- IN 사용하기
SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES FROM REST_INFO
where FAVORITES in (select max(favorites) from rest_info
group by food_type)
group by FOOD_TYPE order by FOOD_TYPE desc음식종류별로 즐겨찾기수가 가장 많은 식당의 음식 종류, ID, 식당 이름, 즐겨찾기수를 조회하려고 하면,
내림차순으로 정렬해서 끊을 수 없으므로 LIMIT를 활용하여 풀 수는 없다.
이럴 땐 IN의 대상값에 서브쿼리를 이용하여 가상의 테이블을 만듬으로서, 즐겨찾기 최댓값과 일치하는 항목을 구할 수 있다.
?추가과제? 단 이 경우 A카테고리의 즐겨찾기 최댓값과 동일한 값을 가진 B카테고리의 항목이 있다면 IN에 같이 걸려서 결과 조회가 제대로 안되지 않을까?
- Rank 사용하기
SELECT
FOOD_TYPE,
REST_ID,
REST_NAME,
FAVORITES
FROM
(SELECT
FOOD_TYPE,
REST_ID,
REST_NAME,
FAVORITES,
RANK() OVER (PARTITION BY FOOD_TYPE ORDER BY FAVORITES DESC) as R
FROM REST_INFO
) AS a
WHERE R = 1
ORDER BY FOOD_TYPE DESCSELECT하는 테이블 자체에 RANK 값을 추가해서 RANK=1 인 값만 불러오기한다.
이런식으로 SELECT 하는 테이블 자체를 새로 만들때는 테이블에 AS로 새 이름을 붙여줘야 돌아간다.
이게 1번 방식보다 정확할 것 같다.
- RANK
각 카테고리 내의 값의 순위를 구하는 함수이다.
중복값이 있을 경우 동일 순위로 표시한다.
RANK() OVER (PARTITION BY 카테고리명 ORDER BY 값명 DESC)
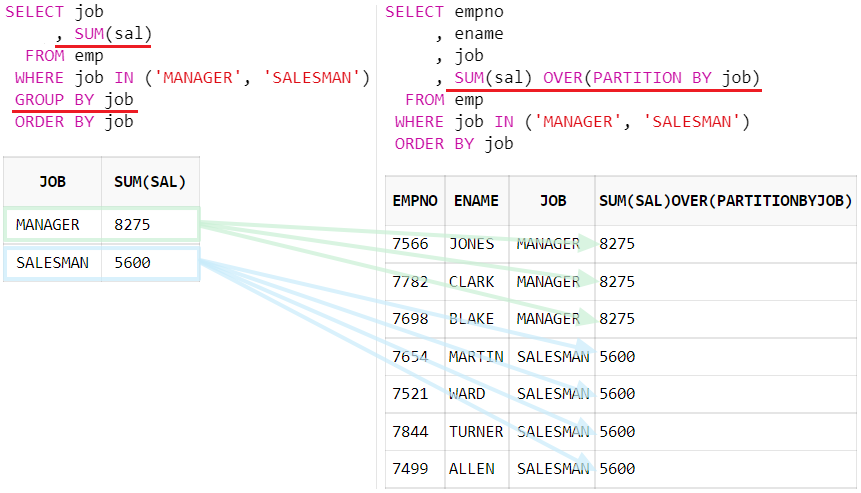
PARTITION BY
이때, PARTITION BY 는 분석함수를 이용할때 그룹으로 묶어서 연산하기 위한 연산자이다. 분석함수값을 마치 group by처럼 그룹끼리 묶어서 계산해준다.
GROUP BY 와 동일한 값을 가지나, 계산 순서가 다르므로 WHERE절의 대상이 될 수 있다.

공부하는 것들을 적는 블로그.