
NoSQL
NoSQL은 매우 넓은 범위에서 사용하는 용어로, 관계형 테이블의 레거시한 방법을 사용하지 않는 데이터 저장소를 말한다.
다음과 같은 경우에 많이 사용한다.
- 비구조적인 대용량의 데이터를 저장하는 경우
자유로운 형태로 데이터를 저장할 수 있으므로 필요에 따라 새로운 데이터 유형을 추가할 수 있음 - 클라우드 컴퓨터 및 저장 공간을 최대한 활용하는 경우
클라우드 기반으로 쉽게 분리할 수 있도록 지원하여 저장공간을 효율적으로 사용할 수 있음
SQL은 DB증설 시 수직적 확장 형태로 증설하지만 NoSQL은 수평적 확장의 형태로 증설 함 - 빠르게 서비스를 구축하고 데이터 구조를 자주 업데이트 하는 경우
스키마를 미리 준비할 필요가 없어 빠르게 개발할 경우에 적합함
MongoDB
대표적인 NoSQL 도큐먼트 데이터베이스이다.
도큐먼트 데이터베이스(Document Database)
- 데이터를 문서처럼 저장하는 데이터베이스이다.
- JSON 유사 형식으로 데이터를 문서화 한다.
- 각 도큐먼트는 데이터를
field-value의 형태로 가지고 있고
collection이라고 하는 그룹으로 묶어서 관리한다.
Atlas Cloud
MongoDB에서는 아틀라스로 클라우드에 데이터베이스를 설정한다.
아틀라스는 GUI와 CLI로 데이터를 시각화, 분석, 내보내기, 빌드하는 데에 사용할 수 있다.
아틀라스 사용자는 클러스터를 배포할 수 있으며, 클러스터는 그룹화된 서버에 데이터를 저장한다.
레플리카 세트 (Replica Set)
동일한 데이터를 저장하는 소수의 연결된 머신, 레플리카 세트 중 하나에 문제가 발생하더라도 데이터를 그대로 유지할 수 있다.
인스턴스 (instance)
로컬 또는 클라우드에서 특정 소프트웨어를 실행하는 단일 머신, MongoDB에서는 데이터베이스이다.
클러스터 (Cluster)
인스턴스의 모임을 클러스터라고 한다.
데이터를 저장하는 서버 그룹으로 여러 대의 컴퓨터를 네트워크를 통해 연결하여 하나의 시스템처럼 작동하게 한다.
단일 클러스터에서 각각의 인스턴스는 동일한 복제본을 가지고 있다.이 모음을 레플리카 세트라 한다.
클러스터를 이용하여 배포할 경우 자동으로 레플리카 세트를 생성한다.
정리
| 이름 | 예시 | MongoDB | 설명 |
|---|---|---|---|
| 아틀라스 클러스터 | 클라우드에 있는 서버그룹 | 클라우드 데이터베이스 그룹 | 클라우드 클러스터 |
| 클러스터 | 서버 그룹 | 데이터베이스 그룹 | 네트워크로 연결된 인스턴스의 집합 |
| 인스턴스 | 서버 | 데이터베이스 | 각 인스턴스는 레플리카(복제본)를 가짐 |
| 레플리카 세트 | 복제본 모음 | 레플리카 세트 맴버들은 서로의 정보를 동기화함 |
Atlas Cluster 생성
mongo shell
mongoDB 에서 데이터를 조작하거나 관리 작업을 수행 할 수 있도록 Javascript 으로 mongo shell 스크립트를 작성 할 수 있다.
컬렉션 (Collection)
컬렉션의 물리적 컨테이너는 데이터베이스로 하나의 데이터베이스는 보통 여러개의 컬렉션을 가지고 있다.
RDBMS의 table과 유사한 개념이다.
도큐먼트로 구성된 저장소이다.
일반적으로 도큐먼트 간의 공통 필드가 있다.
도큐먼트 (Document)
필드-값 쌍으로 저장된 데이터
스키마를 강요하지 않으므로 서로 다른 필드를 가질 수 있다
필드 (Field)
데이터 포인트를 위한 고유한 식별자
값 (Value)
주어진 식별자와 연결된 데이터
관계형 데이터베이스와 비교
| RDB | MongoDB |
|---|---|
| 데이터베이스 | 데이터베이스 |
| 테이블 | 컬렉션 |
| 관계 구조 | 도큐먼트 구조 |
| 레코드-필드-값 | 필드-값 |
JSON vs BSON
shell을 이용해 도큐먼트를 조회하거나 업데이트할 때 도큐먼트는 JSON 형식으로 출력된다.
JSON 형식으로 도큐먼트를 작성하기 위해서는 다음과 같은 조건을 만족해야 한다.
- {} 중괄호로 도큐먼트가 시작하고, 끝나야 한다.
- 필드와 값이 콜론(:)으로 분리되어야 하며, 필드와 값을 포함하는 쌍은 쉼표(,)로 구분된다.
- 문자열인 필드도 쌍따옴표("")로 감싸야 한다.
JSON을 이용한 도큐먼트 작성 예시
{ "_id" : "408339803", "data" : ISODate("2022-04-17T05:00:00Z"), "listing_id" : "1038163", "reviewer_id" : "3600539", "reviewer_name" : "riman", "comments" : "I am riman not ramen." }
장점
- 읽기 쉽고 많은 개발자들이 사용하기 편리한 형태를 가지고 있다.
단점
- 파싱이 느리고 메모리 사용이 비효율적이다.
- 기본 데이터 타입만을 지원하기 때문에 사용할 수 있는 데이터 타입에 제약이 있다.
이러한 단점을 해결하기 위한 방안으로 도입한 형식이 BSON 이다.
BSON 예시

BSON은 컴퓨터의 언어에 가까운 이진법에 기반을 둔 표현법이다.
JSON 보다 메모리 사용이 효율적이며 빠르고, 가볍고, 유연하며 더 많은 데이터 타입을 사용할 수 있다.
Importing & Exporting
MongoDB의 데이터는 BSON 형태로 저장되고 보통 읽기 쉬운 JSON 형태로 출력된다.
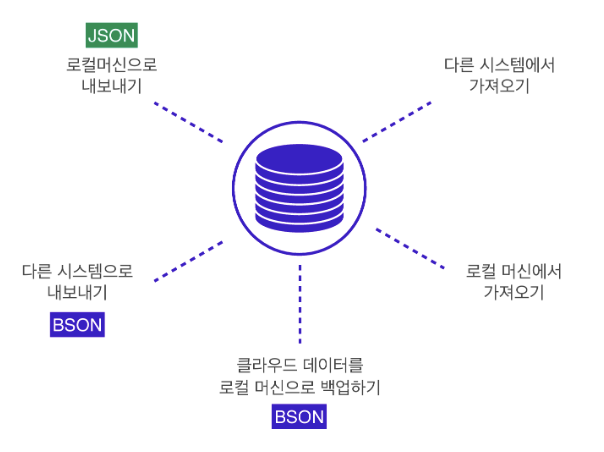
명령어
| import | export | |
|---|---|---|
| JSON | mongoimport | mongoexport |
| BSON | mongorestore | mongodump |
Import
JSON
mongoimport --uri "<Atlas Cluster URI>" --drop=<filename>.jsonBSON
mongorestore --uri "<Atlas Cluster URI>" --drop dump명령어를 사용하기 위해서는 Atlas Cluster URI가 필요하다.
일반 웹의 URI와 형식이 같고 username, password, cluster 주소로 이루어져 있다.기존에 있는 데이터를 삭제하는 옵션인 drop 쿼리문은 선택적으로 사용할 수 있다.
Export
JSON
mongoexport --uri "<Atlas Cluster URI>" --collection=<collection name> --out=<filename>.jsonBSON
mongodump --uri "<Atlas Cluster URI>"BSON의 경우 별다은 쿼리가 없지만 JSON의 경우 데이터베이스의 컬렉션 이름, 파일 이름까지 정확하게 작성해줘야 한다.
CRUD
모든 MongoDB 도큐먼트는 모든 도큐먼트가 _id 필드를 기본값으로 반드시 가지고 있어야 한다.
Create
도큐먼트를 추가할 때 _id 필드와 값을 특정하지 않았다면, 자동적으로 _id 필드가 생성되고 값에 ObjectId(12byte, 24char) 타입이 할당된다.
도큐먼트를 MongoDB 샘플 데이터베이스 중 하나인 zips라고 하는 컬렉션에 insert라는 명령어로 삽입한 결과
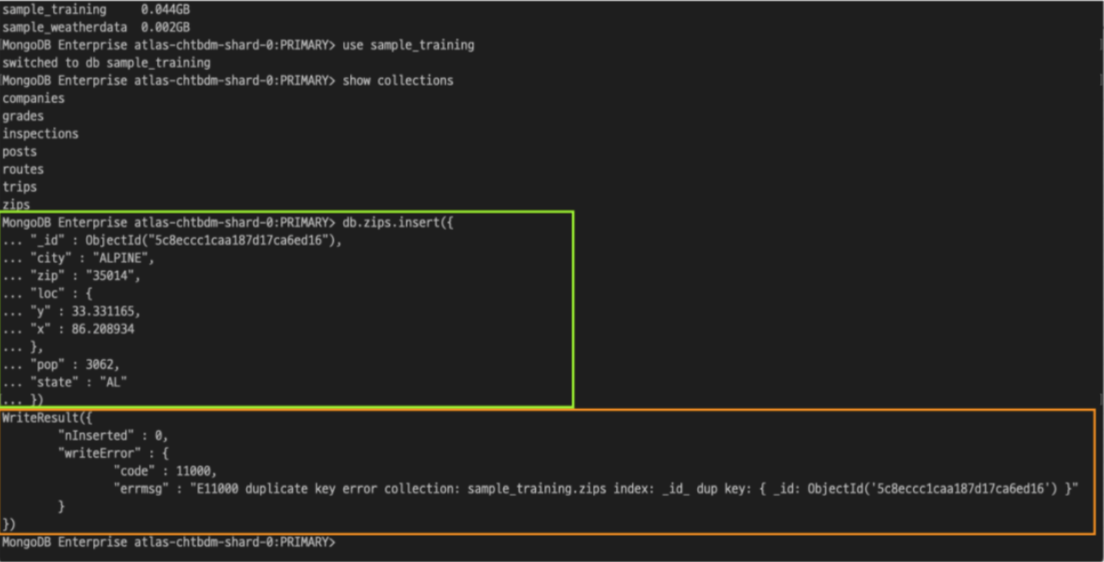
nInserted: 삽입된 도큐먼트의 수
writeError 내용: duplicate key 에러라고 하는 이유로 추가가 되지 않았음
duplicate key 에러: 이미 같은 _id 값을 가지는 도큐먼트가 컬렉션 내부에 존재하기 때문에 중복된 데이터는 삽입할 수 없다.
같은 데이터이지만 _id 값을 지운 도큐먼트를 zips 컬렉션에 추가한 결과
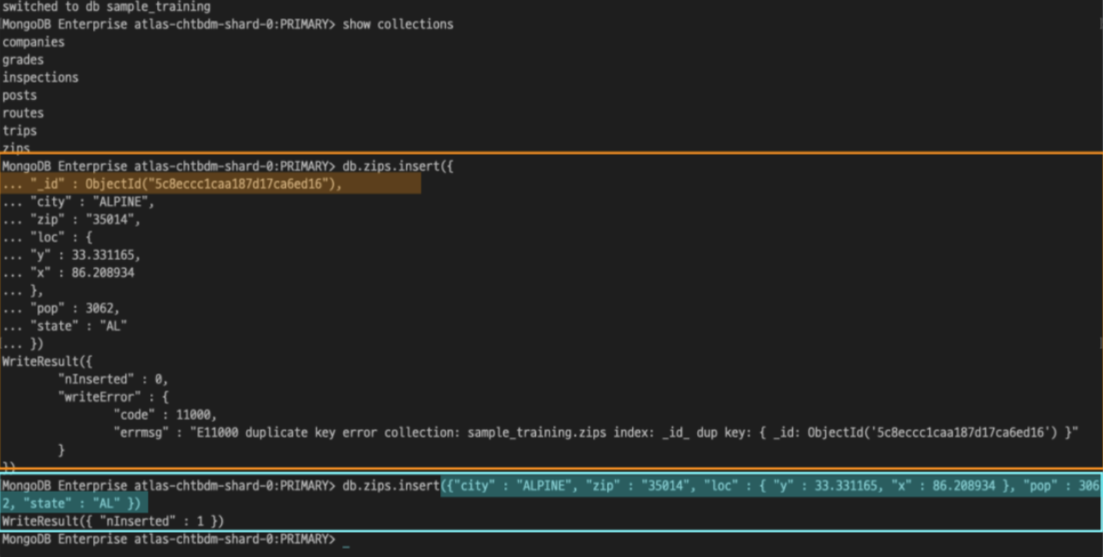
WriteResult({“nInserted” : 1}) 로 zips 컬렉션에 작성한 1개의 도큐먼트가 삽입되었다.
한 번에 다수의 도큐먼트를 삽입하기 위해서는 배열 안에 도큐먼트를 담아줘야 한다.
insert 명령어를 사용하면 주어진 도큐먼트 배열의 인덱스 순서로 작업이 실행된다.
그러나 ordered를 추가하면 순서에 상관 없이 고유한 _id를 가진 도큐먼트는 모두 걸렉션에 삽입된다.
삽입하는 작업에 순서가 없다면 고유한 _id를 가지는 모든 도큐먼트는 컬렉션에 추가된다.
이를 통해 ordered 옵션을 추가함으로 삽입 순서를 바꿀 수 있다는 것을 알 수 있다.
사용자가 존재하지 않는 컬렉션에 도큐먼트를 넣는 경우, 그와 동시에 컬렉션이 만들어지게 된다.
MongoDB도큐먼트 - db.collection.insert()
Read
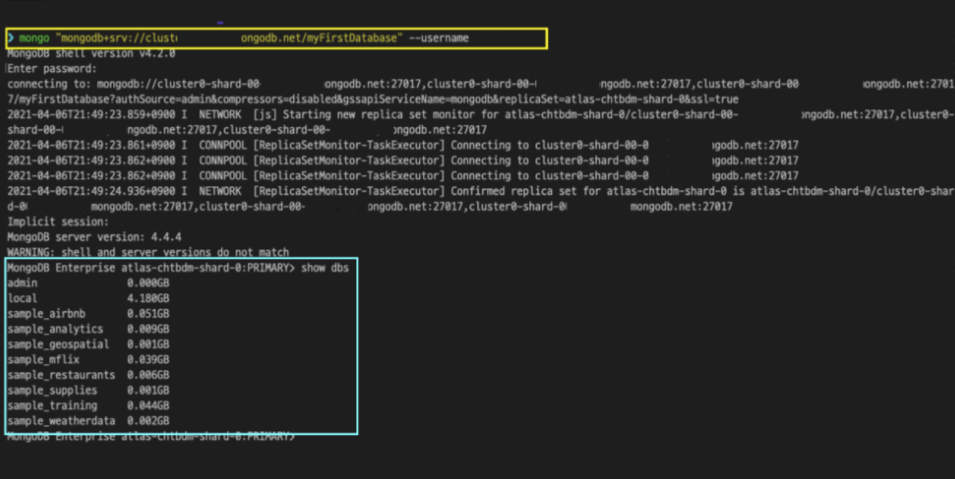
터미널로 아틀라스 클러스터에 접속
show dbs명령어로 미리 받아둔 MongoDB에서 샘플로 제공하는 데이터베이스 리스트를 터미널에서 확인
sample_로 시작하는 데이터베이스가 MongoDB가 테스트용으로 제공하는 더미(dummy)이다.
데이터베이스를 사용: use 데이터베이스이름
데이터 컬렉션 확인: show collections
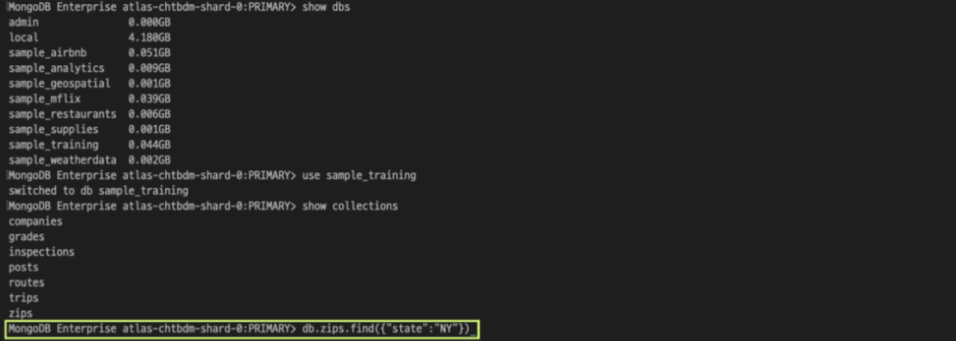
컬렉션내 데이터 조회: db_컬렉션이름.find(쿼리문)
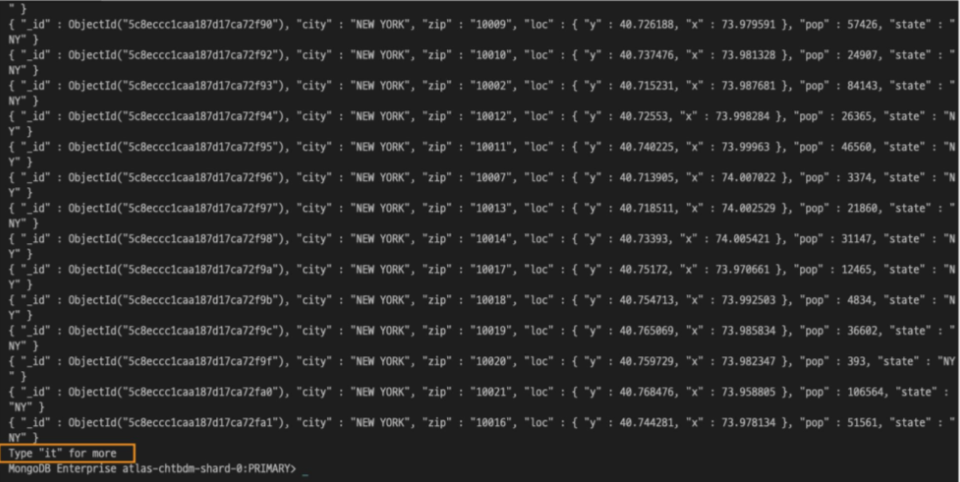
db.zips.find({“state” : “NY”})의 결과물이 JSON 형식으로 화면에 출력
find 명령어에 따른 실제 결과물은 화면에 출력된 것보다 훨씬 많지만 화면에는 랜덤하게 선택된 20개 결과물만 출력된다.
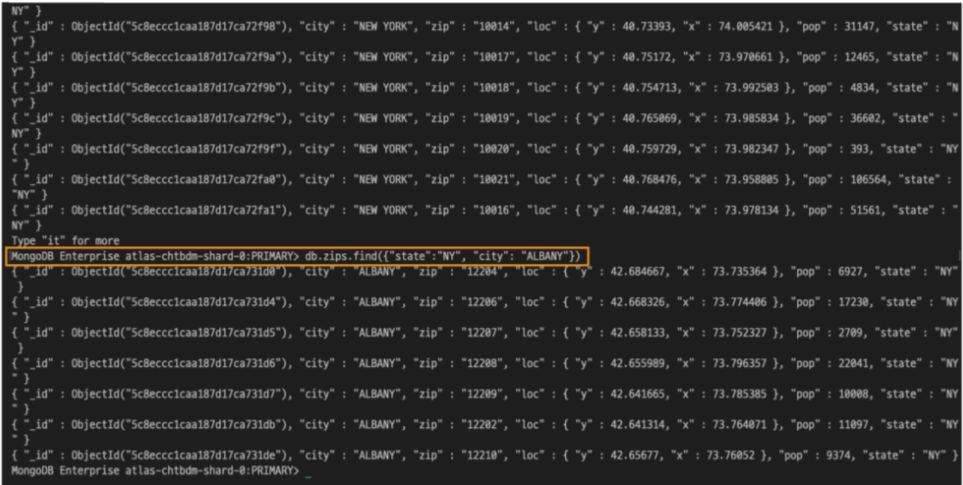
zips 컬렉션의 데이터 중 뉴욕 주에 위치한 ALBANY시의 우편번호만 보고 싶을 경우
두가지 조건을 쿼리문으로 작성한다.
db.zips.find({“state” : “NY”, “city” : “ALBANY”})
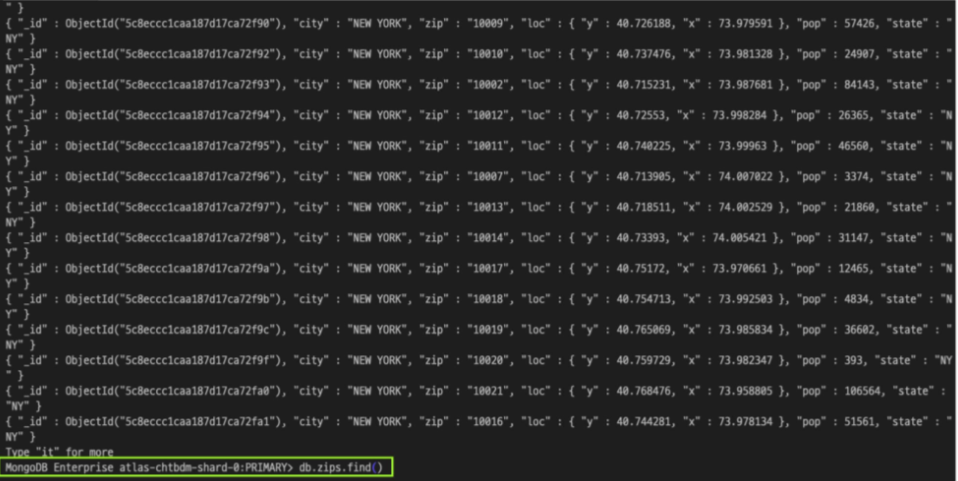
데이터베이스의 모든 데이터를 조회하고 싶다면, find 명령어를 조건 쿼리문 없이 사용하면 된다.
db.zips.find()
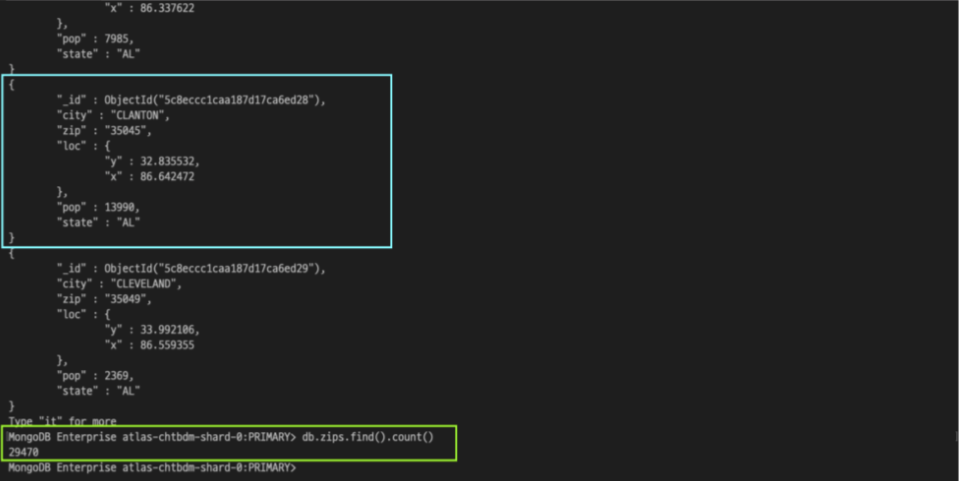
데이터의 수를 조회하기 위해서는 count( )라고 하는 명령어를 사용한다.
db.zips.find().count()
특정한 1개의 데이터 조회: db.컬렉션.findOne(쿼리문)
무작위 1개의 데이터 조회: db.컬렉션.findOne()
MongoDB도큐먼트 - db.collection.find()
Update
쿼리문과 일치하는 도큐먼트 중 첫번째 도큐먼트 하나만 업데이트: updateOne()
쿼리문과 일치하는 모든 도큐먼트 업데이트: updateMany()

zips컬렉션의 city가 ALPINE이라는 값을 가진 모든 도큐먼트의 pop 필드를 10만큼씩 증가시키는 명령어
db.zips.updateMany({"city":"ALPINE"},{"$inc":{"pop":10}})
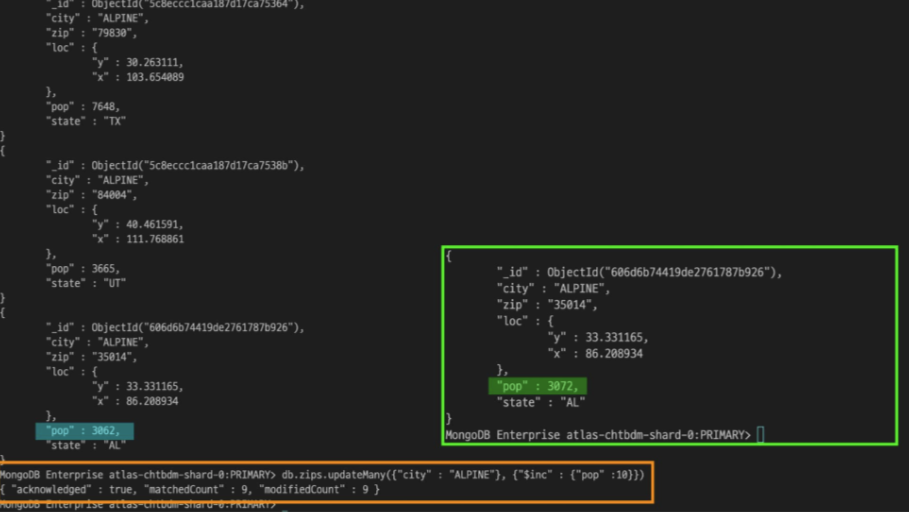
응답이 matchedCount와 modifiedCount로 나뉜다.
해당 부분은 명령어에 들어가는 쿼리문 2개에 대한 응답
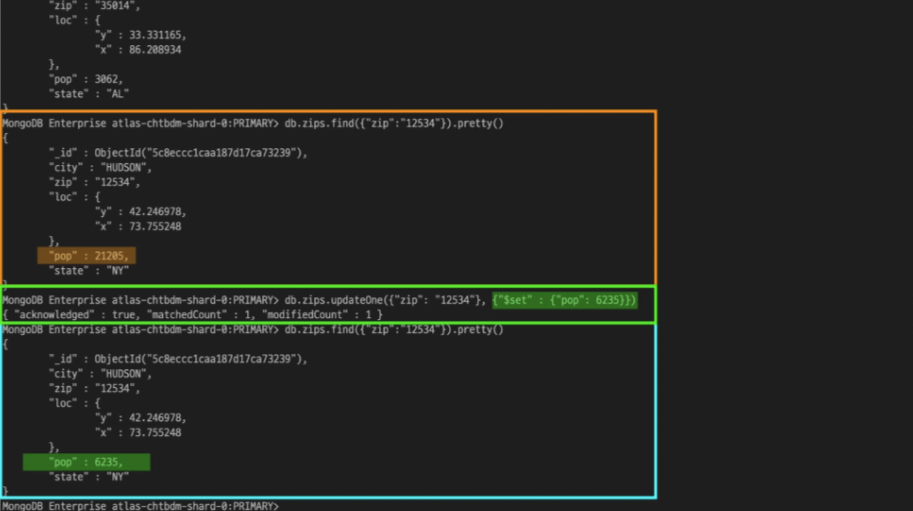
updateOne()사용 시 $inc 연산자를 사용하는 것은 복잡할 수 있다.
$set 연산자를 사용하면 주어진 필드에 지정된 값을 업데이트한다.
{“zips”: “12534”}에 해당하는 도큐먼트의 pop 필드가 $set 연산자를 사용해 지정한 값인 6235로 변경되었다.
다음은 $push 연산자 사용 예시이다.
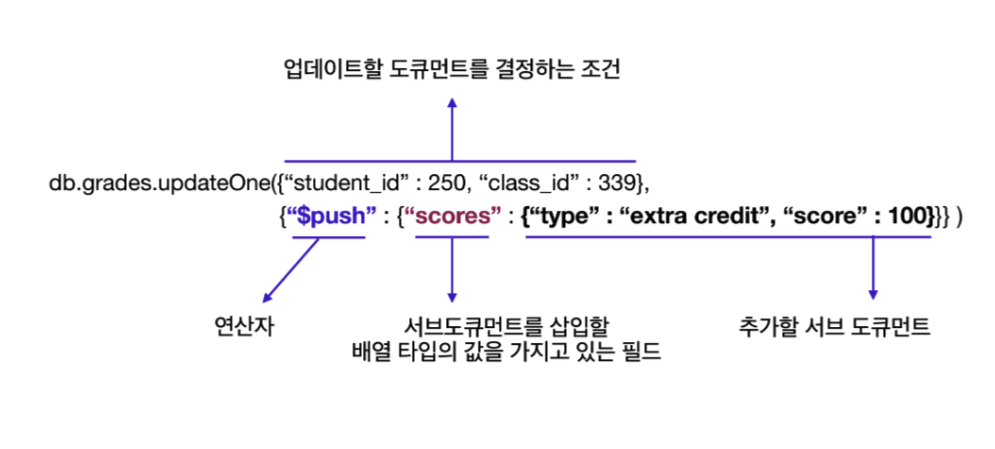
extra credit은 class_id가 339이고, student_id가 250인 학생에게 준다고 가정
업데이트할 도큐먼트를 {“student_id” : 250, “class_id” : 339} 조건으로 지정한다.
{“type” : “extra credit”, “score” : 100} 형태의 서브 도큐먼트를 scores 필드의 값인 배열에 추가해야 하기 때문에,
배열로 이루어진 필드의 값에 해당 서브 도큐먼트를 추가하기 위한 연산자인 $push를 써서 작성한다.
Delete
메타인지
🎯 오늘의 학습목표
- NoSQL의 장점 및 특징에 대해서 이해할 수 있다.
- MongoDB의 도큐먼트(Document)와 컬렉션(Collection)에 대해 이해할 수 있다.
- MongoDB의 Atlas에 대해 이해할 수 있다.
- MongoDB에서 CRUD를 할 수 있다.
😎 학습할 내용 중에 알고 있는 것
noSQL
✏️ 오늘 새롭게 학습한 것
- noSQL중 하나인 MongoDB의 특징과 사용법
🧷 오늘 학습한 내용 중 아직 이해되지 않은 부분
MongoDB의 CRUD를 제대로 이해하지 못했다.
💡 이해되지 않은 내용을 보완하기 위해 무엇을 할까
MongoDB사이트에서 예시를 더 살펴보고 블로깅한 내용을 한번 더 학습한다.
