전처리
전처리 과정은 크게 다음의 3가지 절차를 거쳐 진행되었다.
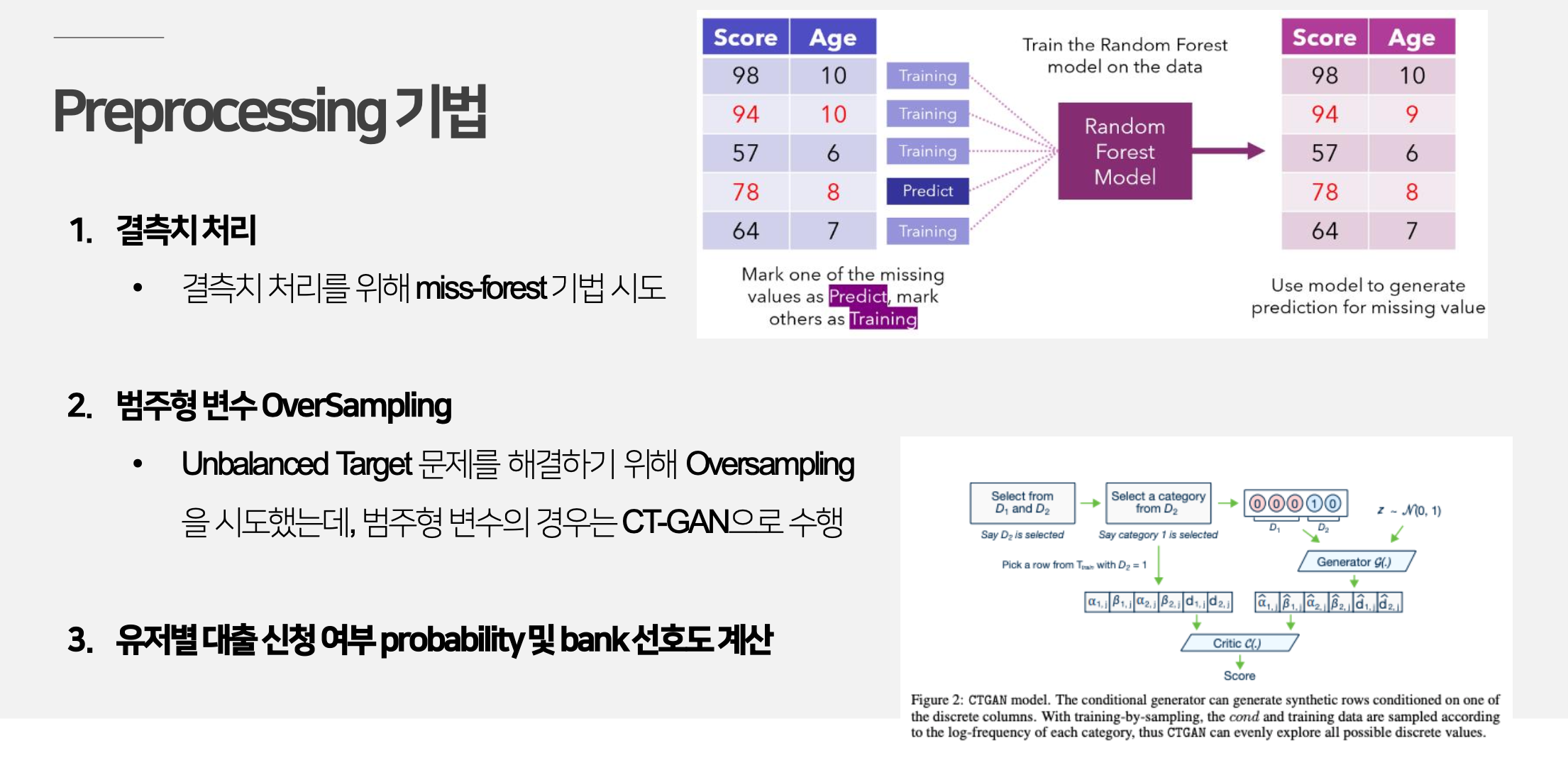
1. 결측치 처리
결측치 대체에 대해 말하기 전에, 먼저 학습에 진행하지 않아 제거한 변수가 존재하였다.
User_id, application_id는 각 행마다 고유한 값을 가지기 때문에, 오버피팅의 위험이 존재한다고 판단하여 제거하였다. 추후 모델링에서 알게 된 내용이지만, 개인 회생자 컬럼의 경우에도 결측치를 채워 학습한 것보다 변수 자체를 제거하고 진행한 결과가 더 좋은 성능이 나와 개인 회생자 컬럼 역시 제거하기로 하였다.
Miss Forest
3가지 데이터 셋의 경우 모두 수치형 변수와 범주형 변수를 포함하고 있었고, 결측치 대체를 위해 Miss Forest 알고리즘을 사용하였다.
Miss Forest 알고리즘은 데이터셋에 수치형, 범주형 변수가 모두 포함되어 있을 때 한번에 결측치를 처리할 수 있는 방법으로, Random Forest를 기반으로 작동한다. 여러 결측치 대체 기법을 사용하여 비교해본 결과, Miss Forest 알고리즘을 사용했을 때, 좋은 성능을 보여 해당 기법을 최종 결측치 처리 알고리즘으로 선정하였다.
2. 범주형 변수 Over-Sampling
첫 번째 EDA 포스트에서 언급했듯이, 분석하고자 하는 데이터셋은 굉장히 Imbalanced한 데이터셋이다. 대회 측에서도 이를 고려했는지 당연히 모델의 평가 척도는 f1-score였고, 불균형한 데이터셋을 어떻게 처리하는지가 중요한 과제가 되었다.
가장 골치아팠던 부분
수치형 데이터만 존재했다면 over sampling도 간편하게 이뤄졌을 것이고, 큰 문제가 없었겠지만 데이터셋에 일단 범주형 변수가 너무 많이 존재했다. 범주형 변수를 오버 샘플링하는 기법이 그렇게 간단하지도 않았고, 좋은 성능이 나타나지도 않아서 샘플링 과정에서 많은 고민을 했다.
실제로 많은 ML 모델에 imbalanced target에 weight를 줘서 불균형을 처리하는 파라미터가 있었고, 이러한 방법을 택할지 over sampling을 진행할지에 대한 논의가 있었다.
또한, 별도의 샘플링없이 auto-encoder 모델을 통해 대출 신청을 이상치로 보고 이상치 탐지 알고리즘을 적용해보기도 하였다. 해당 내용은 아래 모델링 부분에서 더 설명하도록 하겠다.
CT-GAN

범주형 변수의 경우에는 CT-GAN을 활용하여 over sampling을 진행하였다.CT-GAN은 생성 모델의 잠재 공간을 탐색하는 대신 데이터의 원시 분포(raw distribution)를 모델링하여 데이터를 생성하기에 데이터셋의 특성과 분포를 모델링하는 데 있어서 높은 성능을 보인다.
문제점
1. 일단 새로운 데이터 자체를 생성해내기 때문에 기존 데이터와 결합하기가 쉽지 않음.
2. 시간이 너무 오래 걸림. 대용량 데이터 셋이라 샘플링 과정 자체에도 많은 시간이 소요되고, 샘플링 후의 학습 과정에서도 많은 시간과 computing source가 요구되었음.
모델링
사용 데이터
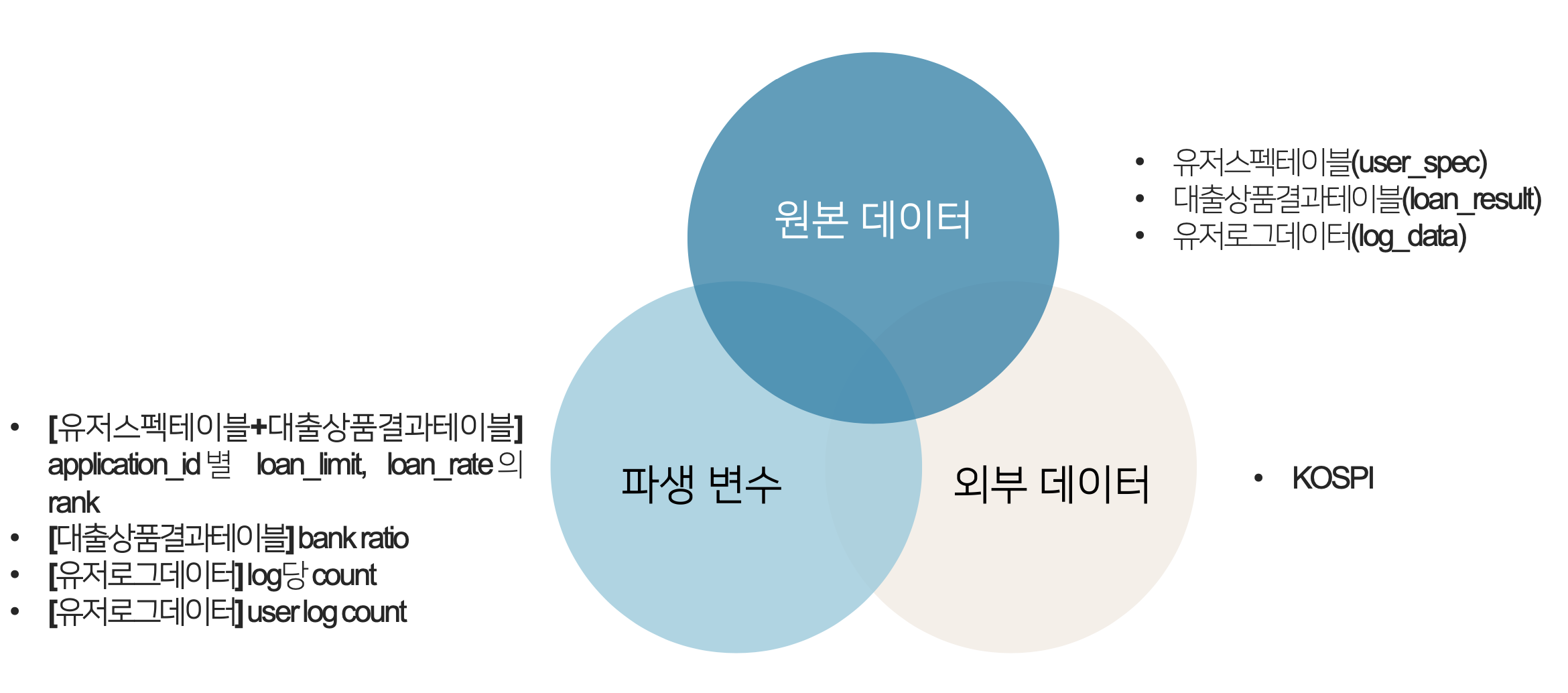
사용 데이터를 총 정리하자면 위의 그림과 같다. 기본적으로 원본 데이터들을 Merge하여 사용하였다. 파생 변수로는 앱 인터페이스를 고려한 rank와 은행 별 선호도 및 대출 빈도를 고려한 bank ratio를 생성하였다. 로그 데이터의 경우 분석 가능한 형태로 변형한 파생변수를 별도로 생성하였다.
외부 데이터로는 대출에 직접적으로 영향을 줄 수 있는 KOSPI를 외부 데이터로 사용하였다.
사용 모델
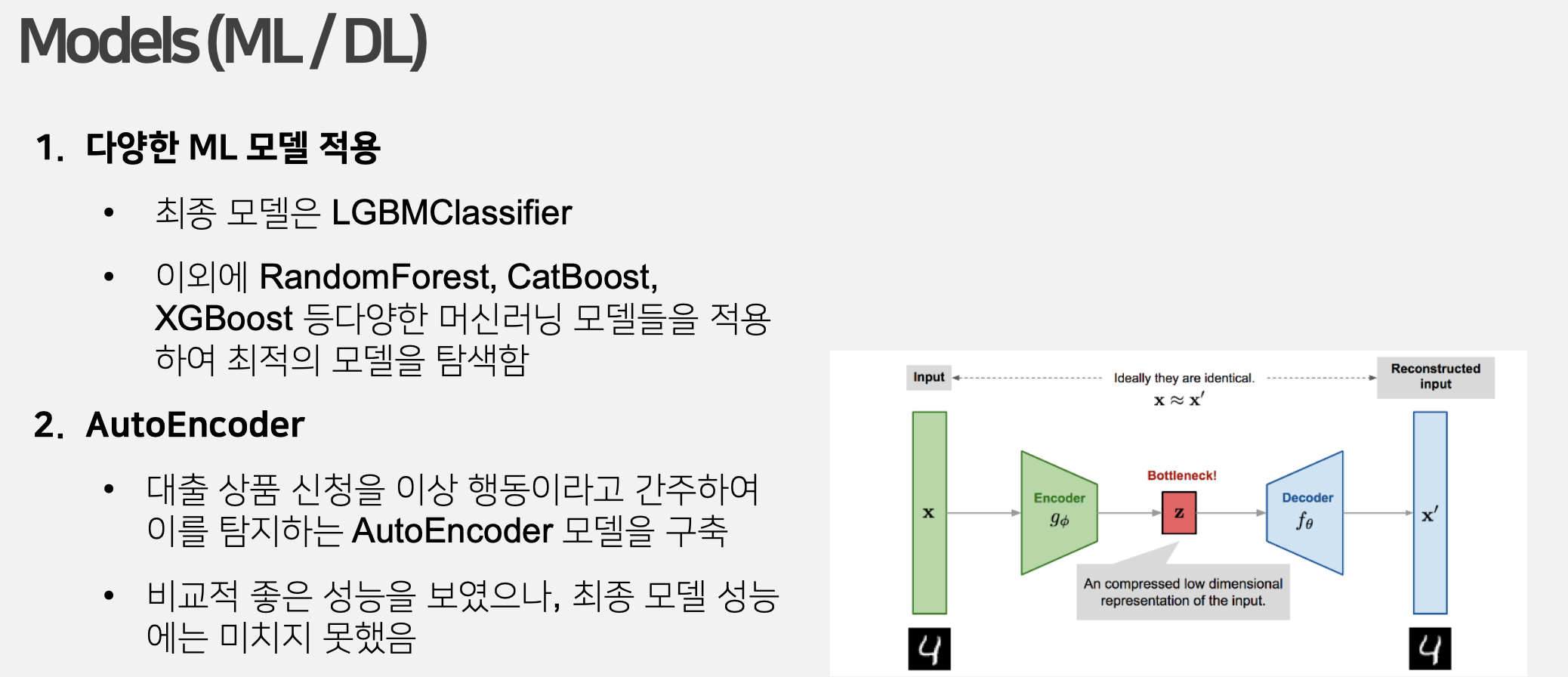
사용 모델은 크게 ML과 AutoEncoder로 나뉜다.
ML의 경우 RandomForest, CatBoost, XGBoost, LGBM 등의 다양한 모델의 실험해보았다.
ML
ML 모델의 경우, CatBoost와 LGBM에서 좋은 성능을 보였다. 두 가지 모델 모두 Class Imbalance의 가중치를 둘 수 있는 파라미터가 있어 별도의 샘플링 과정없이 진행을 하였고, LGBM이 CatBoost에 비해 빠른 속도를 보였다.
AutoEncoder
대출 신청을 이상치로 간주하여 AutoEncoder 모델도 진행하였다. 좋은 성능을 보이긴 했으나, ML에 비해 더 높은 성능을 보이지는 못하였다.
최종모델 : LGBM
최종 모델로는 LGBM을 선택하였다. 더 많은 시간, 더 많은 리소스가 있었다면 충분히 더 좋은 모델을 구축할 수 있었겠지만 시간적, 비용적 한계로 인해 가볍고 성능이 좋은 LGBM을 최종 모델로 선택했다. 또한 이번 빅콘 테스트 대회는 데이콘이나 Kaggle처럼 평가 항목이 무조건 모델의 성능이 아니고 종합적인 데이터 분석 방법을 평가하기 때문에 LGBM이 충분히 좋은 모델이라고 판단하였다.
Threshold 설정
기본 LGBM 모델로 Class Imbalance 가중치 인자를 설정해도 좋지 못한 f1-score가 나왔다. 시간적 한계로 인해 over-sampling을 하기 어려운 상황이었기에 파라미터 인자로 imbalance 가중치를 해결해야하는 상황이었다.
Train Data는 3달로 구성되는데, 3달의 데이터 모두 1인 Class가 비슷한 비율로 존재했다. >> Test Data에서도 동일하지 않을까? >> Threshold를 조정해보자
결국 이런 아이디어가 나왔고, 기존 LGBM 모델에 Threshold를 적용하여 추론을 진행하였다. Val set에 대해서는 훨씬 높은 f1-score가 나왔고, Test 데이터에서도 당연히 Class Imbalnce가 존재할 것이기에 해당 전제를 가정하고 이를 최종 모델로 제출하게 되었다.
좋은 아이디어일 수도 있지만, Test 데이터의 Class 분포에 따라 성능이 너무 크게 달라지기에 고려해야할 부분이 많다고 느꼈다.
대회 마무리
아쉽게 수상에는 실패하였지만, 학부생으로서 실제 기업 데이터를 다룰 기회가 많지 않기에 정말 열심히 배우며 프로젝트를 진행했다.
피처 엔지니어링과 관련해서는 앱 이용 로그 데이터 분석을 통해 로그 데이터를 처리해 새로운 파생변수로 적용하고, 굉장히 많은 범주형 결측치의 효율적 처리에 대해 특히 많이 공부한 것 같다.
모델링의 경우에는 극심한 Imbalanced 데이터를 적절히 처리하여 최종적인 모델의 성능을 높이는 방법에 대해 많은 고민을 했고, 항상 데이터를 처리하고 가공할 때는 적절한 근거를 가지고 수행하는 습관을 지니게 된 것 같다.
