Spring_ELK
1.[Spring-ELK] 엘라스틱 서치? 그게 뭔데
한동안 블로그 작성을 안 한 이유진짜 진심으로 하루 12시간씩 화면만 들어다보니까 지쳐서 도저히 작성을 못하겠다가 중간발표 앞두고 들어와서 급하게 적는 중이다! 아무튼 현재 진행 상황기본 기능 구현은 다 마무리 져있는 상태에서 엘라스틱 서치 기능을 도입하기로 했다. 근
2.[Spring-ELK] Docker: Elastic Search , Kibana를 설치해서 springboot와 연결하자! (1)

엘라스틱 서치 -> eskibana -> 키바나라고 정의하겠다.일단 es와 키바나를 설치하여보자.일단 설치 환경은 나는 윈도우환경이고개발은 인텔리제이에서 스프링부트 3.3.4를 이용하고있다.Elastic Search Engine의 Sprign Client인 spring
3.[Spring-ELK] Docker: Elastic Search , Kibana를 설치해서 springboot와 연결하자! (2)
이전글을 보면 docker위에 es와 키바나가 설치된 것 까지 진행되었다. 이번에는 spring boot환경을 세팅할 거다!api를 생성하려면? 기존에 Entity를 생성 -> Repository 생성 -> Service를 생성 -> controller 등록한다.그런데
4.[Spring-ELK] es로 구현한 예매검색 api
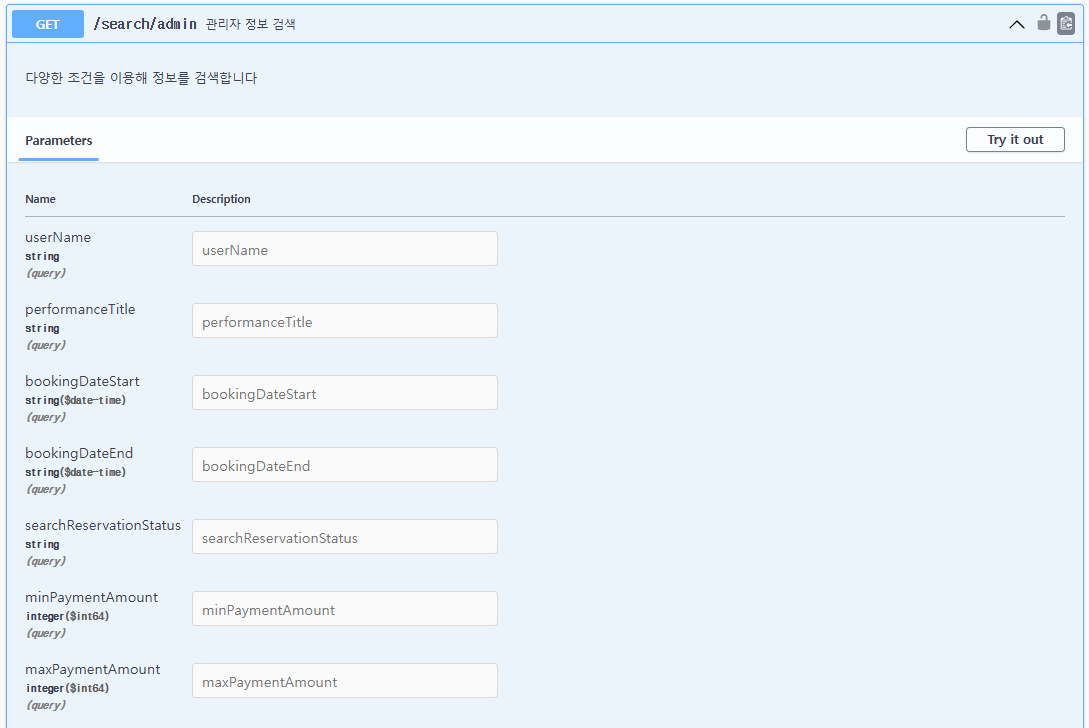
swagger에서 api동작을 확인해보도록 하겠다.userName: 예매자 이름특정 사용자의 모든 예매/결제 내역을 보고 싶다면, userName 필드만 입력하여 검색합니다.performanceTitle: 공연제목관리자가 특정 공연에 대한 모든 예매 내역을 보고 싶다면
5.Elastic 성능 체크를 promethus와 grafna로 해보자

elastic 검색 엔진을 구현했는데, 이 엔진이 과연 mysql쿼리 검색보다 더 나은 성능을 가지고 있는 지가 궁금해졌다.이왕 체크하는 거 지표를 가지고 싶어서 두 가지를 활용했다. Prometheus와 Grafana를 이용해서 결과물을 만들어볼 생각이다.Prome
6.Elasticsearch 성능 테스트 보고서 1
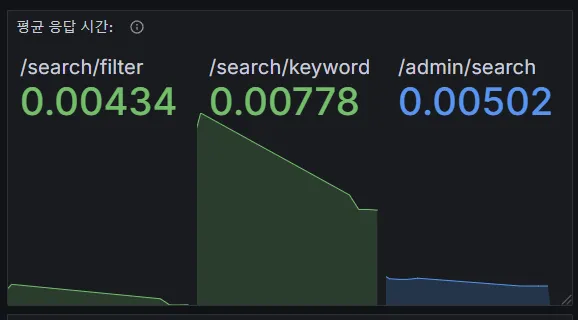
Elasticsearch(ES) 기반 API와 SQL 기반 API의 성능 비교.높은 부하 조건에서 각 API의 안정성 평가.초당 처리량(QPS), 평균 응답 시간, 자원 사용량(CPU) 기반 성능 평가.ES기반 API 효율성을 확인하기 위해 진행됨테스트 조건동시 사용자
7.elastic 모니터링과 속도측정테스트 2
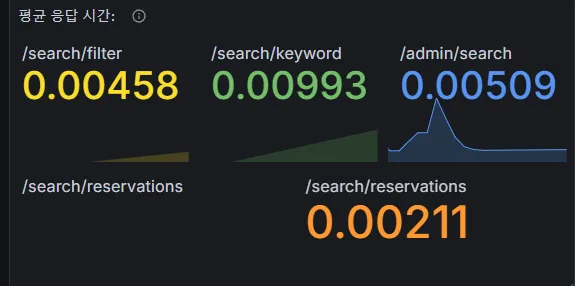
요약생각을 해보니 이렇게 나올 수 밖에 없었던 것 같다. 일단 첫번째로, 데이터 처리 과정 자체가 너무 달랐다. 그리고 비교했던 mysql 쿼리문이 굉장히 단순한 편이어서 데이터 처리 속도가 월등히 빠를 수밖에 없다고 판단했다. 테스트 데이터가 작을 경우:ES는 큰
8. Logstash - springboot 환경 구현하기(로그수집하기)
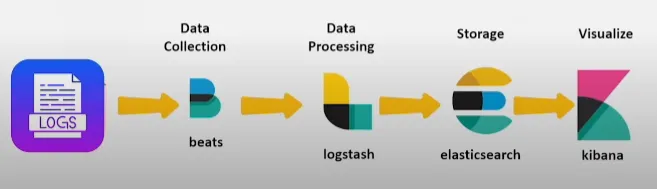
이제껏 E와 K를 구현해진 상태에서 뒤늦게 로그를 수집하겠다고 Logstash를 적용해야하는 상황이 펼쳐졌다...로그스태시 환경 구현하는 방법을 설명보려고 한다.일단, 기본 배경에는 도커로 elasticsearch와 kibana가 깔려있는 상태여기서 도커에 logsta
9.logstash AOP로 로그 수집하기

횡단 관심사 처리: 로그 수집은 비즈니스 로직과는 별개의 "횡단 관심사(Cross-Cutting Concern)"이므로 AOP로 분리해 관리.코드 중복 제거: 비즈니스 로직마다 로그 코드를 추가하지 않아도 AOP로 공통 처리를 가능.유연한 확장성: 특정 메서드나 클래스
10. Elasticsearch vs MySQL: 왜 MySQL이 더 빠를까?
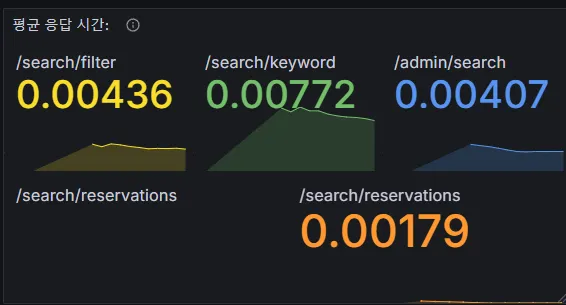
최근 프로젝트에서 Elasticsearch(ES)와 MySQL을 활용하여 여러 API의 성능을 비교해본 결과, 의외로 MySQL 기반 쿼리가 ES 기반 쿼리보다 더 빠르게 동작하는 현상을 발견했다.보통 ES는 대규모 데이터 검색과 복잡한 쿼리를 처리하는 데 최적화된 도