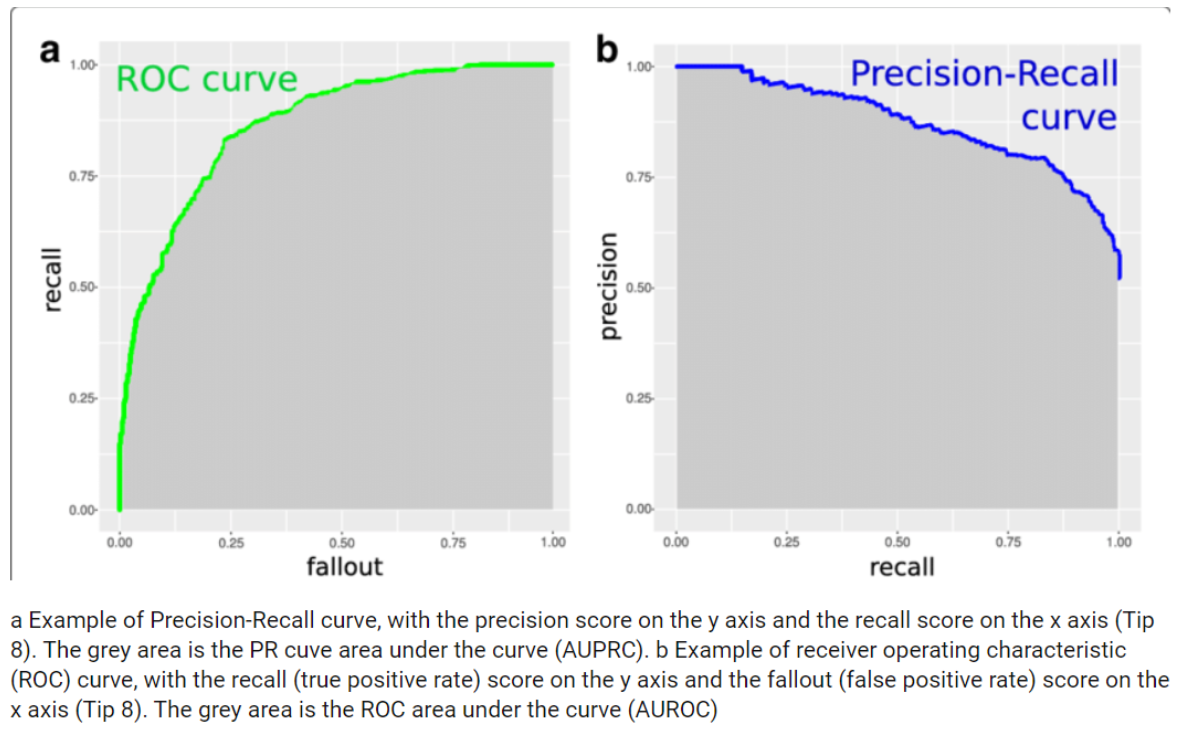
→ High precision은 낮은 거짓양성(false positive)과 관련있고
→ High recall은 낮은 거짓음성(false negative)과 관련있다
→ 서로 반비례적인 경향을 보인다.
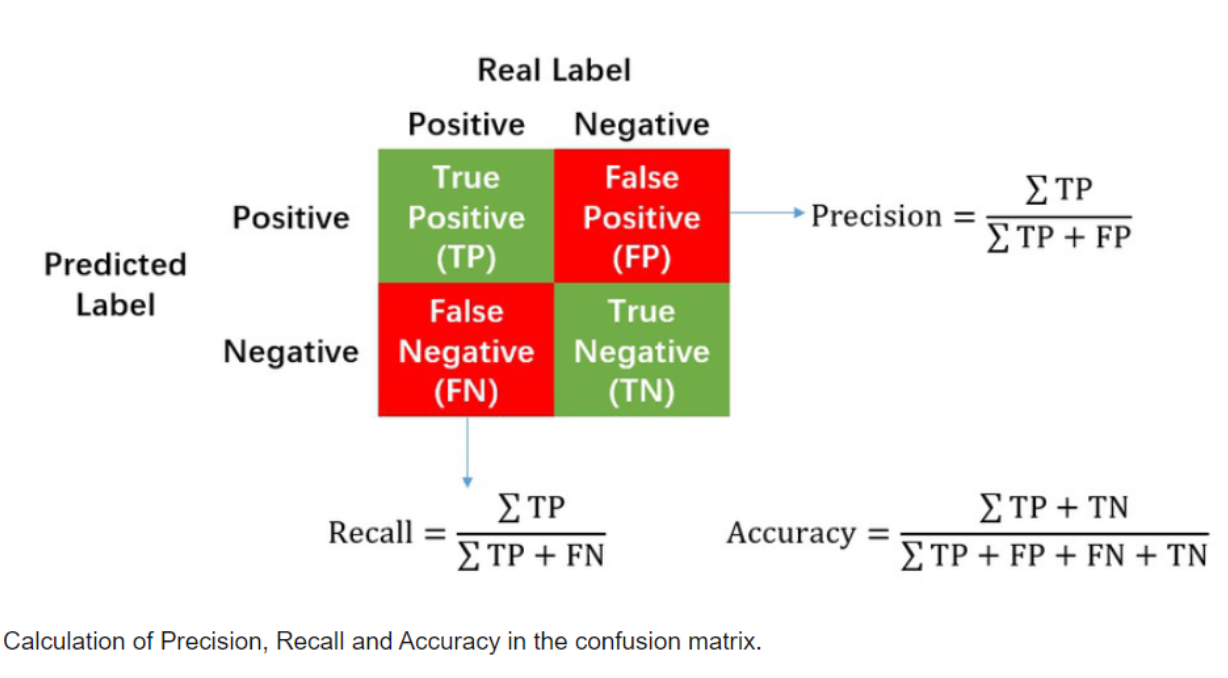
- 거짓 양성(false positive): 1종 오류라고도 하며 실제 음성이지만 결과가 양성으로 나옴
- 거짓 음성(false negative): 2종 오류라고도 하며 실제 양성이지만 결과가 음성으로 나옴
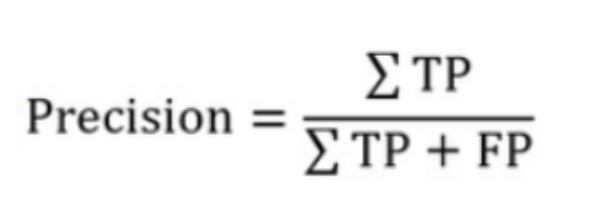
→ Precision은 true positive와 false positive 중 true positive의 비율
→ Precision은 한국어로 정밀도라고 불린다. precision은 모든 검출 결과 중 옳게 검출한 비율
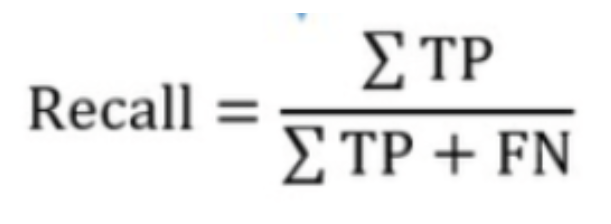
→ Recall은 true positive와 false negative 중 true positive의 비율
→ Recall은 한국어로 재현율이라고 불린다. 마땅히 검출해내야하는 물체들 중에서 제대로 검출된 것의 비율
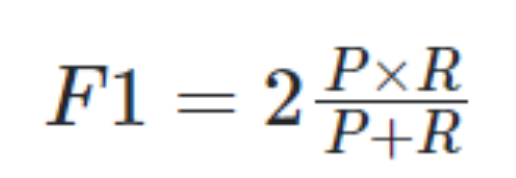
→ F1 score: 2 (Precision Recall) /(Precision + Recall). precision과 recall의 조화 평균, 두 값이 모두 높으면 F1 score도 커진다

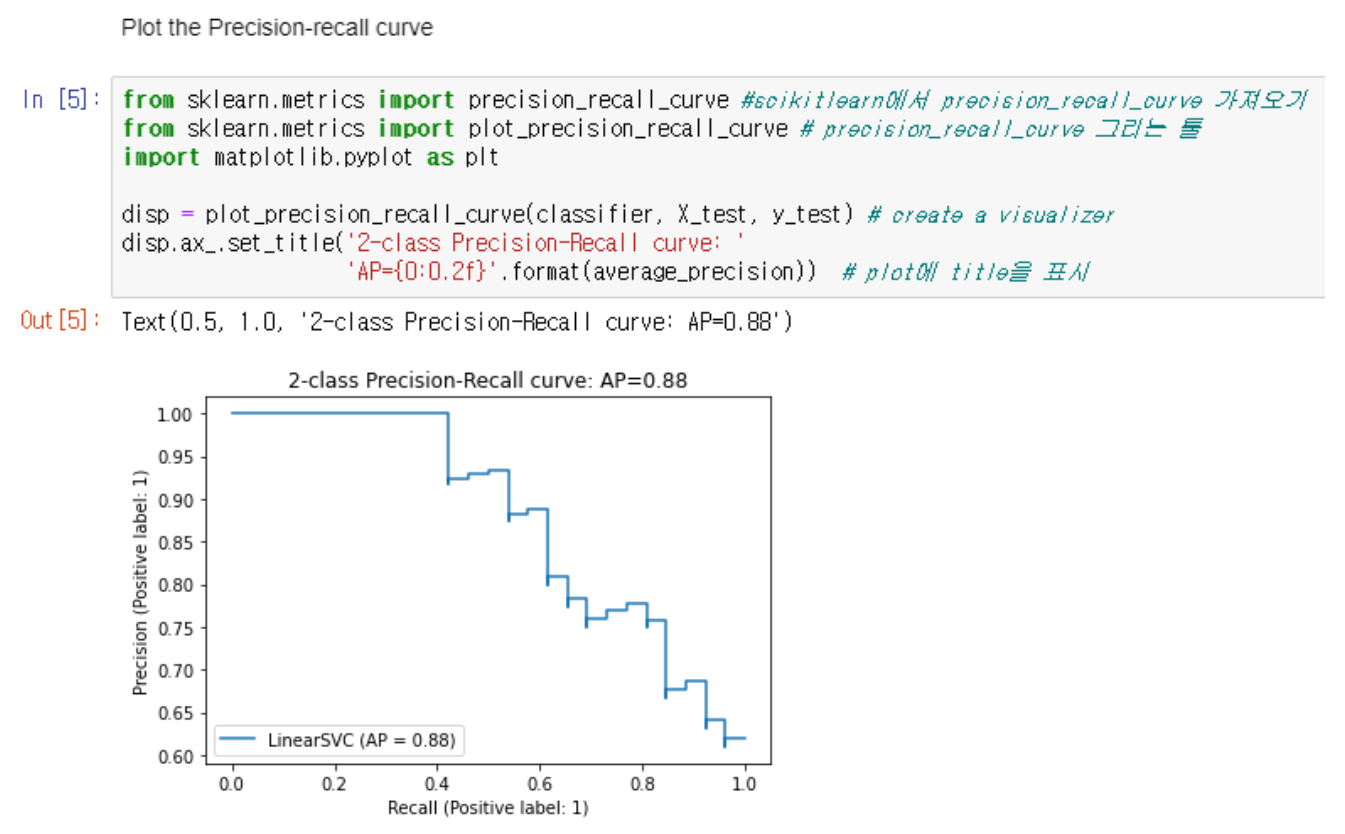
→ Precision이 threshold에 민감하게 영향 받는 이유는 바로 실제로는 음인데 결과상으로 양으로 나온 값들(false positive)에 대한 값이 계산에 포함되기 때문이다. Threshold가 낮아지면 더 많은 결과들이 나오는데 그중에서 false positive가 나올 확률도 높아진다 즉, precision이 낮아질 수 있다.
→ Recall은 이미 결과상으로 positive한 것들의 값이기에 classifier의 threshold가 낮아지면 positive results가 증가한다. 즉 true positive도 증가하기에 Recall이 증가한다. 또한 threshold가 낮아져도 recall은 안바뀔 수 있다.

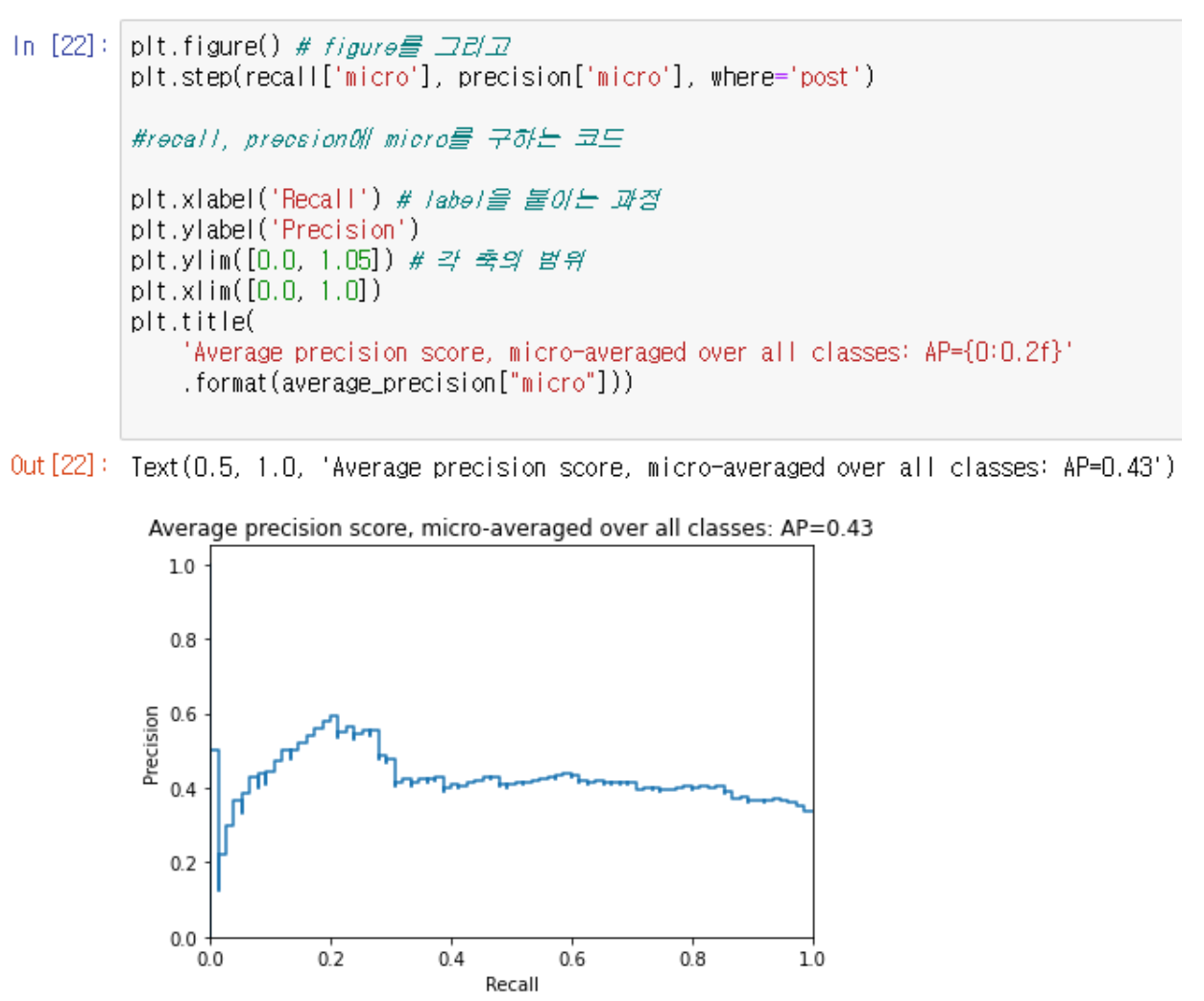
→ AP는 가중치로 사용된 이전 임계값의 재현율 증가와 함께 각 threshold에서 달성된 정밀도의 가중 평균과 같은 플롯을 요약한다
→ 즉 AP는 PR curve의 아래 면적이다
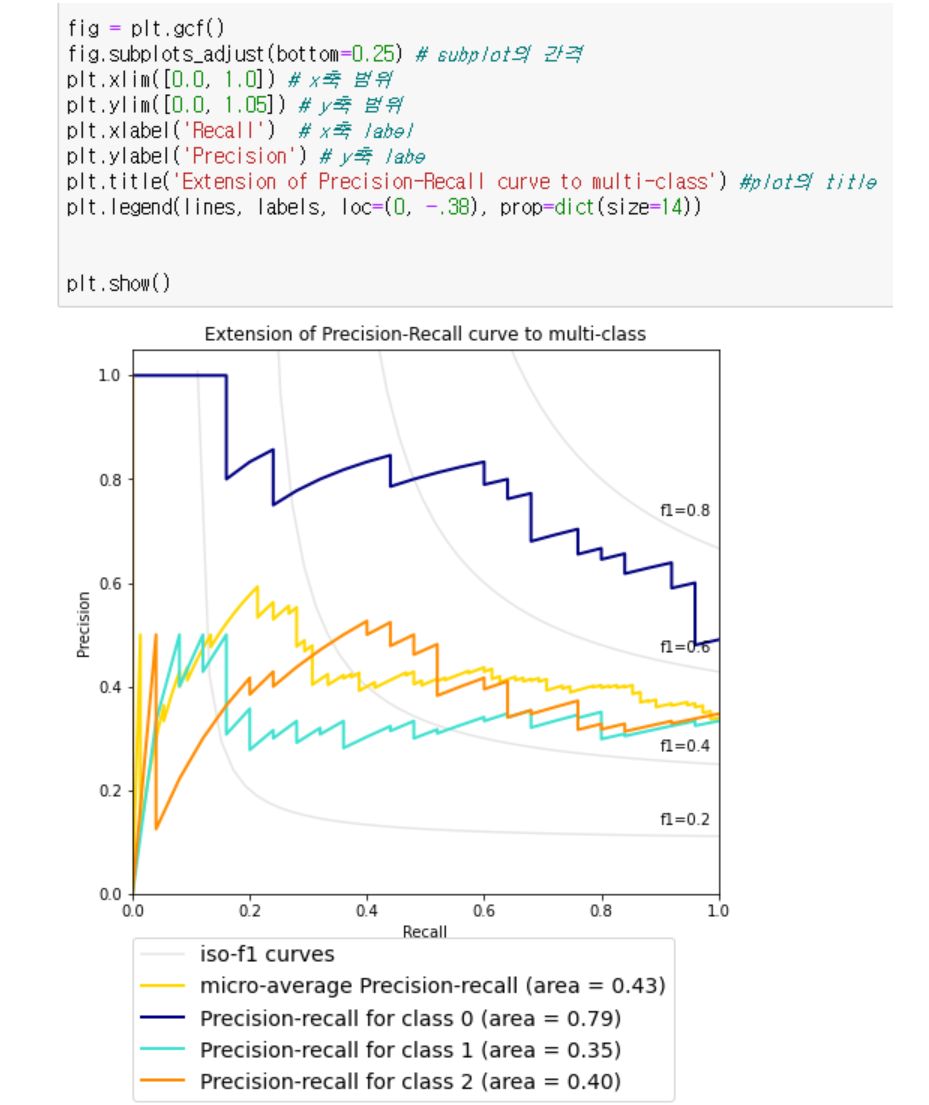
Precision-Recall은 주로 binary classification에 사용되고 precision과 recall을 높이기 위해서는 output이 이분화 되어야한다.
- Macro average: 평균의 평균
- Micro average (micro precision) : 평균을 내는 것이 아니라 그냥 개수 그 자체의 평균 값
→ Macro 값은 precision의 평균 값에 가깝고, Micro 값은 많이 관측된 클래스의 평균에 가깝다. 그래서 클래스의 개수가 불균형적인 데이터에서 micro가 쓰인다.

→ 각 코드에 대한 설명이다

→ iris data가 어떤 형태인지 확인

→ LinearSVC는 어떤 난수 생성기를 사용하는지 확인

→ {0:0.2f}는 ap의 0번쨰 index값의 소수점 2번째 자리까지 표현하는 것이다
Multi-label settings
→ multi-label한 환경에서 진행한다
→ multi-lablel한 데이터인 y를 binarize 시킨다.
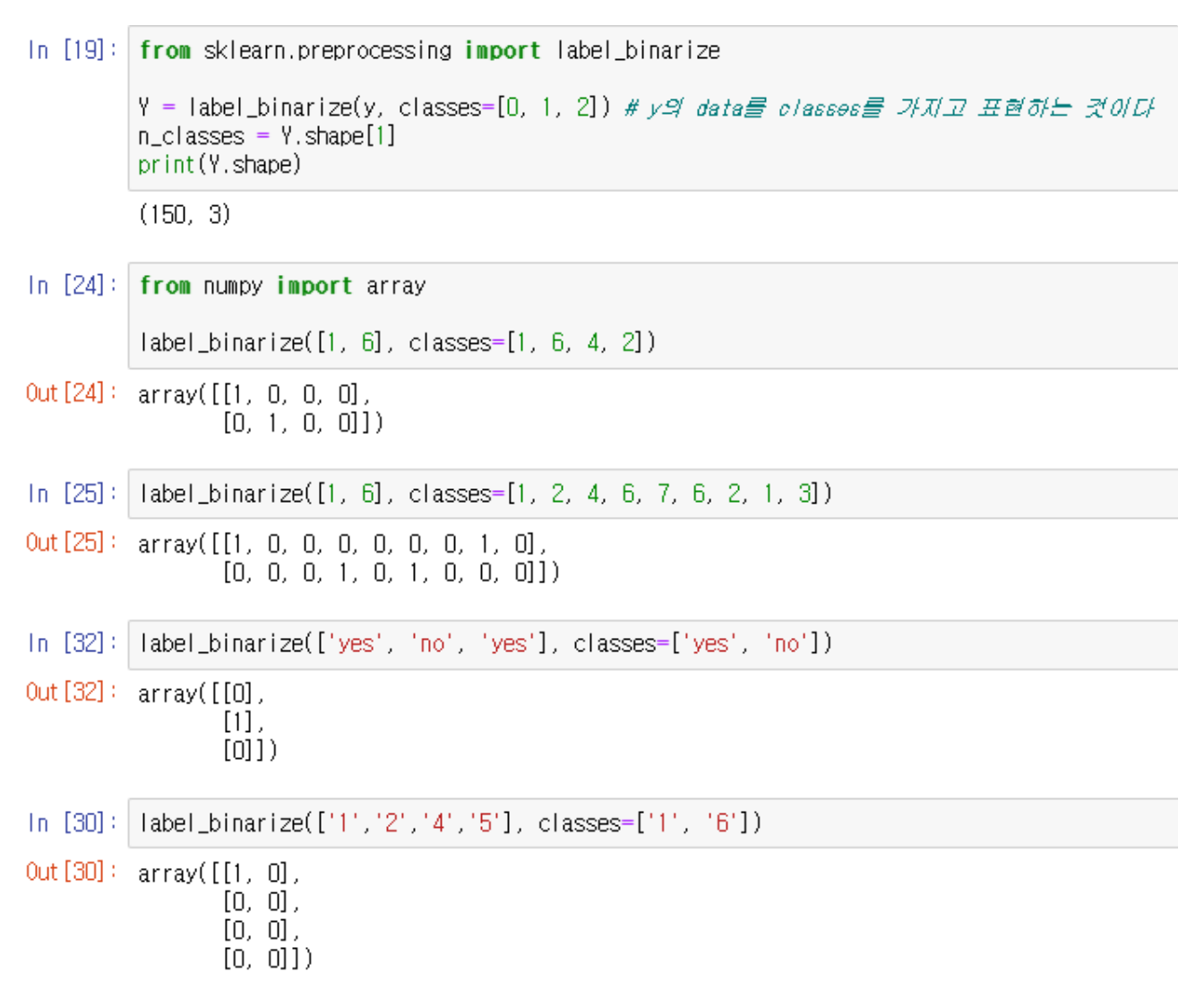
→ binarize 하는 원리
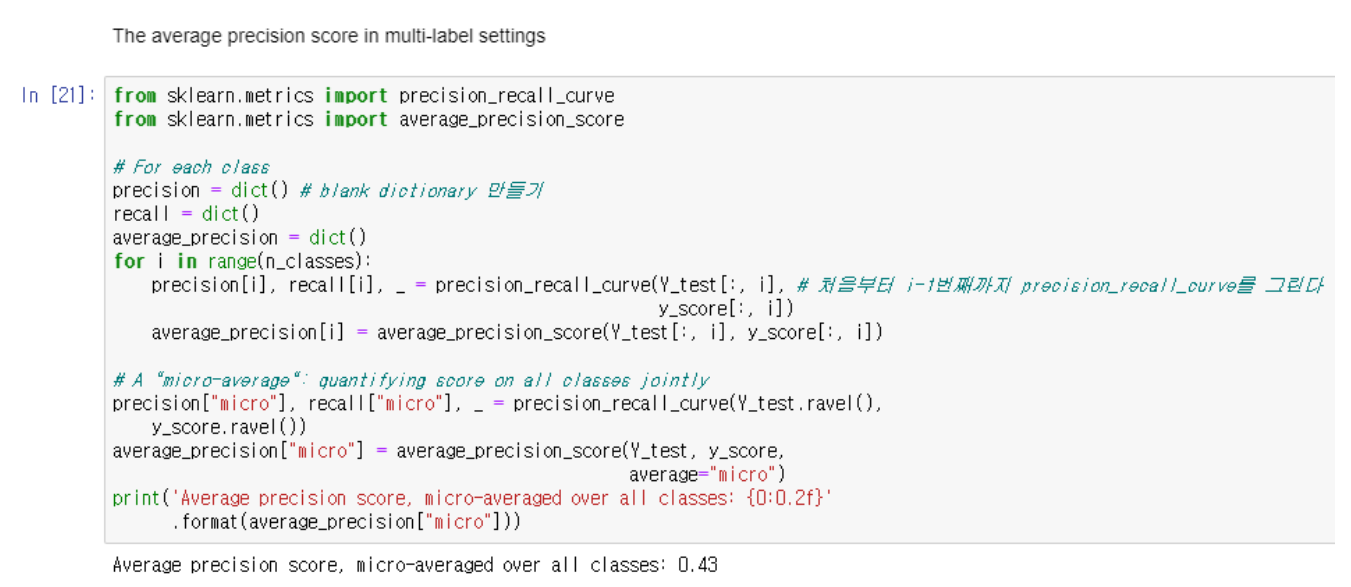
→ AP가 높을수록 성능이 좋다

Reference
https://junklee.tistory.com/116 → Micro precision 관련
https://antilibrary.org/2482 → numpy.linspace 관련
https://bskyvision.com/465 → AP 관련
