Text Mining
Text data mining
- Sentiment analysis
- Document summarization
- News recommendation
- Text analytics in financial services
- Text analytics in healthcare
How to perform text mining?
- As computer scientists, we view it as
- Text Mining = Data Mining + Text Data
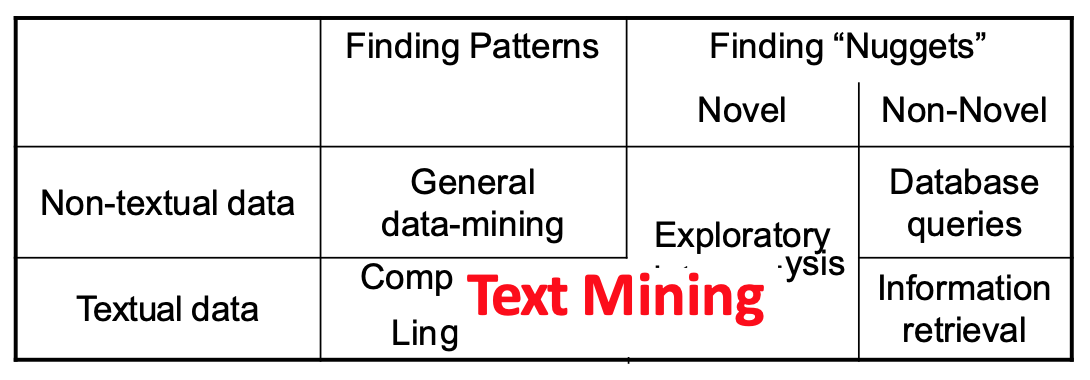
Text mining vs NLP,IR,DM...
- How does it relate to data mining in general?
- How does it relate to computational linguistics?
- How does it relate to information retrieval?
Text mining in general
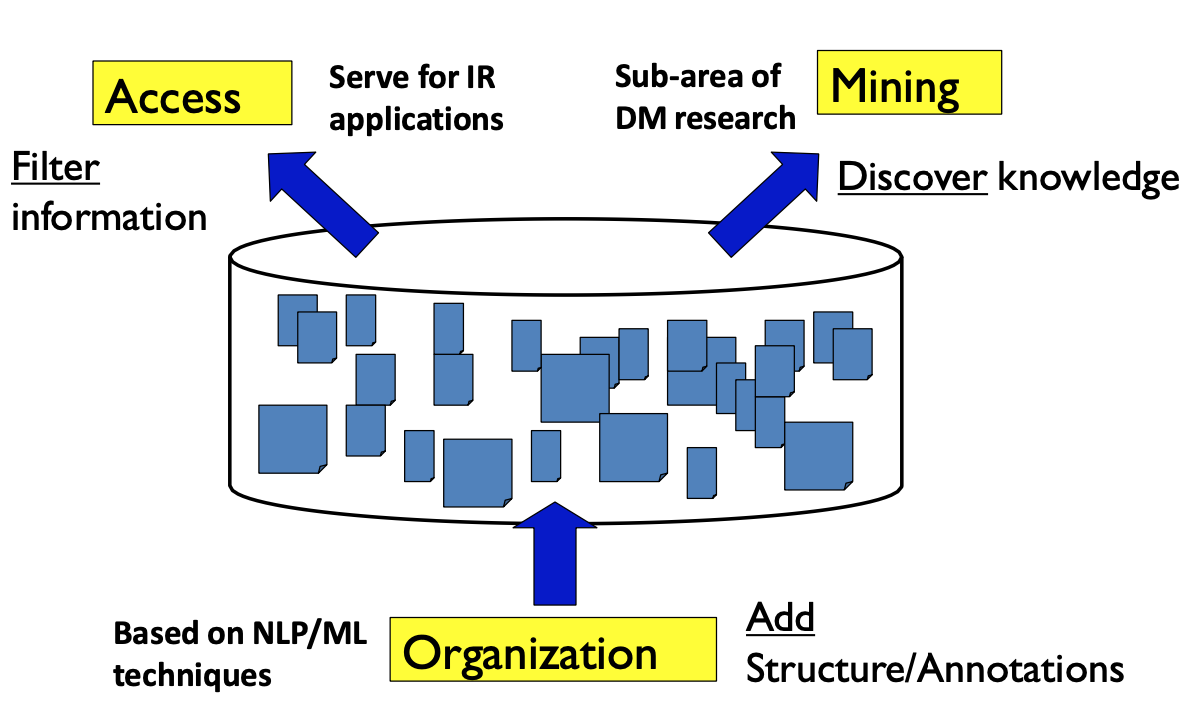
- Using machine learning text data transfer to Organization
Challenges in text mining
- Data collection is "free text"
- Data is not well-organized
- Semi-structured or unstructured
- Natural language text contains ambiguities on many levels
- Lexical, syntactic, semantic, and pragmatic
- Learning techniques for processing text typically need annotated training examples
- Expensive to acquire at scale
- Data is not well-organized
- What to mine?
Challenges in text minig(cont'd)
- Huge in size
- 80% data is unstructured (IBM,2010)
Scalability is crucial
- Large scale text processing techniques
- MapReduce framework
State-of-the-art solutions
- Apache Spark (spark.apache.org)
- In-memory MapReduce
- Speciallized for machine learning algorithms
- Speed
- 100x faster than Hadoop MapReduce in memory, or 10x faster on disk
- Genenral
- Combine SQL, streaming, and complex analytics
- In-memory MapReduce
Document Representation
How to represent a document
- Represent by a string?
- No semantic meaning
- Represent by a list of sentences?
- Sentence is just like a short document (recursive definiton)
Can't
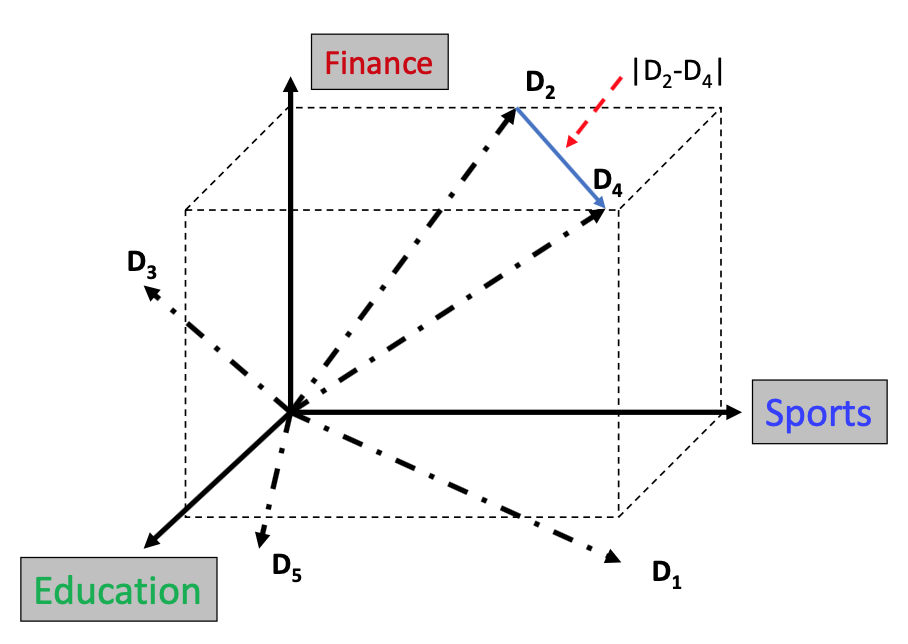
Vector Space (VS) model
- Represent documents by concept vectors
- Each concept defines one dimension
- k concepts define a high-dimenstional space
- Element of vector corresponds to concept weight
- Distance between the vectors in this concept space
- Relationship among documents
Can calculate distance among of vectors
An illustration of VS model
- All documents are projected into this concept space
What the VS model doesn't say
- How to define/select the "basic concept"
- Concepts are assumed to be orthogonal
- How to assign weights
- Weights indicate how well the concept characterizes the document
- How to define the distance metric
컨셉간 거리가 직교해야한다. 유사성이 존재해서는 안된다 축이 흔들려서는 안된다.
What is a good "Basic Concept"?
-
Orthogonal
-
Weights should be assigned automatically and accurately?
-
Exisiting solutions
- Terms of N-grams,aka..., Bag-of-Words
- Topics
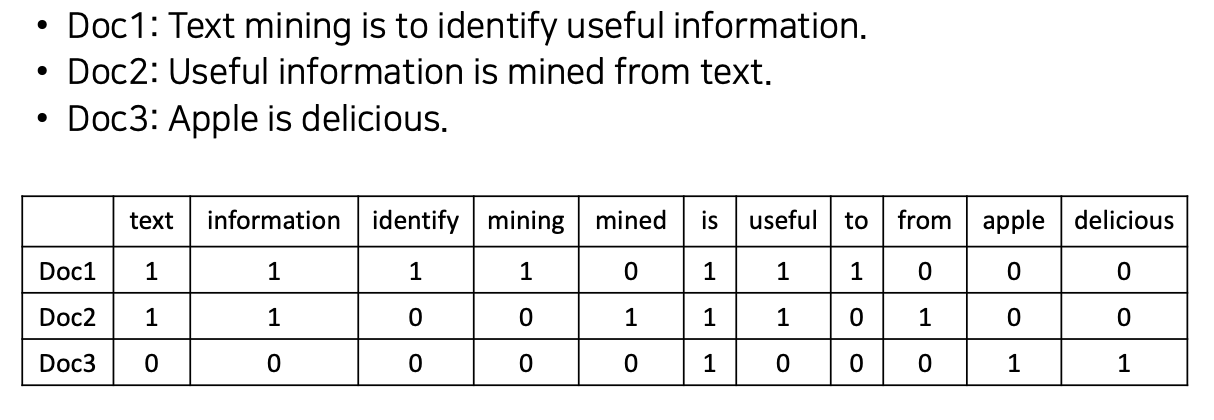
Bag-of-Words representaion
단어 하나를 컨셉으로 본다.
- Term as the basis for vector space
Tokenization
-
Break a stream of text into meaningful units
-
Tokens : words, phrases, symbols

-
Definiion depends on language, corpus, or even context
-
-
Solutions

Back-of-Words with N-grams
Back-of-Words를 개선하기 위해 N-grams 도입
- N-grams: a contiguous sequence of N tokens from a given piece of text
- Pros: capture local dependency and order
- Cons: a purely statistical view, incease the vocabulary size O(V^N)
Automatic document representation
- Represent a document with all occurring words
- Pros
- Preserve all information in the text
- Fully automatic
- Cons
- Vocalbulary gap : cars versus car, talk versus talking
- Large storage : N-grams needsO(V^N)
- Solution
- Construct controlled vocabulary
- Pros
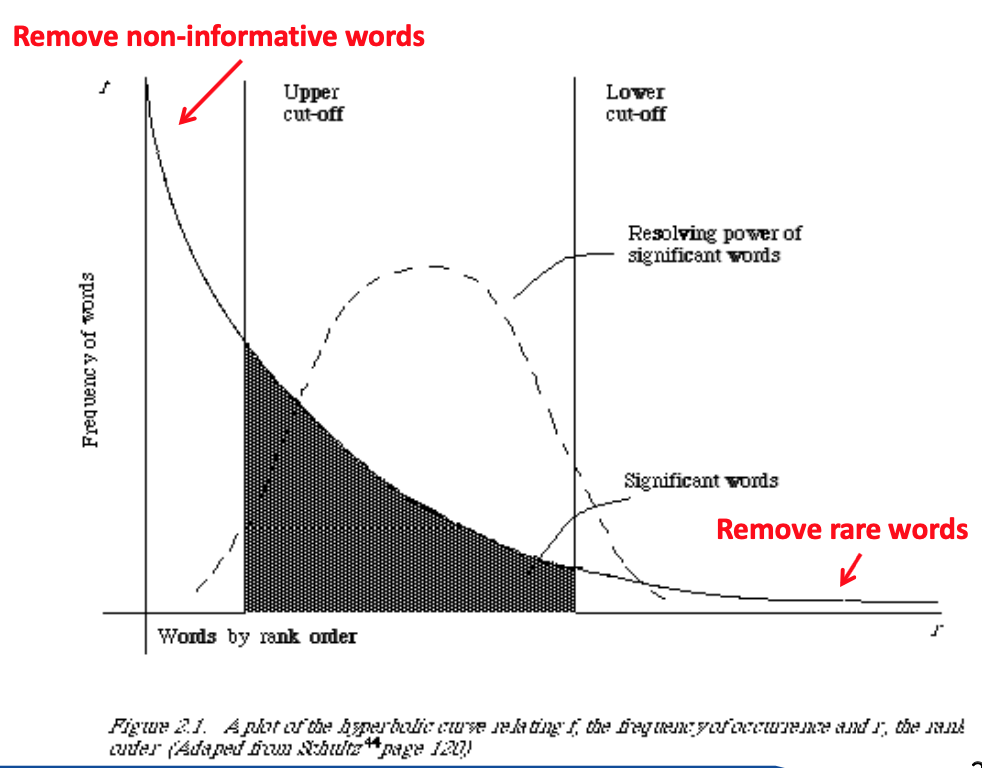
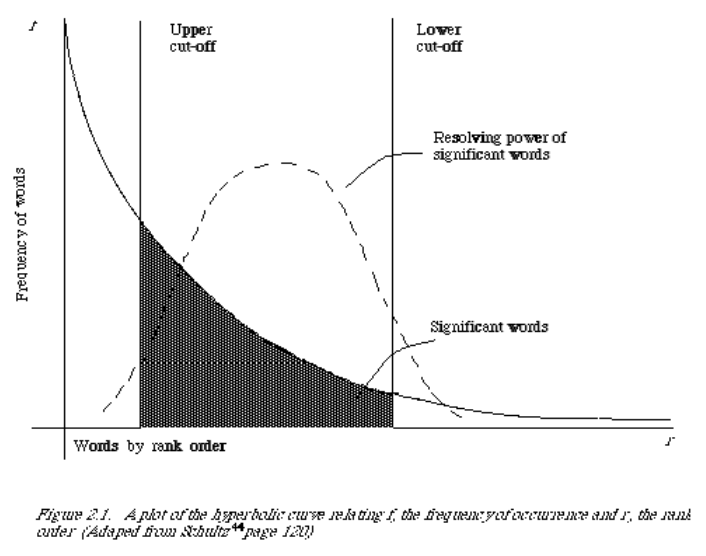
A statistical property of language
- Zipf's law
- Frequency of any word is inversely proportional to its rank in the frequency table

- Frequency of any word is inversely proportional to its rank in the frequency table
Zipf's law tells us
수천만개중에 적게 나오는 단어, 의미 없는 말들 (관형사) 등이 의미가 있는가
- Head words take large portion of occurrences, but they are semantically meaningless
- Ex) the, a, an, we, do, to
- Tail words take major portion of vocabulary, but they rarely occur in documents
- The rest is most representative
- To be included in the conrolled vocabulary
Stopwords
- Useless words for documents analysis

Normalization
-
Convert different forms of a word to a normalized form in the vocabulary
-
Solution
- Rule-based
- Delete periods and hyphens
- All in lower case
- Dictionary-based
- Contruct equivalent class
- Car -> "automobile, vehicle"
- Mobile phone -> "cellphone"
- Contruct equivalent class
- Rule-based
Stemming
- Reduce inflected or derived words to their root form

Constructing a VSM reresentation

3,4 번의 순서가 바뀌면 안된다. (자르는 단계에서 불용어를 먼저 삭제할 경우 묶는 순서 쌍이 바뀔 수 있다.)
How to assign weights?
- Important!
- Why?
- Corpus-wise : some terms carry more information about the document content
- Document-wise : not all terms are equally important
- How?
- Two basic heuristics
- TF (Term Frequency) = Within-doc-frequency
- IDF (Inverse Document Frequency)
- Two basic heuristics
Term frequency
- Idea : a term is more important if it occurs more frequently in a document
- TF Formulas

TF normalization
-
Two views of document length
- A doc is long because it is verbose
- A doc is long because it has more content
-
Raw TF is inaccurate
- Document length variation
- "Repeated occurrences" are less informative than the "first occurrence"
- Information about semantic does not increase proporyionally with number of term occurrence
-
Generally penalize long document, but avoid over-penalizing
-
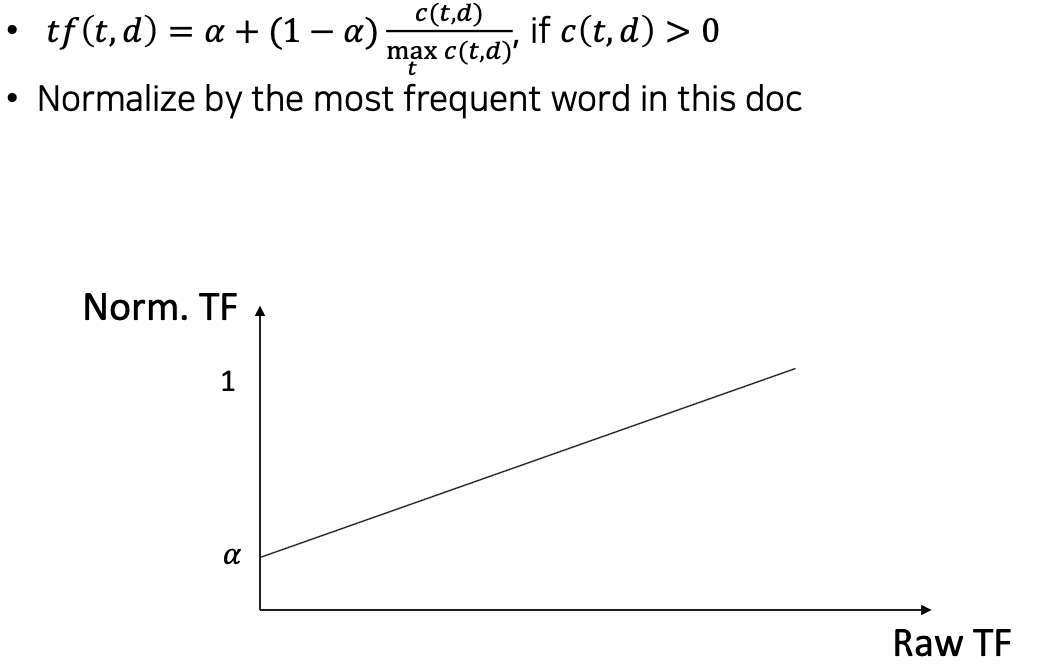
Maximum TF scaling
-
Sub-linear TF scaling
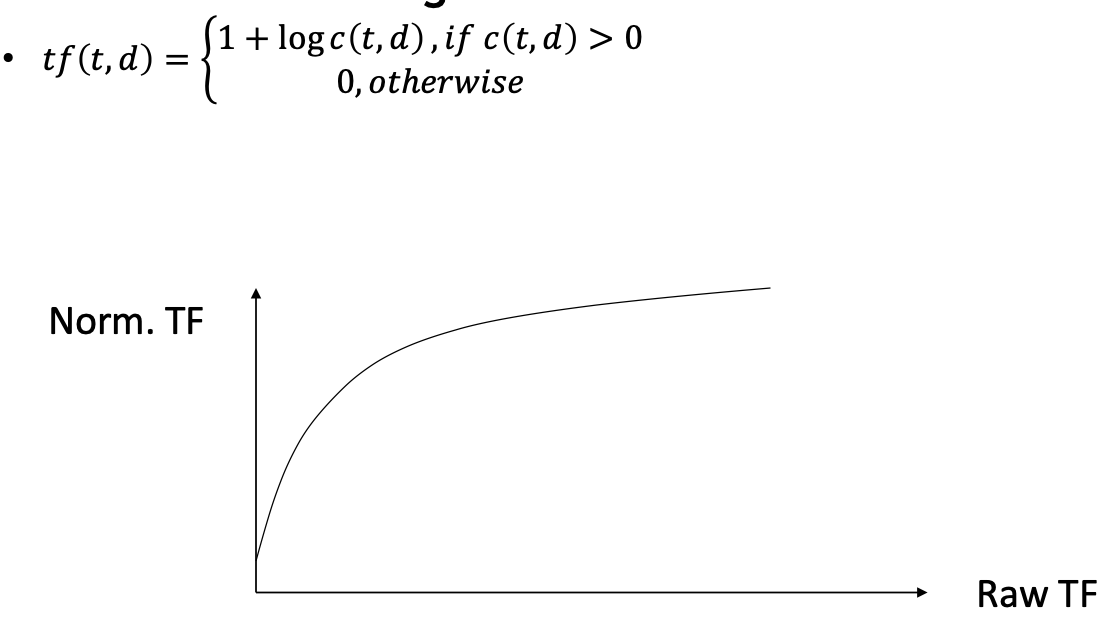
사용 빈도가 어느 특정 이상일 경우 아무리 많아도 의미가 없다 로그 형태의 그래프
Document frequency
- Idea : a term is more discriminative if it occurs only infrewer documents
역으로
Inverse document frequency (IDF)
- Solution
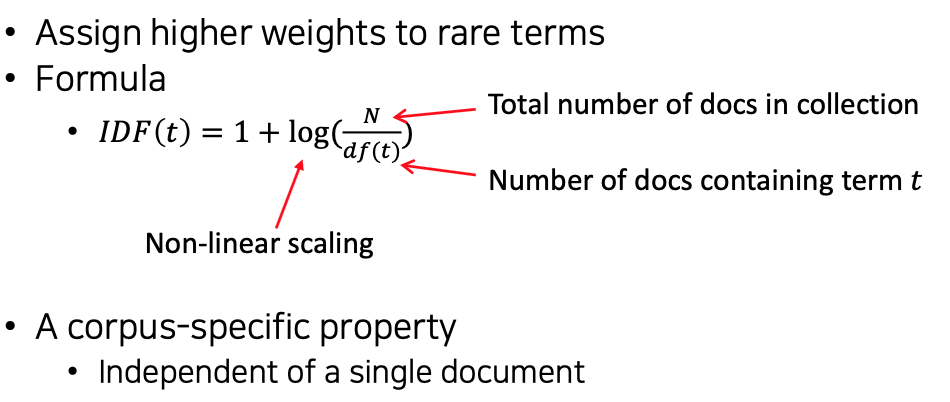
TF-IDF weighting

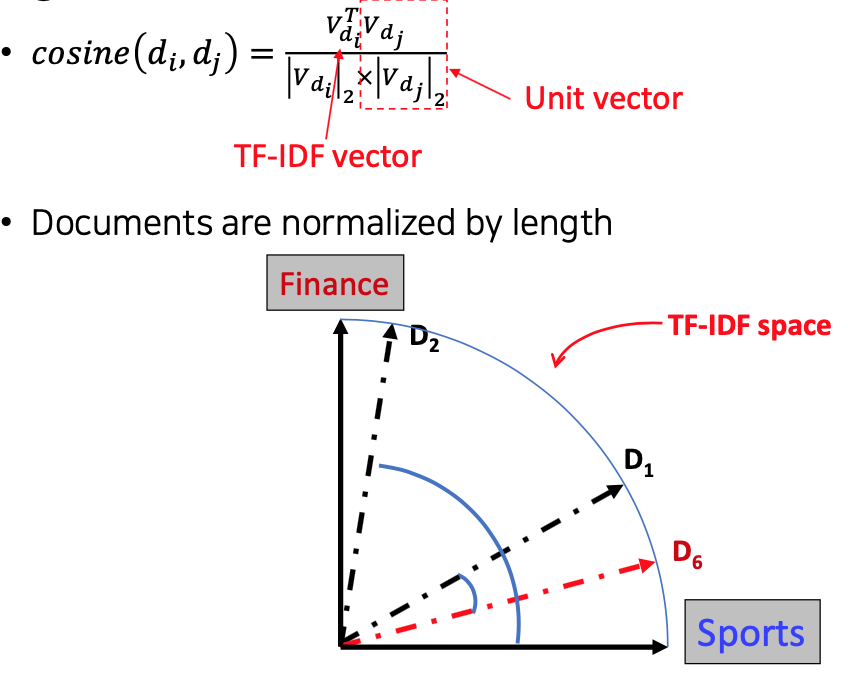
How to define a good similarity metric?
- Euclidean distance?

From distance to angle
- Angle : how vectors are overlapped
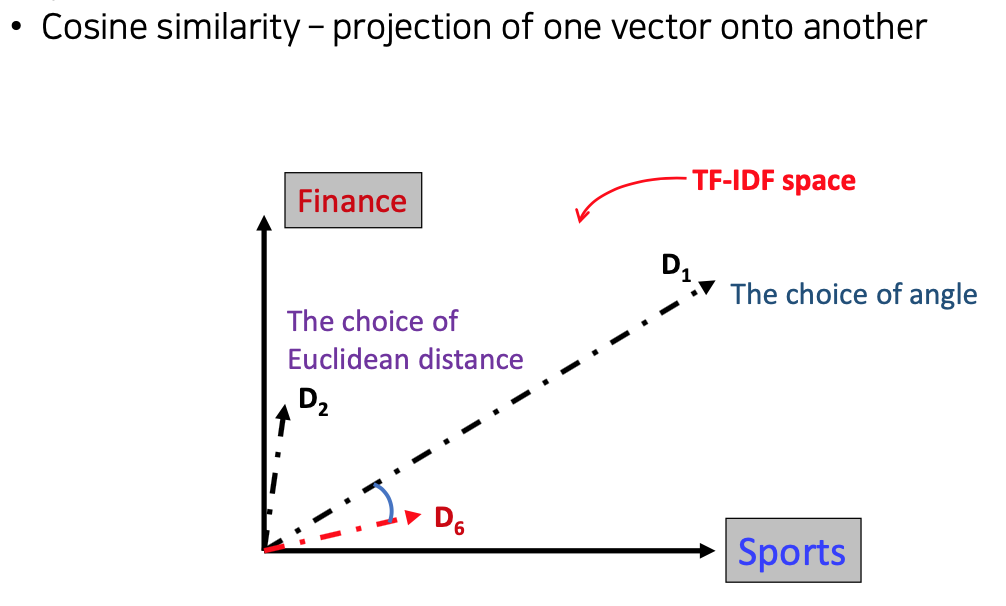
Cosine similarity
- Angle between two vectors