
Graph
자료구조의 그래프는 마치 거미줄처럼 여러 개의 점과 선으로 이어져 있는 복잡한 네트워크망의 모습을 가지고 있다.
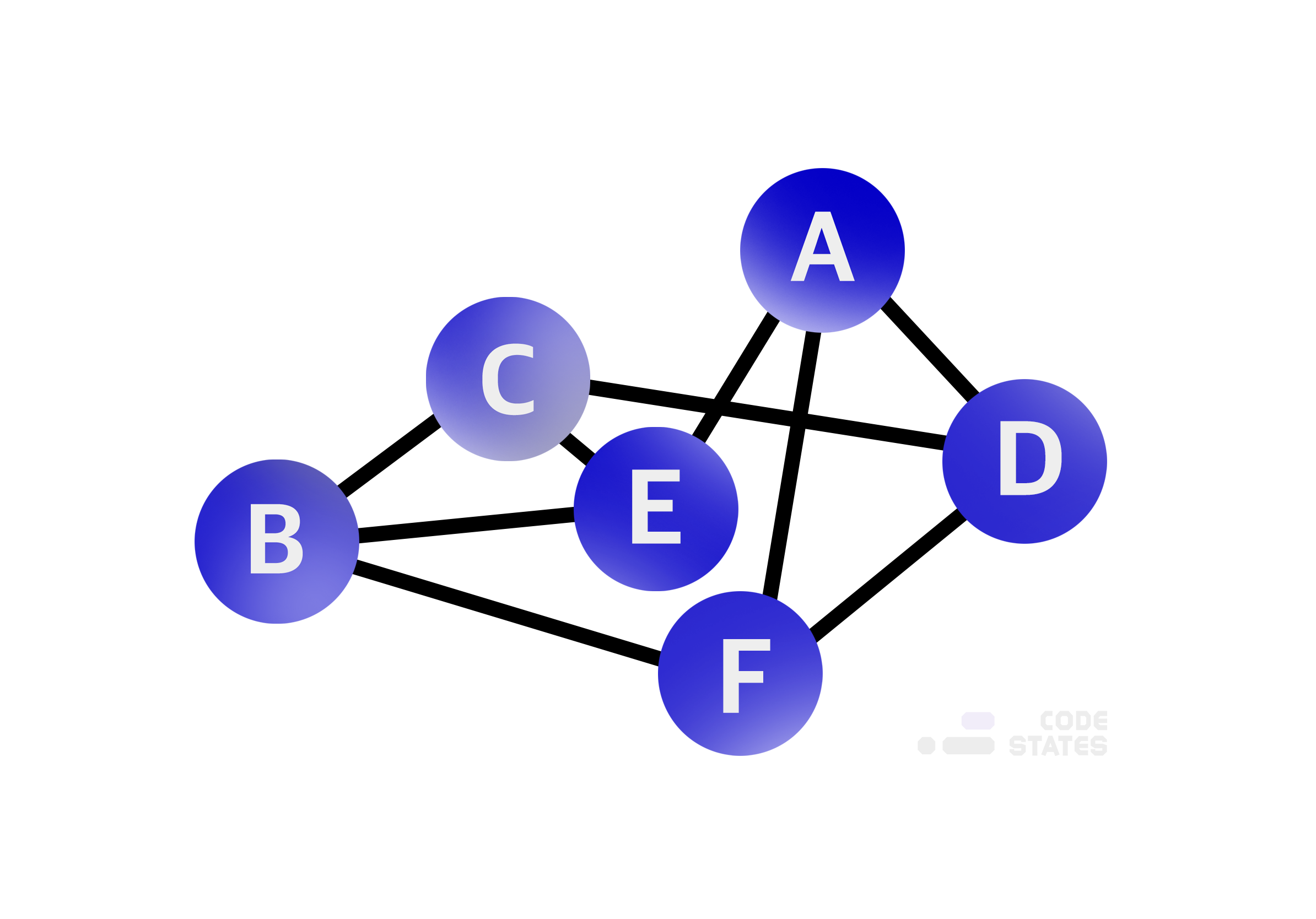
그래프는 관계를 표현한 자료구조이다.
직접적인 관계라면 두 점 사이를 이어주는 선이있다.
간접적인 관계라면 여러개의 점과 선에 걸쳐 이어진다.
그래프에서 점은 정점(vertex)라 하고 선은 간선(edge)라고 한다.
그래프의 실사용 예제
포털사이트의 검색 엔진, SNS 사람들과의 관계, 내비게이션에서 길찾기 등에 사용하는 자료구조가 그래프이다.
서울에 사는 A와 부산에 사는 B, 대전에 사는 C가 있다. 부산에서 열리는 B의 결혼식에 참석하기 위해 A는 차를 몰고 서울에서 출발하여 대전에서 C를 태워 부산으로 이동하고 다시 서울로 올 예정이다.
- 정점: 서울, 대전, 부산
- 간선: 서울-대전, 대전-부산, 부산-서울
정점에 캐나다 벤쿠버를 추가하면?
한국에서 자동차로 벤쿠버로 이동할 수 없기 때문에 어떠한 간선도 추가할 수 없다.
- 정점 벤쿠버: 위 그래프와 관계가 없다.
간선을 살펴보면 서울, 대전, 부산이 서로 관계가 있다는 것은 알 수 있지만, 간선은 특정 도시 두개가 이어져 있다는 사실만 알려주고 그 외의 정보는 포함하지 않고 있다.
추가적인 정보를 파악할 수 없는 그래프, 가중치(Weight, 연결의 강도)가 적혀 있지 않은 그래프를 비가중치 그래프라고 한다.
let isConnected = { '서울': { '대전': true, '부산': true}, '대전': { '서울': true, '부산': true}, '부산': { '서울': true, '대전': true} } console.log(isConnected.서울.대전) // true console.log(isConnected.대전.서울) // true비가중치 무향 그래프로 나타낸 서울, 대전, 부산 그래프
그래프의 표현 방식
인접행렬 (Adjacency Matrix)
두 정점을 바로 이어주는 간선이 있다면 이 두 정점은 인접하다고 한다.
인접행렬은 각각의 정점들이 인접한 상태인지 표시한 행렬로 2차원 배열의 형태로 나타낸다.
비가중치 유향 그래프의 인접행렬
A의 진출차수는 1개A -> C
B의 진출차수는 2개B -> AB -> C
C의 진출차수는 1개C -> A
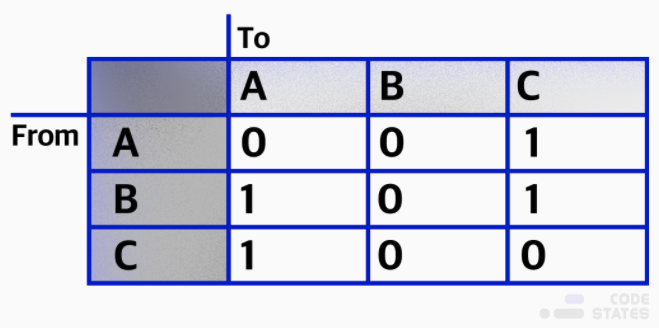
위의 실사용 예제에 대입해보면
유향 가중치 그래프로 바꾸고 각 도시간의 거리를 표시
- 정점: 서울, 대전, 부산
- 간선: 서울 -140km-> 대전, 대전-200km-> 부산, 부산-325km-> 서울
let distanceFromTo = [ // 서울 대전 부산 [0, 140, 0],// 서울 [0, 0, 200],// 대전 [325, 0, 0]// 부산 ] console.log(distanceFromTo[0][1]) // 140 서울->대전 140km console.log(distanceFromTo[1][0]) // 0 대전->서울 안감
인접 행렬이 용이할 때
- 구 정점 사이에 관계가 있는지, 없는지 확인하기 좋다.
- 가장 빠른 경로를 찾을때 주로 사용된다.
인접 리스트 (Adjacency List)
각 정점이 어떤 정점과 인접하는지를 리스트의 형태로 표현한다.
각 정점마다 하나의 인접한 다른 정점을 담고 있는 리스트를 가지고 있다.
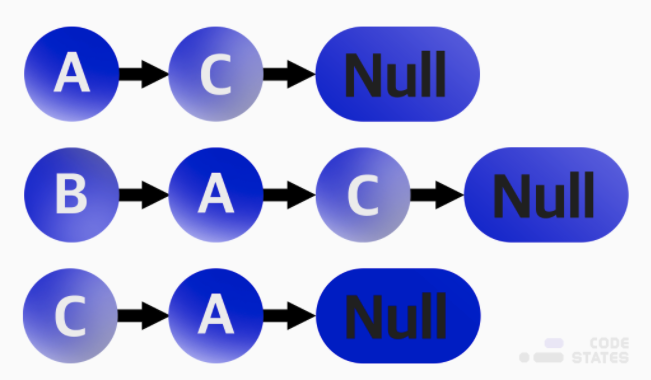
인접리스트안의 정점 순서는 보통은 중요하지 않다. 우선순위를 다뤄야 한다면 더 적합한 자료구조를 사용하는 것이 합리적이다.
인접 리스트가 용이할 때
- 메모리를 효율적으로 사용하고 싶을 때 (인접 행렬은 연결가능한 모든 경우의 수를 저장한다.)
용어정리
정점 (vertex)
- node라고도 하며 데이터가 저장되는 그래프의 기본 원소
간선(edge)
- 정점 간의 관계
인접 (adjacent)
- 두 정점 간에 간선이 직접 연결 되있을 경우 인접한 정점이다.
가중치 그래프 (weighted Graph)
- 연결의 강도가 얼마나 되는지 적혀 있는 그래프
유향 그래프 (directed graph)
- 연결된 정점 간의 방향을 알 수 있는 그래프
진입차수 (in-degree)
- 한 정점에 들어오는 간선이 몇개인지 나타낸다.
진출차수 (out-degree)
- 한 정점을 나가는 간선이 몇개인지 나타낸다.
자기 루프 (self loop)
- 정점에서 진출하는 간선이 곧바로 자기 자신에게 집입하는 경우 자기 루프를 가졌다 한다.
- 다른 정점을 거치지 않는다는 것이 특징이다.
사이클 (cycle)
- 한 정점에서 출발하여 다시 해당 정점으로 돌아갈 수 있으면 사이클이 있다 한다.
Tree
자료구조 Tree는 나무를 거꾸로 뒤집은 형태를 가지고 있다.
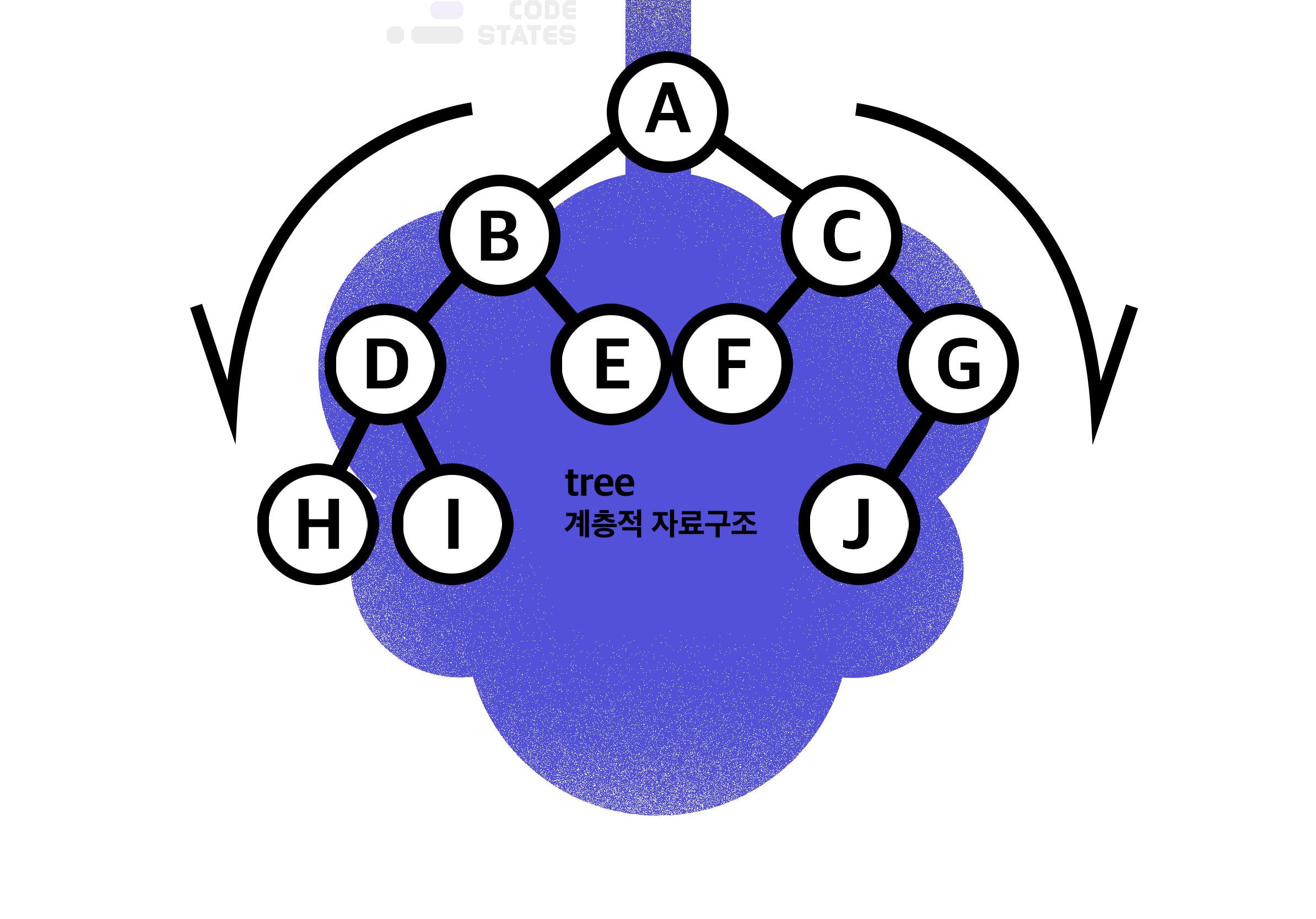
데이터가 바로아래 하나이상의 데이터에 단방향으로 연결된 계층적 자료구조이다.
데이터를 순차적으로 나열시킨 선형 구조가 아니라 하나의 데이터 아래에 여러 개의 데이터가 존재할 수 있는 비선형 구조이다.
아래로만 뻗어나가기 때문에 사이클이 없다.
Root 라는 하나의 데이터를 시작으로 여러개의 데이터를 간선(edge)로 연결한다.
각 데이터를 노드(node) 두개의 노드가 연결되면 부모/자식 관계를 가진다.
자식이 없는 노드는 Leaf Node라 부른다.
측정
깊이 (depth)
루트로부터 특정 노드까지의 깊이를 표현할 수 있다.
루트 노드는 깊이가 0 이다.
레벨 (level)
깊이가 같은 노드를 묶어서 레벨로 표현할 수 있다.
같은 레벨에 있는 노드를 형제 노드(sibling node)라고 한다.
높이 (height)
리프 노드를 기준으로 루트 노드까지의 높이를 표현할 수 있다.
리프 노드는 높이가 0 이다.
서브 트리 (sub tree)
root에서 뻗어 나오는 큰 트리 내부에 트리 구조를 갖춘 작은 트리
실사용 예제
컴퓨터의 디렉토리 구조도 트리 구조라 할 수있다.
모든 폴더는 root폴더(/)에서 시작된다.
이 밖에 대진표, 가계도, 조직도 등도 트리 구조라 할 수 있다.
용어정리
노드 (node)
- 트리 구조를 이루는 모든 개별 데이터
루트 (root)
- 트리 구조의 시작점이 되는 노드
부모 노드 (perent node)
- 두 노드가 상하관계로 연결되어 있을때 루트에 가까운 노드
자식 노드 (child node)
- 두 노드가 상하관계로 연결되어 있을때 루트에 먼 노드
형제 노드(sibling node)
- 같은 레벨에 있는 노드
리프 (leaf)
- 자식 노드가 없는 노드
이진 트리 (binary tree)
자식 노드가 최대 두개인 노드들로 구성된 트리를 이진 트리라 한다.
트리 구조는 효율적인 탐색을 위해 사용하기도 한다.
트리 구조는 가지고 있는 특징에 따라 여러 가지 이름으로 불린다.
가장 간단하고 많이 사용하는 구조로 이진 트리와 이진 탐색 트리가 있다.
자료 삽입, 삭제 방법에 따라 아래와 같이 나뉜다.
정 이진 트리 (full binary tree)
자식 노드가 없거나 2개의 자식노드를 가진 트리완전 이진 트리 (complete binary tree)
마지막 레벨을 제외하고 모든 노드가 2개의 자식노드를 가진 트리
마지막 레벨의 노드는 양쪽이 있지 않아도 되지만 왼쪽은 있어야 한다.포화 이진 트리 (perfect binary tree)
정 이진 트리이면서 완전 이진 트리인 경우이다.
마지막 레벨을 제외하고 모두 2개의 자식노드를 가진 트리
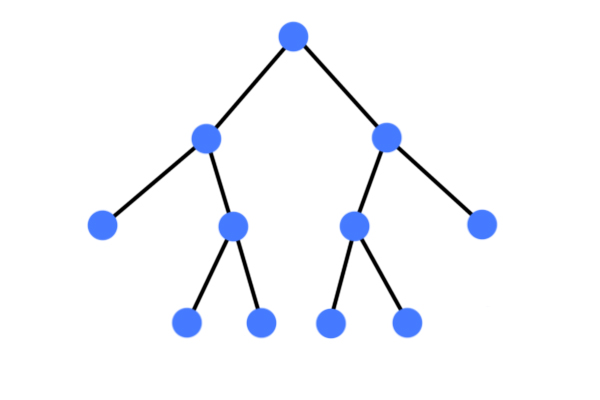
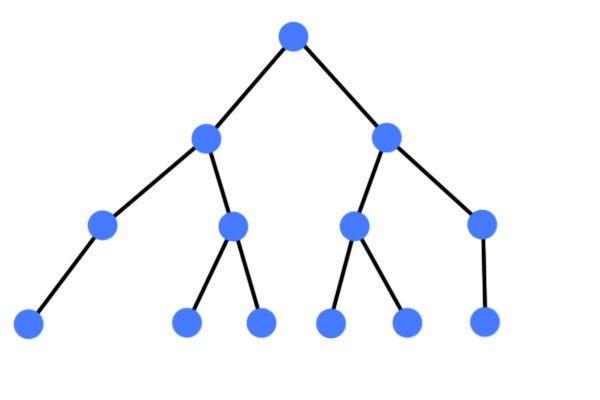
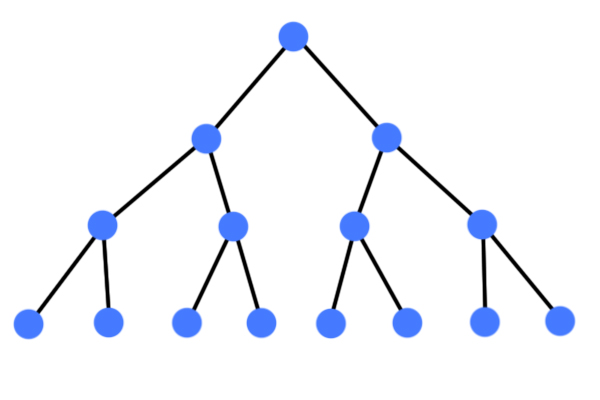
이진 탐색 트리 (Binary Search Tree)
이진 탐색 트리는 모든 왼쪽 자식의 값이 루트나 부모보다 작고, 모든 오른쪽 자식의 값이 루트나 부모보다 큰 값을 가지는 특징이 있다.
이진 탐색 트리가 균형 잡힌 트리가 아닐때 입력되는 값의 순서에 따라 한쪽으로 노드들이 몰리게 될 수 있다. 이러한 경우 탐색하는 데 시간이 더 걸려는 경우가 있기 때문에 해결해야 할 문제이다.
삽입과 삭제마다 트리의 구조를 재조정하는 알고리즘을 추가하는 등으로 해결할 수 있다.
