20221107_mon
실습내용
- 1페이지부터 10페이지까지 다음버튼 제외하고 리뷰를 총 200개정도읠 리뷰를 가져와보자
- 셀레니움 사용하기(주소링크를 클릭하기만하면 사이트가 자동으로 열리면서 데이터를 자동으로 끌어오도록만드는 것)
- 가장 먼저 리뷰가 어디있는지 해당 XPATH를 먼저 찾아봐야한다.
- 해당버튼을 클릭해서 해당 데이터를 갖고오기
- 해당페이지의 리뷰 데이터를 모두 끌어오기.
- 그리고 1-10페이지의 모든 데이터 끌고오기.
파이썬 실습
# 가장먼저 우선적으로 셀레니움 설치하고 시작한다.
# 셀레니움 설치하기
# 코랩사용시 이후 다운로드설치 필요없지만
# 주피터이용시 구글링하여 크롭웹드라이버를 쳐서 다운로드가 필요하다.
!pip install selenium
!apt-get update # apt install을 정확히 실행하기 위해 ubuntu 업데이트
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
import sys
sys.path.insert(0,'/usr/lib/chromium-browser/chromedriver')
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
from selenium import webdriver
from selenium.webdriver.common.by import By
import bs4
import time
from urllib.request import urlopen
from bs4 import BeautifulSoup
# 예외처리해보기
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from selenium import webdriver
#colab-driver 설치
driver = webdriver.Chrome(
'chromedriver',
chrome_options=chrome_options)
chromedriver_dir = r'./chromedriver.exe'
#driver = webdriver.Chrome(chromedriver_dir)
driver.get('https://search.shopping.naver.com/catalog/34558906623?query=%EC%95%84%EC%9D%B4%ED%8F%B0%2014PRO&NaPm=ct%3Dla613n4w%7Cci%3D508dd7d94d17205d26c2a50cc41f5f6d58a47a40%7Ctr%3Dslsl%7Csn%3D95694%7Chk%3D6002bcd4d077c4b82a782ceba43f41d8201a7f70')
time.sleep(5)
from selenium.webdriver.common.by import By
# 원하는 사이트 위치 주소 넣기
url="https://search.shopping.naver.com/catalog/34558906623?query=%EC%95%84%EC%9D%B4%ED%8F%B0%2014PRO&NaPm=ct%3Dla613n4w%7Cci%3D508dd7d94d17205d26c2a50cc41f5f6d58a47a40%7Ctr%3Dslsl%7Csn%3D95694%7Chk%3D6002bcd4d077c4b82a782ceba43f41d8201a7f70"
driver.get(url)
# print(driver.page_source)
# 하나만 찾을때는 element 여러개는 복수형 elements
# 원한는 태그 선택하고 오른쪽 클릭해서 'copy fULL XPATH' 클릭하고 복사하여 들고온다.
# 사이트위치
html = urlopen('https://search.shopping.naver.com/catalog/34558906623?query=%EC%95%84%EC%9D%B4%ED%8F%B0%2014PRO&NaPm=ct%3Dla613n4w%7Cci%3D508dd7d94d17205d26c2a50cc41f5f6d58a47a40%7Ctr%3Dslsl%7Csn%3D95694%7Chk%3D6002bcd4d077c4b82a782ceba43f41d8201a7f70')
bs = BeautifulSoup(html.read(), 'html.parser')
# 네이버리뷰 전체 한꺼번에 뽑기. 클래스 한꺼번에 두개 선택한다.
#target_class=["reviewItems_text__XrSSf", "type06"]
#articles = bs.select_one("#main_content > div.list_body.newsflash_body ").select_one('li')
# 네이버 리뷰 XPATH 복사하기
XPATH="/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/ul/li[3]/div[2]/div[1]/p"
res =driver.find_element(By.XPATH,XPATH)
print(res.text)
# 미리 뽑아야하는 데이터 변수선언
reviews=[]
stars=[]
cnt=1 #리뷰index
page = 1 # 이전에 한번돌았으면 이미 10까지 간 상태이기때문에 다시 런할때 여기 무조건 초기화해주기위해 런해주기!
for _ in range(10):
#while True:
j = 1
print("페이지",page)
for i in range(1,21):
#while True:
try:
star = driver.find_element(By.XPATH,f'/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/ul/li[{i}]/div[1]/span[1]') #5를 감싸고 잇는 스판을 가져와 줘야한다
driver.implicitly_wait(5) # 해당 객체를 가져오고 그다음 텍스트를 뽑아준다
stars.append(star.text)
review=driver.find_element(By.XPATH,f'/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/ul/li[{i}]/div[2]/div[1]/p')
driver.implicitly_wait(5) # 최대 몇초까지 기다리는데 실행되면 바로 넘어가게 된다 # 해당 페이지를 너무 빨리 긁어와도 문제가 생기기때문에 슬립을 걸어줄 수 있다
reviews.append(review.text)
j+=1
print(cnt,review ,star,"/n")
cnt+=1
except:
break
#페이지 이동
try:
page+=1
driver.find_element(By.XPATH,f"/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/div[3]/a[{page}]").click()
time.sleep(2)# 다음페이지로 넘어갈때 데이터로딩시간이 있기때문에 2초정도 sleep을 줘야 에러가 발생하지않는다! 위에도 wait이 있기때문에!
except:
break
#그리고 우리가 배운대로 엑셀로 뽑아보자
import pandas as pd
data={
'review':reviews,
'star':stars,
}
df = pd.DataFrame(data) #index 설정할 수 있음
df.to_excel("naverReview.xlsx")
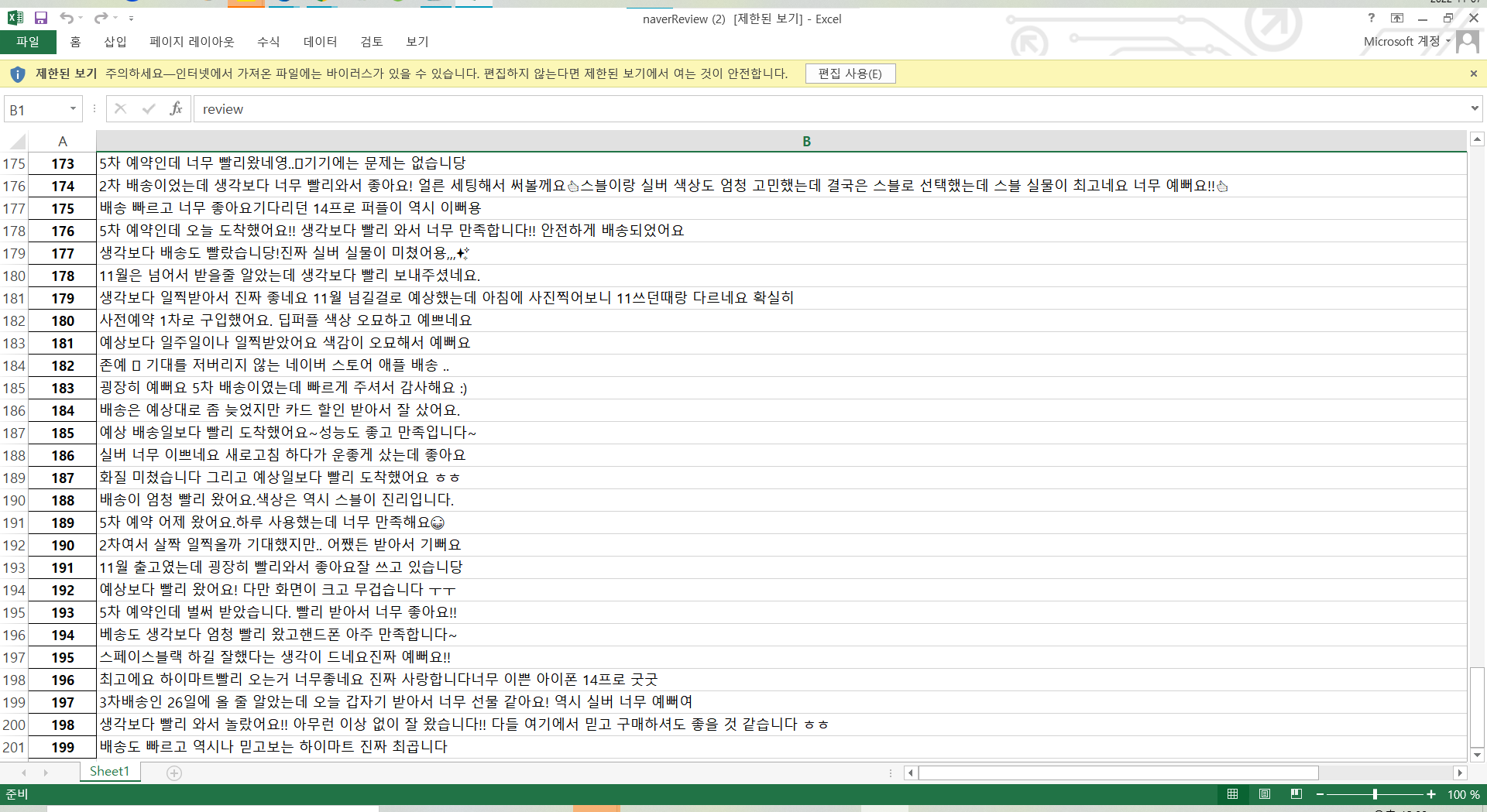
#df # 결과 바로 이쁘게 테이블로 출력해서 보기네이버 리뷰및 평점엑셀 출력 결과
: 1페이지 부터 10페이지까지의 총 200개의 리뷰내용과 별점을 엑셀로 출력시켜 확인 할 수 있다.
머신러닝
머신러닝 초보자가 배워보기
: 생활코딩 강사님 사이트추천 https://opentutorials.org/course/4548
대표적 유투브 알고리즘도 머신러닝의 일종이다.
머신러닝의 필수 요건 3가지
- 원리
- 수학
- 코딩
라이브러리,API와 같은 잘만들어진 것들을 갖고와서 사용하는 방식.
머신러신 만들어주는 사이트
https://teachablemachine.withgoogle.com/
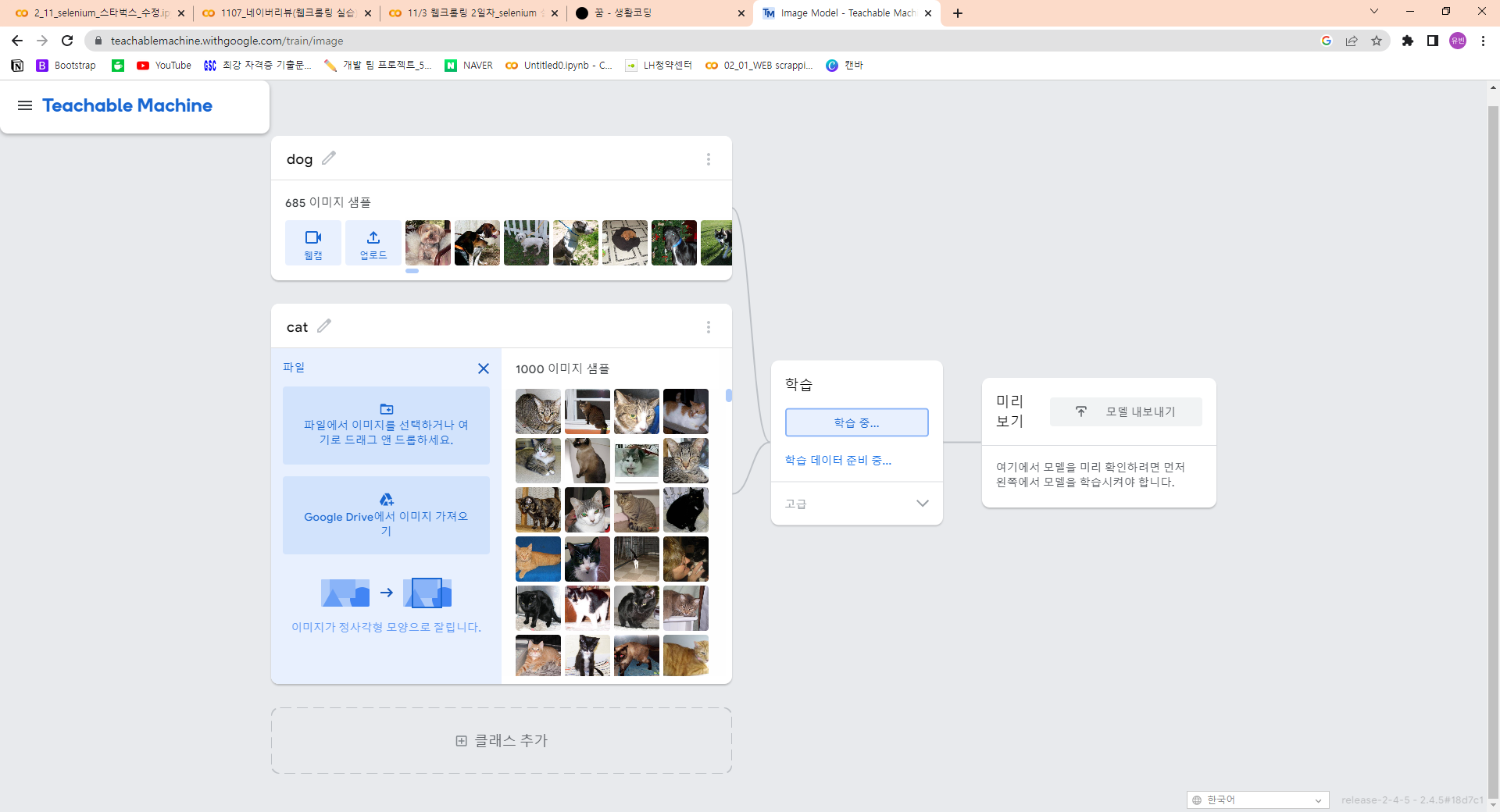
이사이트에서 미리받아둔 강아지와 고양이 이미지들을 업로드한다.
- 주의할 점
: 그런데 너무 과도한 학습(너무많은 학습 이미지 업로드시)을 준 경우 일정 부분부터는 학습률이 떨어진다. - 학습러닝 강아지-고양이 이미지 분류 학습시키기
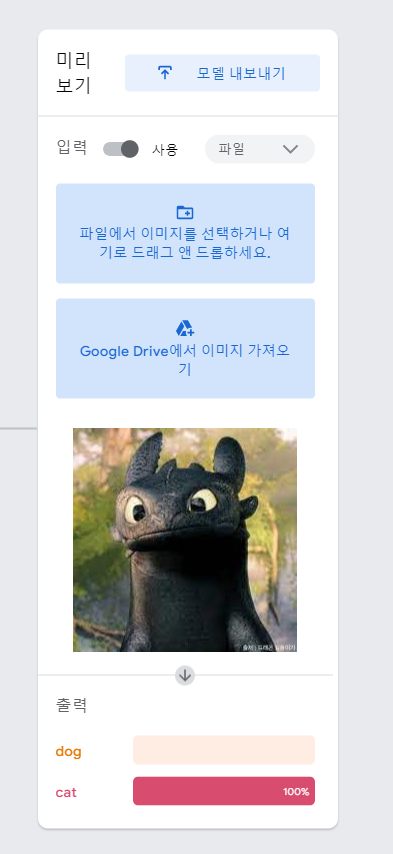
- 내가 구글에서 찾아본 '투슬리스'를 업로드해서 머신러닝했을 때의 결과는 'cat'으로 추측 100%가 나왔다.
✔👀 그렇다면 우리가 해야할 머신러닝은 어떤것인가?
:input으로 우리가 가져올 데이터를 크롤링 해서 학습시킨 모델을 통해 결과를 추측내는 머신러닝을 해보자.
✔ 예시를 알아보면,
:네이버리뷰에서 가져온 평점이 3점미만이면 부정적, 3점이상이면 긍정적이라과 볼 수 있돌고 머신러닝을 사용할 수 있다.
그런데, 별점이 5점인데 별로예요 라는 리뷰가 있을 경우는 휴면에러라고 하는데 이렇게 데이터가 많지않을 경우는 어쩔 수 없이 사람이 직접한다거나 데이터의 양을 무수히 많이 넣어서 해결할 수 도 있다.
- 참고 자료

위 그림대로 우리가 하는 네이버리뷰 별점 머신러닝의 경우는 몇점 미만이거나 이상이면 긍정과 부정이라는 정답결과를 보고 문제를 해결하는 것이기 때문에 지도학습 이라고 볼 수 있다.
머신러닝 실습
- 사람의 age와 destiny 수명간의 관계를 분석해볼수도있다.
- 붓꽃의 품종 3가지를 각각의 변수에따라 분포도를 통해 결과를 예측할 수 있다.(지도학습)
- 그림판 손글씨이미지로 어떤 숫자를 예측할 수 있는지 알아보자
나에게 필요한 머신러닝을 찾아내는 방법(생활코딩)
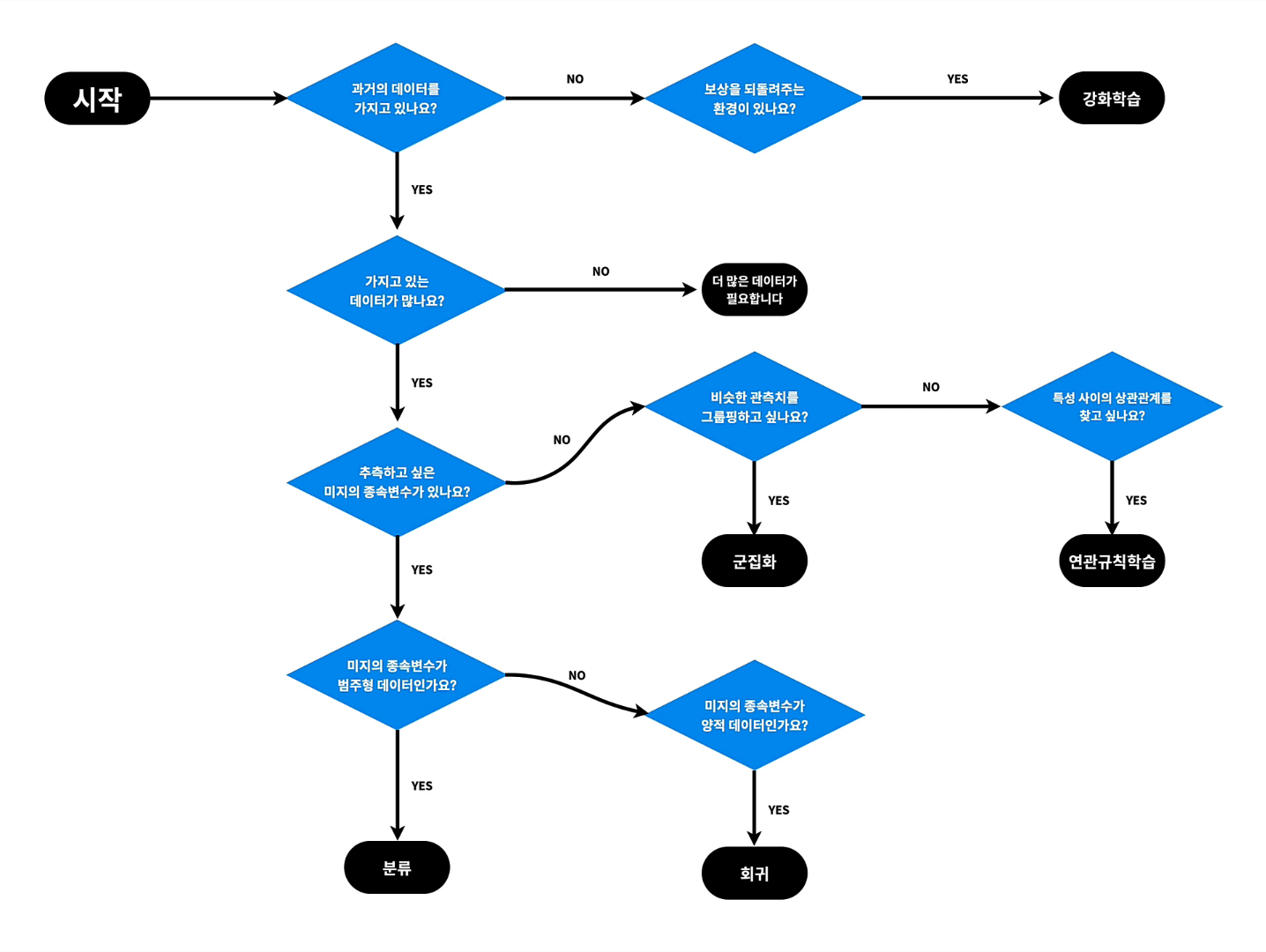
생활코딩의 알고리즘 표를 이용해서 생각해보자.
가장유명한 모델이 SVM이다.
SMS문자기능 구현
https://coolsms.co.kr/ 회원가입하기
가입한 정보
이메일 :numberfive.zys@gmail.com
비밀번호 :dldbqls997@A
레퍼런스 사이트 : https://ohrora-developer.tistory.com/m/5
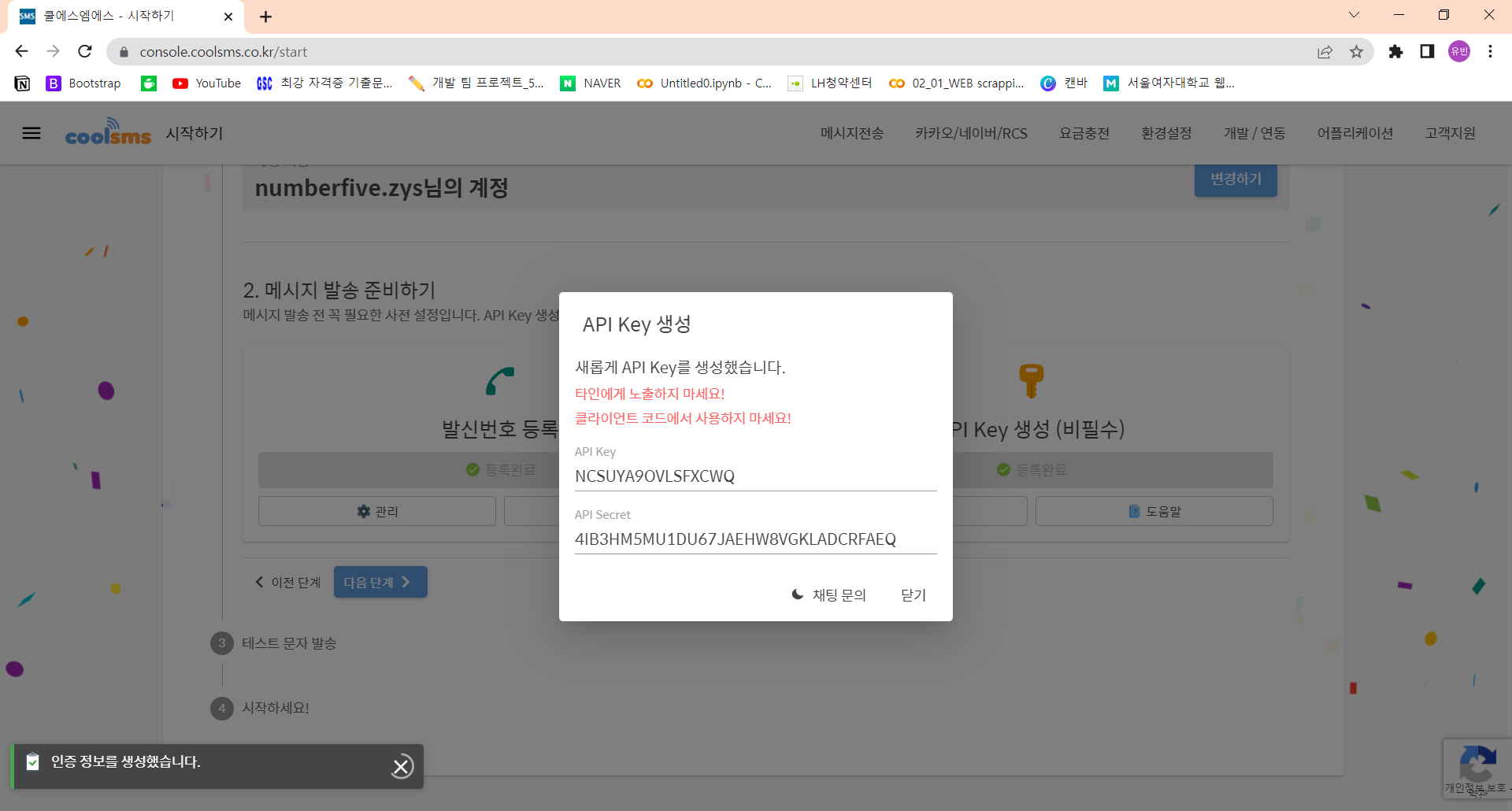
API KEY
: NCSUYA9OVLSFXCWQ
API SECRET
: 4IB3HM5MU1DU67JAEHW8VGKLADCRFAEQ