이번 글에서는 Hashing에 대해 다뤄보고자 합니다.
본 글에서 다루는 코드는 이곳에서 살펴볼 수 있습니다.
Hashing algorithm을 사용하여 hash table data structure를 구성하는 경우, 핵심적인 method는 insert, search, delete operation이 있고, 각각이 time이 소요됩니다. 이는 linked list, stack, queue는 sequential 혹은 linear data structure (element마다 predecessor/successor가 하나만 존재하는 data structure)에 비해 훨씬 빠른 자료구조 관리가 가능합니다.
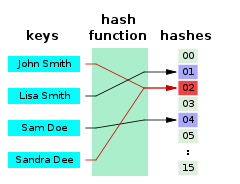
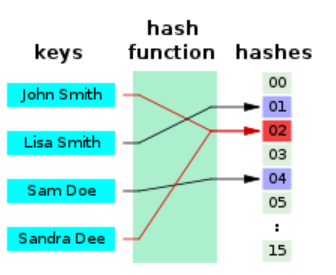
Hashing algorithm의 기본 원리는 key를 입력으로 받아서 hash value (hash code, hash)로 mapping하는 function을 의미하며, 이는 아래 그림과 같습니다. Hashing algirhtm을 통해 얻어낸 hash value에 대해 어떠한 data를 저장하고자 하면 이를 hash table에 저장하게 되며, 이 값을 value라고 부릅니다. 직관적으로 생각하기에도 hashing algorithm을 이용하면 collision이 발생할 것을 예상할 수 있는데, 간단한 예시부터 기본적인 hashing algirthm에 대해서 순차적으로 살펴보도록 하겠습니다.
Hash Table Implementation
struct Node{
Node(char* n, float v): name(n), val(v){}
char *name;
float val;
};Hash algorithm을 위한 data structure로 Node를 구성했고, 이외에도 다양한 hash table 구성방법이 있습니다.
Node의 name이 key, val이 저장할 value에 해당합니다.
list<Node> HT[HTSIZE]; // Hash TableHash collision이 발생하는 경우, chaining을 위해서 "hash table()"의 각 entry를 list로 구성했습니다.
void StoreIntoHT(char* name, float val){
//Hash Table에 name을 키로 val을 값으로 하는 노드를 저장하라
list<Node>::iterator iter;
if(WhereInHT(name, iter)) (*iter).val = val;//change its value to a new one
else HT[hashfcn(name)].push_front(Node(name,val));
} StoreIntoHT이 hash table의 method에 해당합니다.
WhereInHT로 val을 저장할 pointer를 name에 대한 hash value로 iter에 hash table의 entry를 찾아냅니다.
중복되는 key가 있으면 val을 새로운 값으로 변경하고, 없다면 list에 push_front()를 수행합니다.
bool WhereInHT(char *name, list<Node>::iterator& iter){
int hashval = hashfcn(name);
for(iter = HT[hashval].begin(); iter!=HT[hashval].end(); iter++)
if(!strcmp((*iter).name, name)) // iter points to the place
return true;
return false;
}WhereInHT에서는 hashfcn이 hash function으로 key에 대한 hash value를 mapping합니다.
strcmp가 기존 hash table에 같은 key를 갖는 element를 search하는 부분입니다.
중복되는 key가 있다면, true를 return하고 아니면 false를 return합니다.
bool GetFromHT(char* name, float& val){
list<Node>::iterator iter;
if(WhereInHT(name, iter)){
val = (*iter).val; // Found the value
return true;
}
return false;
}GetFromHT는 search operation을 수행하는 함수입니다.
key 값이 name이고, search에 대한 value가 val입니다.
이를 return해서 caller가 활용하도록 implementation 되어있고, 가령 아래와 같이 print에 사용하게 됩니다.
void PrintValue(char* name){
float val;
if(!GetFromHT(name, val)) cout << name << " does not exist" << endl;
else cout << name << " " << val << endl;
}Hash Function (Algorithm)
Hash value를 구하기 위한 여러 algorithm이 존재하는데, open addressing과 chaining에 대한 list는 아래와 같습니다.
아래의 hashfcn()은 open addressing을 적용하지 않는 경우에 대한 hashing algorithm 예시입니다.
Open addressing은 hash collision이 발생하면, hash table에서 비어있는 entry를 찾는 algorithm을 의미합니다.
int hashfcn(char *name){
/*
open addressing
|----linear probing : hash value에 constant number increment.
|----quadratic probing : linear probing과 유사하게 adding number를 quadratic oder로 increment 하는 방식.
|----double hashing : 서로 다른 hash function을 doubly 수행.
|----random probing : 'random' number를 increment하여 probing을 수행. 이상적으로 적용하지 어려움.
|----rehashing : 여러 hash function을 준비하고, collision이 발생하면 다른 hash function을 수행.
chaining
|----item insertion and collision : hash_1(key)==hash_2(key)인 case를 의미함.
|----search : probing을 수행하지 않기 때문에 hash value entry에 대해 sequential search를 수행.
|----deletion : 입력 key에 대한 element를 찾기 위해 sequential search를 수행.
|----overflow : open addressing은 hash table entry가 element보다 많아야하지만 chaning은 더이상 그러한 고민이 불필요함.
*/
return name[0] * name[strlen(name)-1] % HTSIZE;
}hachfnc에서 simple hashing algorihtm implementation을 수행하였으며, 기본적인 open addressing과 chaining에 대해 정리했습니다.
Open addressing에서 collision이 발생하는지에 대한 조건문은 동일하기 때문에 probing에 대한 부분만 각 알고리즘에 맞게 구현하면 됩니다. 아래는 rehashing 중 hash table의 size를 2배로 늘려서 hashing하는 hashfcn을 구현했습니다. REF_HT이 doubled size hash table이고, 기존 hash table인 HT의 itme을 copy & paste합니다. 이후에 hashfcn에서 사용할 HTSIZE를 2배로 assign합니다.
void rehashing(){
list<Node> *REF_HT = new list<Node>[HTSIZE<<1];
list<Node> *tmp_ptr = nullptr;
// copy the original hash table.
for(int idx = 0; idx < HTSIZE; idx++){
for(auto item: HT[idx]){
REF_HT[idx].push_back(item);
}
}
HTSIZE = HTSIZE << 1;
tmp_ptr = HT;
HT = REF_HT;
delete []tmp_ptr;
}chaining은 open addressing과 달리 collision이 발생하더라도 새로운 entry를 찾지않고, collision에 대한 entry에 list를 구성하는 방식입니다. chaining을 위해서 가장 상단의 Node struct를 구성했으며, collision에 대해 list에 append하도록 되어있습니다. 이에 대한 설명은 StoreIntoHT와 동일하기 때문에 생략하도록 하겠습니다.
