[DACON] ChatGPT 활용 AI 경진대회
대회 개요
DACON에 ChatGPT관련해서 재밌어 보이는 대회가 나와 참가해보았다.

[대회 설명]
ChatGPT에게 질문하고, ChatGPT가 제공한 응답(코드)으로 AI 프로젝트 코드를 작성하여 생성된 모델의 추론 결과를 제출해야 합니다.
ChatGPT가 제공한 응답(코드) 이외의 코드를 사용(혹은 직접 코딩)할 수 없으며, 참가자는 오로지 ChatGPT가 응답한 코드만을 조합하여 실행시켜야 합니다.
현재 데이콘에 진행되는 ChatGPT 활용 경진대회를 진행 중이며, 오직 ChatGPT만을 활용하여 NLP를 활용한 Multi Label Classification을 하는 것이 목표이다.
대회는 설명에서 나와있는 것처럼 CahtGPT가 제공하는 코드만으로 모델링 과정을 진행해서 리더보드에 높은 성적을 등재하는 것이 목표이다.
데이터(Train, Test, Sample_submission)
데이터는 뉴스 기사 원문에 대한 데이터이며, 총 8개의 뉴스 카테고리(Sports, Politics, Entertainment 등등)의 label로 구성되어 있다.
대회 규정
평가지표는 f1-score를 활용하여 평가를 진행하며, 중요한 점은 ChatGPT가 제공한 코드를 '활용'하는 것이 아니라 그대로 '복제'해서 사용해야한다는 점이다. 그래서 정말 본인이 어떤 파일이 있고, submission파일 이름이 어떻고,라벨이 몇개이고 등등 세부적인 정보를 그대로 제공해야지 바로 코드를 실행할 수 있을만큼의 코드를 제공해주는 것을 볼 수 있다.

첫 시도 - Bert
Dacon에서 제공한 베이스라인 질의를 기반으로 호기롭게 첫 시도를 해보았다. 베이스라인 코드에서는 가볍게 Word2Vec으로 뉴스원문을 임베딩하고, LGBM classifier로 학습을 진행하였다.
성능을 높이는 것이 목표기에 ChatGPT에게 먼저 내 Task에 대해 알려준 뒤, 성능을 최대로 높일 수 있는 임베딩 방식이나, 모델링 방식을 코드로 만들어 달라고 했다.
예상했던 것처럼 ChatGPT는 Transfomer기반의 임베딩 방식과 모델링이 성능을 높이는 데 가장 좋다고 언급했고, 그래서 Bert 모델 기반으로 코드를 작성해달라고 해봤다.
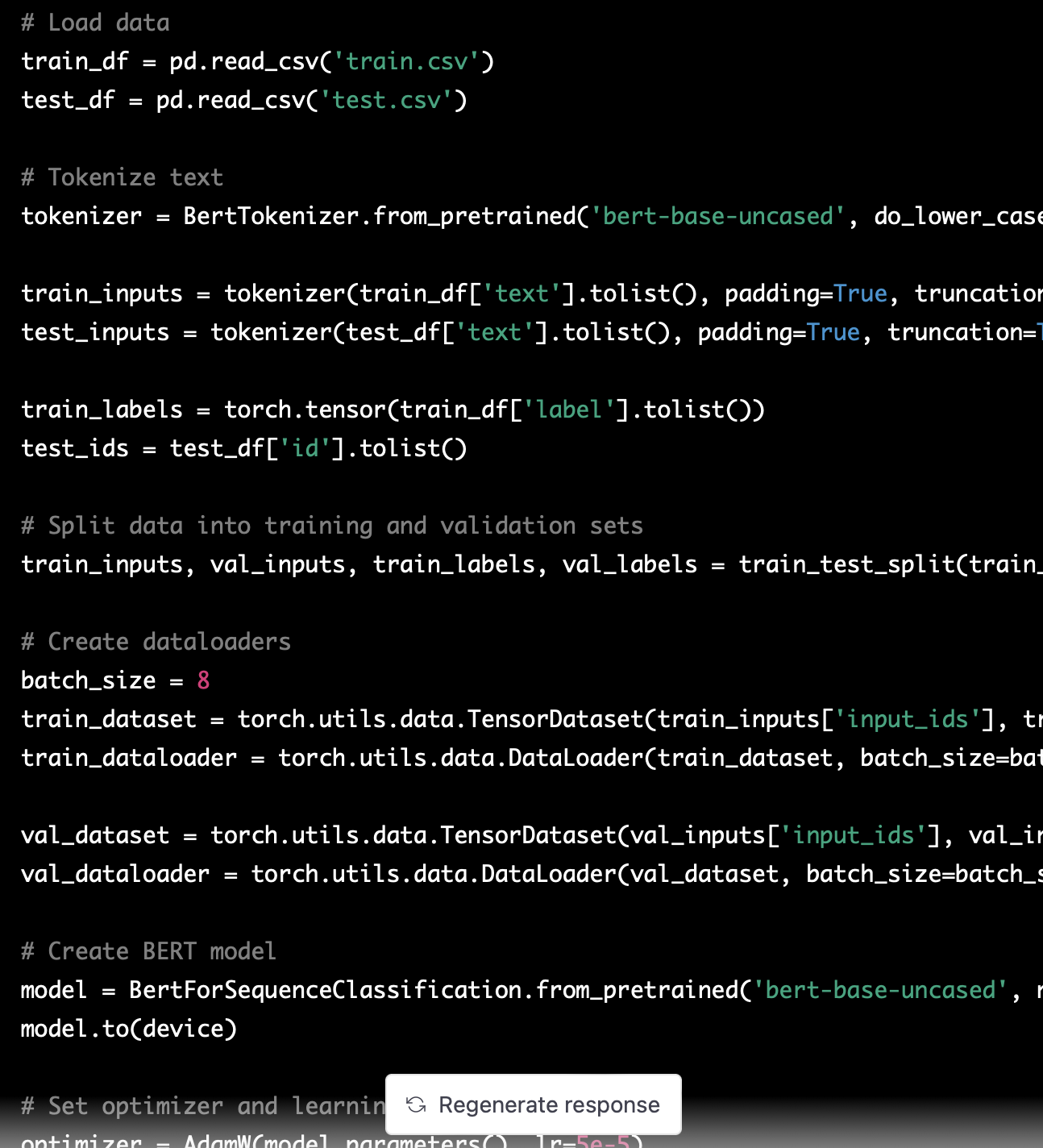
대충 이런 식으로 코드가 나왔고, Tokenizer와 학습 모델 모두 Bert 기반으로 작성되었다.
문제점 발생
코랩 GPU를 사용해서 코드를 돌렸고, 먼저 Sample 데이터를 사용해서 코드가 잘 돌아가는지를 확인하려고 했다. 그런데 샘플만 했는데도 모델이 너무 느려서 끝날 생각을 안했고, Tqdm으로 시간을 확인해본 결과 샘플로도 4-5시간이 소요될 것으로 예상됐다(Train과정에서).
결국, 코랩 GPU랑 TPU 용량으로는 도저히 코드를 도릴 여유가 없고, Bert처럼 무거운 모델로는 학습시키기가 싶지않겠다는 생각이 들었다.
Train Data : 약 4만개
Test Data : 약 8만개
라이트한 코드?
여러 시도를 해본 결과, 결국 Test 8만개의 뉴스 원문들을 임베딩해야 하는 과정이 필요하기 때문에 텍스트 임베딩 과정에서의 시간을 줄여보고자 했다.

그래서 일단 Baseline 코드처럼 기본 임베딩 방식을 활용해서 모델을 돌렸는데, 예상했던 대로 그렇게 좋은 결과가 나오지 못했다.
위에 적힌 방식말고 Sklearn에서 제공하는 Tokenizer방식을 TPU로 돌려도 빠른 속도로 코드가 돌아갔다. 속도가 빨라져, 학습 epoch도 늘리고, 전처리 과정도 추가해보고, 하이퍼파라미터도 이것저것 만지면서 제출을 해봤는데, 성적이 좋아지긴해도 먼가 이거다 할 방법이 아니라는 생각이 들었다.
다시 Bert(s-bert)
처음에 Bert 기반으로 모델을 돌렸을 때, 제일 시간이 많이 소요되는 부분은 임베딩 부분보다는 학습 과정이었다. 그래서 일단 Bert로 임베딩시키고, 일반 ML모델로 모델학습을 진행한다면 어떨까라는 생각이 들었고, 뉴스 기사의 문맥 파악에 sentence-bert가 좋다는 얘기를 들어서 sentence-bert로 임베딩을 진행해보기로 하였다.
성능 왜 별로?
임베딩 과정도 1시간 넘게 걸리고(word2vec이나 tf-idf 이런건 10분도 안걸림), Bert로 처음으로 코드 진행 완료된 거여서 기대를 가지고 제출을 했는데, tf-idf 쓴 것보다 점수가 안나왔다. 솔직히 잘 이해가 안됐고, 아직 모델적인 지식이 많이 없는 상태라서 조금 막막해졌다. 절대적으로 좋은 방법이란 존재하지 않지만, 그래도 SOTA 모델인 Bert기반으로 임베딩한 점수가 tf-idf보다 낮게 나와서 앞으로 방향성을 어떤 식으로 잡아야할지 애매해졌다.
분명 얘가 좋다고 했다.

추후 계획
- 라이트한 모델 with 텍스트 전처리 추가 + CV + 파라미터 튜닝
- sota 모델로 계속 시도?
느낀 점
일단 처음에 대회를 보고 든 생각이 일반적인 캐글과 같은 대회는 보통 신분의 벽을 넘을 수 없다고 느낄 만큼 잘하는 사람들은 정말 잘하고, 본인의 실력이 그대로 성적에 반영된다고 느꼈지만, 이 대회는 본인이 직접 하는 게 아니라 결국 ChatGPT의 코드로 결정되니까 실력적인 부분이 조금은 줄어든다고 생각했다.
하지만 결국 해보면서 느낀 게, 본인이 아는만큼 ChatGPT에게 부탁할 수 있고, 코드 요청 및 원하는 방법대로 수정을 요청할 수 있기에 결국 내가 얼마나 잘 알고 있는지가 성적을 좌우한다고 느꼈다.
물론 내가 모르는 지식들도 많이 알 수 있다고 느꼈지만, 결국 그 지식들을 미리 알고 있다면, 더 심화된 내용을 보다 다양하게 시도해볼 수 있어서 결국 실력 좋고 많이 아는 사람이 이번 대회에서도 좋은 성적을 받을 것 같다.
결론 : ChatGPT에게 의존하지 말고 공부 더 열심히 하자.
