원문: https://www.w3.org/TR/1998/WD-DOM-19980720/introduction.html
DOM(문서 객체 모델)이란 무엇인가?
개요
문서 객체 모델(Document Object Model, DOM)은 HTML과 XML 문서를 위한 프로그래밍 API입니다. 문서의 논리적인 구조를 정의하고 문서가 접근되고 조작되는 방식입니다. DOM 명세에서 "문서(documents)"라는 용어는 넓은 의미로 사용됩니다. XML은 점점 더 다양한 시스템에 저장될 수 있는 다양한 종류의 정보를 표현하는 방법으로 사용되고 있습니다. 이러한 정보들은 대부분 문서가 아닌 데이터로 간주됩니다. 그럼에도 불구하고 XML은 이러한 데이터를 문서로 표현하며 DOM을 이용해 데이터를 관리할 수 있습니다.
DOM을 이용하여 프로그래머는 문서를 생성하고 구축할 수 있으며 문서의 구조를 탐색하고 요소나 콘텐트를 추가, 수정, 제거할 수도 있습니다. HTML, XML 문서에 있는 모든 것들은 DOM을 통해 접근 가능하며, 변경될 수 있고, 더해지거나 제거될 수도 있습니다. 내부 하위 집합과 외부 하위 집합에 대한 DOM 인터페이스가 명세되지 않은 몇 가지 예외사항은 제외됩니다.
W3C 명세로서 DOM의 중요한 목표 중 하나는 다양한 환경과 애플리케이션에서 사용할 수 있는 표준 프로그래밍 인터페이스를 제공하는 것입니다. DOM은 어떠한 프로그래밍 언어라도 사용할 수 있습니다. DOM 인터페이스의 정확하고 언어 종속적인 명세를 제공하기 위해 CORBA 2.2 명세에서도 정의된 OMG IDL로 명세를 정의했습니다. 우리는 Java와 ECMAScript(자바스크립트와 JScript를 기반으로 하는 업계 표준 스크립트 언어)에 대한 언어 바인딩을 제공합니다.
참고: OMG IDL은 언어에 독립적이며 구현 중립적인 인터페이스 명세 방법으로만 사용됩니다. 다른 여러 IDL을 사용할 수 있으며 OMG IDL을 사용한다고 해서 특정 객체 바인딩 런타임을 사용해야 한다는 것은 아닙니다.
그래서 DOM은
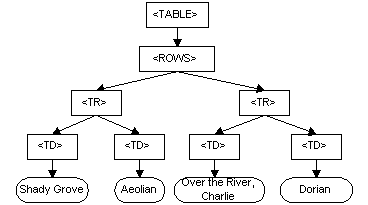
DOM은 문서에 대한 프로그래밍 API입니다. 객체 모델 자체는 모델링하는 문서의 구조와 아주 유사합니다. HTML 문서의 표에 대한 예제를 보여드리겠습니다.
<TABLE>
<ROWS>
<TR>
<TD>Shady Grove</TD>
<TD>Aeolian</TD>
</TR>
<TR>
<TD>Over the River, Charlie</TD>
<TD>Dorian</TD>
</TR>
</ROWS>
</TABLE>DOM은 이 표를 아래 그림처럼 표현합니다.
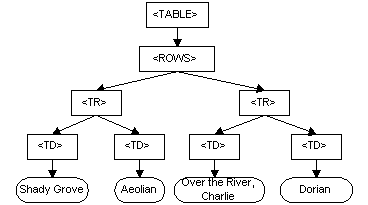
DOM에서 문서는 트리와 매우 유사한 논리적인 구조를 가지고 있습니다. 좀 더 정확하게 말하자면 하나의 트리 이상을 포함할 수 있는 "숲(forest)"이나 "그로브(grove)"와 같습니다. 그러나 DOM은 문서가 트리나 그로브로 구현된다고 명시하고 있지 않습니다. 또한 객체들 사이 관계가 어떠한 방식으로 구현되는지도 명시하고 있지 않습니다. 즉, 객체 모델은 프로그래밍 인터페이스를 위한 논리 모델을 지정하며 논리 모델은 편리한 방식으로 구현될 수 있음을 의미합니다. 이 명세에서는 문서의 트리와 같은 표현을 설명하기 위해 구조 모델(structure model) 이라는 용어를 사용합니다. 특정한 구현 방법을 내포하지 않도록 "트리" 또는 "그로브"와 같은 용어는 지양합니다. DOM 구조 모델의 중요한 속성 중 하나는 구조적 동형성(structural isomorphism) 입니다. 동일한 문서를 표현하는 데 두 개의 DOM 구현이 사용되는 경우, 두 DOM 구현은 동일한 객체와 관계를 가지는 동일한 구조 모델을 생성합니다.
"DOM"이라는 이름은 전통적인 객체 지향 디자인의 의미에서 사용되는 "객체 모델"이므로 가지게 되었습니다. 문서는 객체를 사용하여 모델링되고, 이 모델은 문서의 구조뿐 아니라 문서의 동작과 문서가 구성되는 객체를 포함합니다. 즉, 위의 다이어그램에서 노드들은 데이터 구조를 나타내는 것이 아니라 함수와 아이덴티티를 가진 객체를 나타냅니다. 객체 모델로서, DOM은 다음을 구분합니다.
- 문서를 표현하고 조작하기 위해 사용되는 인터페이스와 객체
- 동작과 속성을 모두 포함하는 인터페이스와 객체의 의미론
- 인터페이스와 객체 간의 관계와 협업
SGML 문서의 구조는 전통적으로 객체 모델이 아닌 추상적인 데이터 모델로 표현되었습니다. 추상적인 데이터 모델에서, 모델은 데이터를 중심으로 이루어집니다. 객체 지향 프로그래밍 언어에서 데이터 자체는 데이터를 숨기는 객체에 의해 캡슐화되어 직접적으로 외부에서 조작하는 것으로부터 보호됩니다. 이러한 객체들과 연관된 함수들은 객체를 조잘할 수 있는 방법을 결정하며 객체 모델의 일부이기도 합니다.
현재의 DOM은 DOM 코어와 DOM HTML로 이루어져 있습니다. DOM 코어는 XML 문서를 위한 기능을 나타내며 DOM HTML의 기반이 됩니다. 모든 DOM 구현은 코어 명세의 "기본 원칙"으로 나열된 인터페이스를 반드시 지원해야 합니다. 또한 XML 구현은 코어 사양에서 "확장"으로 나열된 인터페이스를 지원해야 합니다. 레벨 1 DOM HTML 사양은 HTML 문서에 필요한 추가적인 기능을 정의합니다.
DOM이 아닌 것은
이 섹션은 DOM과 다른 유사한 시스템과 구분하여 보다 정확하게 DOM을 이해할 수 있도록 설계되었습니다.
- DOM이 동적인 HTML에 큰 영향을 받았을지라도 레벨 1에서 DOM은 동적인 HTML의 모든 것을 구현하지 않습니다. 특히 이벤트는 아직 정의되지 않았습니다. 레벨 1은 문서 자체의 강력하고 유연한 모델을 제공함으로써 이러한 종류의 기능에 대한 확고한 기반을 마련하도록 설계되었습니다.
- DOM은 바이너리 사양이 아닙니다.동일한 언어로 작성된 DOM 프로그램은 플랫폼 간 소스코드 호환이 가능하지만, DOM은 어떤 형태의 바이너리 상호 운용성도 정의하지 않습니다.
DOM은 어디에서 왔는가
DOM은 자바스크립트로 된 스크립트와 자바 프로그램을 웹 브라우저에서 사용할 수 있도록 만드는 명세로서 시작되었습니다. 동적인 HTML은 DOM의 직계 조상으로 원래는 주로 브라우저의 관점에서 생각됐습니다. 그러나 DOM 작업 조직이 결성됐을 때 HTML 또는 XML 편집기, 문서 저장소 등 다른 도메인의 벤더도 참여했습니다. 이러한 벤더들은 XML이 개발되기 전에 이미 SGML로 작업하고 있었기 때문에 DOM도 SGML 글로브와 HyTime 표준에 영향을 받게 되었습니다. 그리고 SGML/XML 편집기나 문서 저장소에 대한 프로그래밍 API를 제공하기 위해 문서에 대한 객체 모델을 이미 자체적으로 갖고 있는 벤더들도 있었는데, 그들이 가지고 있는 객체 모델들 또한 DOM에 영향을 주었습니다.
엔터티와 DOM 코어
기본 DOM 인터페이스에는 엔터티를 표현하는 객체는 없습니다. 숫자 문자 참조와 HTML 및 XML에서 미리 정의된 엔터티에 대한 참조는 엔터티의 대체를 구성하는 단일 문자로 대체됩니다. 예를 들어 다음과 같습니다.
<p>This is a dog & a cat</p>"&"는 문자 "&"로 대체되며, <p> 요소 내의 텍스트는 하나의 연속적된 문자 시퀀스를 형성합니다. 내부/외부 모두에서 일반적인 엔터티의 표현은 레벨 1의 연장된 (XML) 인터페이스 내에서 정의됩니다. 참고: 문서의 DOM 표현이 XML이나 HTML 텍스트로 직렬화될 때, 어플리케이션은 텍스트 데이터의 각 문자를 확인하여 숫자 또는 사전 정의된 엔터티를 사용하여 이스케이프해야 하는 확인해야 합니다. 그렇지 않으면 유효하지 않은 HTML 또는 XML이 발생할 수 있습니다.
DOM 인터페이스와 DOM 구현
DOM은 XML 및 HTML 문서를 관리하기 위해 사용될 수 있는 인터페이스를 지정합니다. 이러한 인터페이스는 C++의 "추상 베이스 클래스"와 마찬가지로 애플리케이션 내부 문서에 접근하고 조작하는 방법을 지정하는 수단으로서의 추상화인 점을 인식하는 것이 중요합니다. 특히 인터페이스는 특정하게 정해진 구현을 암시하지 않습니다. 명세에 표시된 인터페이스가 지원된다면 각 DOM 애플리케이션은 문서를 편리한 방법으로 자유롭게 유지보수할 수 있습니다. 일부 DOM 구현은 DOM 명세가 존재하기 전에 작성된 소프트웨어에 접근하기 위해 DOM 인터페이스를 사용하는 프로그램일 수도 있습니다. 따라서 DOM은 구현 종속성을 피하도록 설계되었습니다.
- IDL에서 정의된 속성은 특정 데이터 멤버를 가져야 하는 구체적인 객체를 의미하지 않습니다. 언어 바인딩에서는 데이터 멤버가 아닌 한 쌍의 get()/set() 함수로 변환됩니다. (읽기 전용 함수는 언어 바인딩에 get() 함수만 가집니다.)
- DOM 애플리케이션은 이 명세에 없는 추가적인 인터페이스와 객체를 제공할 수도 있으며, 여전히 DOM 규칙을 준수하는 것으로 간주됩니다.
- 생성되는 실제 객체가 아닌 인터페이스를 명세하는 것이므로, DOM은 구현을 위해 어떤 생성자를 호출할지 알 수 없습니다. 일반적으로 DOM 사용자는 Document 클래스의 createXXX() 메서드를 호출하여 문서 구조를 생성하며, DOM 구현은 createXXXX() 함수의 구현에서 이러한 구조의 내부적인 표현을 자체적으로 생성합니다.
레벨 1의 한계
DOM 레벨 1 명세는 의도적으로 문서 구조와 컨텐츠를 표현하고 조작하는 데 필요한 메서드로만 제한되어 있습니다. 향후 DOM 명세의 레벨 2에서는 더 많은 메서드가 제공됩니다.
- 내부 하위집합과 외부 하위집합을 위한 구조적 모델
- 스키마에 대한 유효성 검증
- 스타일시트를 통한 문서 렌더링 제어
- 접근 제어
- 스레드 안전성
