논문: PageRank
등장 배경
초기 검색 엔진에는 한계점이 몇가지 존재했는데, 키워드 기반이라 너무 단순했다는 점, 메타태그의 활용은 조작(블로글 따지면 검색 순위권에 들기 위해 관련 없는 많은 태그를 붙이는 행위)의 문제가 있다는 점이 대표적이다.
이런 배경에서 더 나은 검색엔진을 위해 고안된 방법이 PageRank.
원리
원리는 다음과 같다. (1) 웹의 링크 구조를 활용해 웹페이지 간의 하이퍼링크를 '인용(=citation)'으로 간주하였다. 이를 통해 페이지의 중요도를 객관적으로 평가한다. (2) 여기에 각 웹페이지를 노드, citation을 간선으로 하여 그래프 이론을 적용한다!
학술계에서 중요 논문은 그만큼 더 많이 인용된다는 것에서 아이디어를 얻었다고 한다. 그런 아이디어를 그래프이론 +선형대수학을 활용해 수학적으로 모델링 한 것이 참 재밌었음. 웹을 하나의 거대 그래프로 본 거다. 그 그래프를 다시 행렬로 모델링 해 중요도 계산에 활용한 거고.
(90년대의 논문이라 가능했지만 지금 이 방법을 쓰면 컴퓨터 터질 듯)
작동 방식
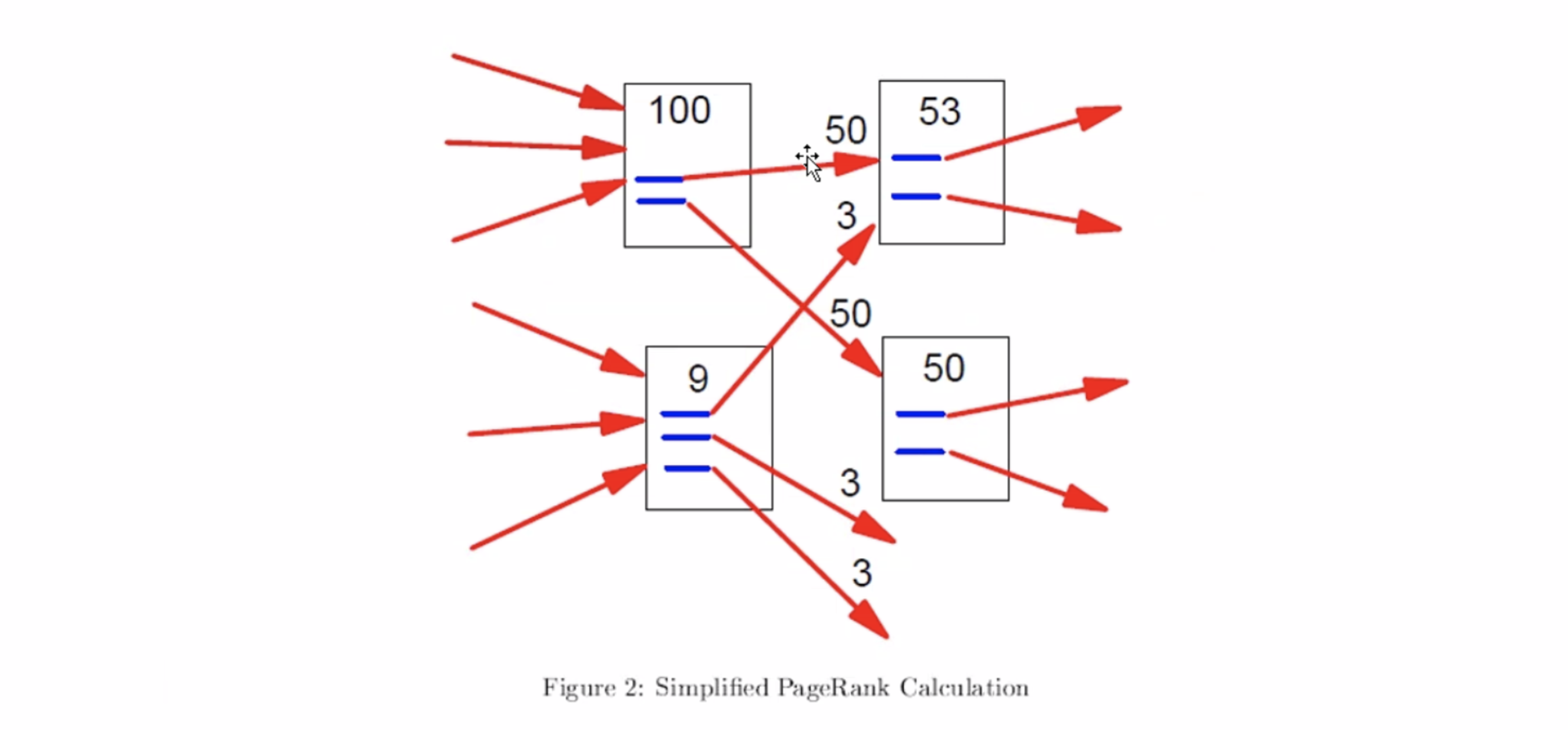
그래프를 행렬로 나타내고 행렬곱을 반복함에 따라 각 페이지의 벡터가 특정 값으로 수렴한다. 이에 따라 가장 많이 인용된 페이지가 높은 랭킹을 차지하게 되며, 이 페이지가 인용한 다른 페이지들도 가중치를 부여받아 상위 랭킹에 오를 수 있게 된다. 여기서 중요한 점은 단순히 인용된 횟수만이 아니라, 인용한 페이지 자체의 중요성도 랭킹에 반영된다는 것
시사점
현대의 거대한 웹 생태계에선 PageRank만으로는 역부족이다. 그래도 당시로서는 키워드/메타태그 등의 정적인 방법에서 나아가 웹의 링크 구조 반영한 혁신적인 방식이었겠지. 구식 기술이긴 하지만 시사점은 분명하다. 또 추천 시스템과 유사하게 느껴지기도 했다. 검색도 웹페이지를 추천한다고 보면 넓은 의미로 추천시스템이겠구나- 싶었다.
•
•
•
- 기록하고 싶은 오늘의 피어세션🥳 -
너무 뿌듯하고 알찼던 두번째주의 첫 피어세션!
첫 주에 겪은 시행착오에 대해 문제의식을 갖고 팀원 모두가 해결책을 고민하고 의견을 나눴기에 있을 수 있는 결과라고 생각한다.
아무래도 첫주다 보니 적응도 해야하고, 별도의 이벤트도 많았기에 정신없는 한 주를 보냈다. 모더레이터가 나였기에 나름대로 이끌어보려고 했지만 원하는만큼 매끄럽게 흘러가지 않았다.
'우왕좌왕하는 게 다음주까지 계속되면 절대 안된다!'라는 생각에 팀 회고 시간에 이것저것 제안했다. 코테조3명/논문조3명으로 나누자, 하루에 코테조1명과 논문조1명이 발표하자..대충 그런 내용이었다. 고맙게도 팀원들이 나의 제안을 긍정적으로 생각해줘서 이번주 피어세션부터 새로운 피어세션 계획을 실천하게 되었다.
결과는 성공!🎉 논문담당 팀원이 소개한 PageRank논문의 내용이 굉장히 흥미로웠다. 코테담당 팀원이 풀이한 백준 문제를 푸는 방법에 대해 팀원끼리 얘기도 많이 나누었다. 그 과정에서 나 홀로 고민해서는 떠올리지 못했을 다른 사람들의 풀이를 보며 많은 점을 배울 수 있었다. (역시 집단지성은 소중해-)
