Linux Kernel Usage
builtin_explect은 컴파일러가 branch statement에 대한 최적화를 수행하기 위한 keyword입니다.
이는 Linux kernel에서도 자주 등장하는만큼 예시를 통해 자세한 이해가 필요할 것으로 보입니다.
Linux kernel(https://elixir.bootlin.com/linux/latest/)에서의 사용예시부터 살펴보면 아래의 리스트와 같습니다.
arch/alpha/include/asm/local.h, line 76
arch/alpha/kernel/time.c, line 97
arch/arc/kernel/module.c, line 102
arch/arc/kernel/process.c, line 98
arch/arc/mm/cache.c, line 872
arch/arc/mm/fault.c, line 168
arch/arc/mm/tlb.c, 3 times
arch/arm/crypto/aes-ce-glue.c, 2 times
arch/arm/crypto/aes-neonbs-glue.c, line 386
arch/arm/crypto/ghash-ce-glue.c, line 81
arch/arm/crypto/poly1305-glue.c, 3 times
arch/arm/include/asm/atomic.h, line 207
arch/arm/kernel/ftrace.c, line 74
arch/arm/kernel/irq.c, line 118
arch/arm/kernel/process.c, line 256
arch/arm/kernel/signal.c, line 610
arch/arm/kernel/swp_emulate.c, line 139
arch/arm/kernel/unwind.c, line 145
arch/arm/mach-imx/pm-imx5.c, line 256
arch/arm/mach-omap1/clock.c, line 524
arch/arm/mach-omap1/omap-dma.c, 3 times
arch/arm/mm/cache-l2x0.c, 3 times
arch/arm/mm/cache-uniphier.c, 2 times
arch/arm/mm/fault.c, line 356
arch/arm/xen/p2m.c, line 103
arch/arm64/crypto/aes-glue.c, 2 times
arch/arm64/crypto/aes-neonbs-glue.c, line 340
arch/arm64/crypto/ghash-ce-glue.c, line 106
arch/arm64/crypto/poly1305-glue.c, 3 times
arch/arm64/crypto/polyval-ce-glue.c, 2 times
arch/arm64/crypto/sm4-ce-glue.c, line 473
arch/arm64/include/asm/arch_gicv3.h, line 76
arch/arm64/include/asm/elf.h, line 178
arch/arm64/include/asm/uaccess.h, line 49
arch/arm64/kernel/armv8_deprecated.c, line 152
arch/arm64/kernel/fpsimd.c, 2 times
arch/arm64/kernel/process.c, line 365
arch/arm64/kvm/arch_timer.c, line 659
~~~~~리스트를 제외하고도 Linux kernel의 여러 부분에서 builtin_expect를 이용한 최적화를 수행하고 있습니다.
Linux source에서 keyword를 해석하는것보다 예시를 보면서 이해하는 편이 수월할 것 같습니다.
Test Code
keyword를 사용하는 것과 사용하지 않는 경우의 C code는 아래와 같습니다.
#include <stdio.h>
#include <time.h>
// Function to test the performance
int performOperation(int x) {
if (__builtin_expect(x < 0, 0)) {
// Unlikely case
return x * 2;
} else {
// Likely case
return x / 2;
}
}
// Function to test the performance
int raw_performOperation(int x) {
if (x < 0) {
// Unlikely case
return x * 2;
} else {
// Likely case
return x / 2;
}
}
int main() {
int iterations = 1000000000; // Number of iterations for the test
// Test with '__builtin_expect'
clock_t start = clock();
for (int i = 0; i < iterations; ++i) {
performOperation(i);
}
clock_t end = clock();
double durationWithUnlikely = (double)(end - start) / CLOCKS_PER_SEC;
// Test without '__builtin_expect'
start = clock();
for (int i = 0; i < iterations; ++i) {
raw_performOperation(i);
}
end = clock();
double durationWithoutUnlikely = (double)(end - start) / CLOCKS_PER_SEC;
// Print the results
printf("With '__builtin_expect': %f seconds\n", durationWithUnlikely);
printf("Without '__builtin_expect': %f seconds\n", durationWithoutUnlikely);
return 0;
}위의 코드를 line by line으로 assembly와 비교하기 위해서 이곳의 도움을 받았어요.
아래는 keyword를 사용하는 것과 사용하지 않는 경우의 assembly code를 비교한 것입니다.
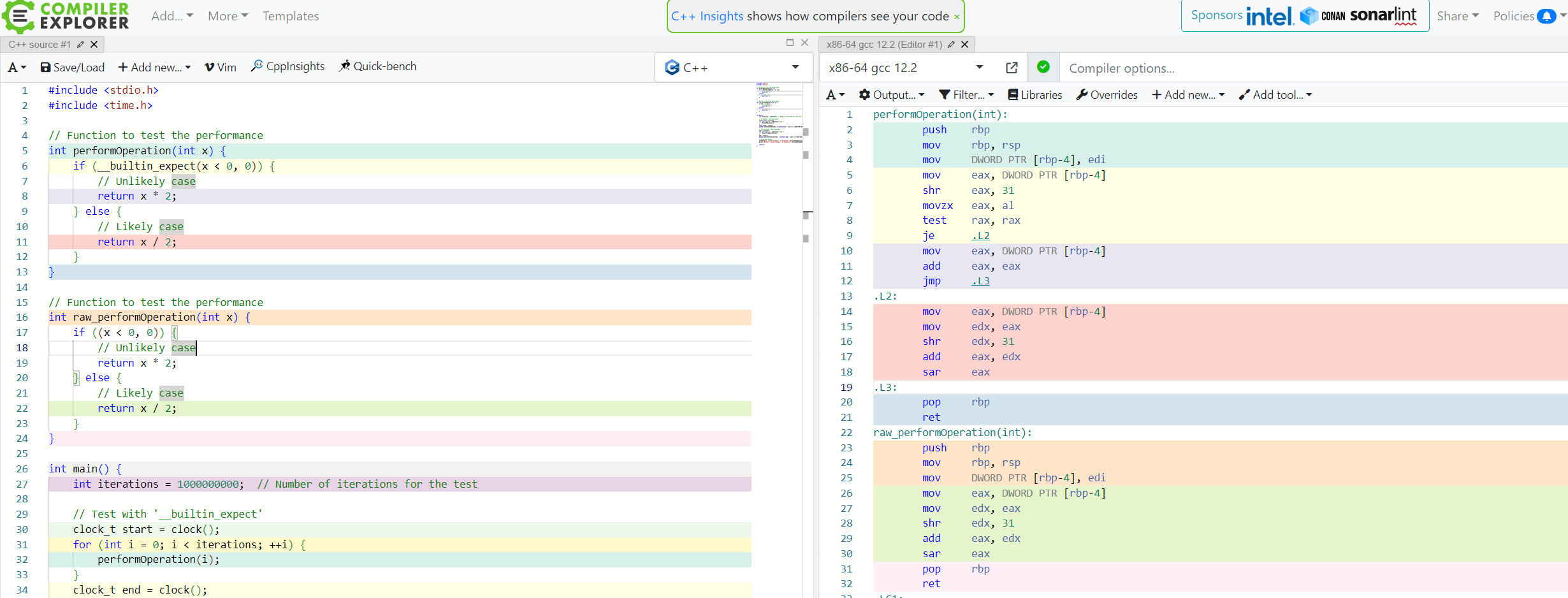 [Transltion from C to assembly]
[Transltion from C to assembly]
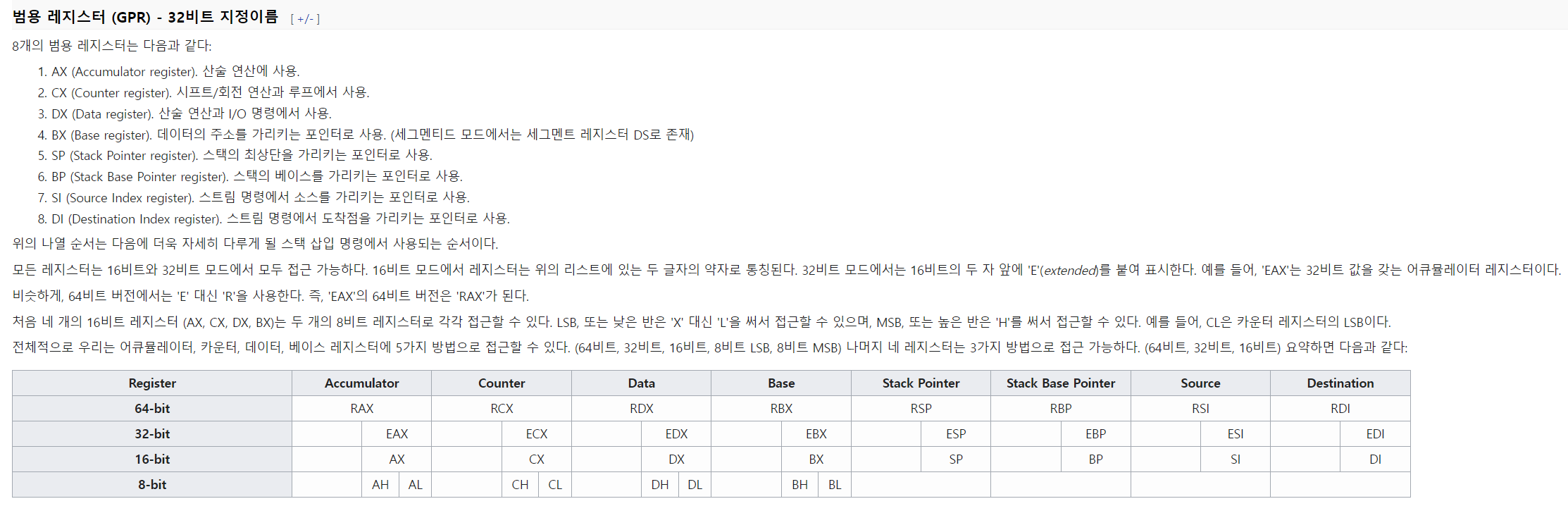 [x86 register set description]
[x86 register set description]
상기 x86 register set의 설명 이미지는 위키피디아를 참고했습니다.
'raw_performOperation'의 Assembly Code
raw_performOperation(int):
push rbp ; 현재의 베이스 포인터 값을 스택에 보관
mov rbp, rsp ; 스택 포인터를 베이스 포인터로 설정
mov DWORD PTR [rbp-4], edi ; 함수 인자를 [rbp-4] 위치에 저장
cmp DWORD PTR [rbp-4], 0 ; [rbp-4]와 0을 비교
jns .L5 ; 만약 비교 결과가 양수이면 .L5로 점프
mov eax, DWORD PTR [rbp-4] ; [rbp-4] 값을 eax 레지스터에 저장
add eax, eax ; eax에 eax의 두 배 값을 저장
jmp .L6 ; .L6로 점프
.L5:
mov eax, DWORD PTR [rbp-4] ; [rbp-4] 값을 eax 레지스터에 저장
mov edx, eax ; edx에 eax 값을 저장
shr edx, 31 ; edx 값을 오른쪽으로 31비트 시프트 (부호 비트 확장)
add eax, edx ; eax에 edx 값을 더함 (음수이면 -1, 양수이면 0)
sar eax ; eax 값을 부호 있는 오른쪽 시프트 (2로 나눔)
.L6:
pop rbp ; 스택에 저장된 베이스 포인터 값을 복원
ret ; 함수 종료'performOperation'의 Assembly Code
performOperation(int):
push rbp ; stack의 base pointer('rbp')를 stack에 save.
mov rbp, rsp ; base pointer('rbp')를 current stack pointer('rsp')로 set.
mov DWORD PTR [rbp-4], edi ; parameter 'x'를 address [rbp-4] (stack - 4byte)에 save.
mov eax, DWORD PTR [rbp-4] ; address [rbp-4]의 parameter 'x'를 eax에 save.
shr eax, 31 ; 'x'의 sign bit을 eax에 save하기 위해 shift right 31-bit을 수행.
movzx eax, al ; 'eax'의 the least sign byte를 'al' register에 sign extension하여 save.
test rax, rax ; 'eax'의 64-bit register인 'rax'의 값을 bitwise AND operation을 수행해서 'x'의 negative bit을 checking.
je .L2 ; 'x'의 sign bit이 not set (non-negative)이면, .L2로 jump.
mov eax, DWORD PTR [rbp-4] ; 'x'가 negative인 경우, stack에 있는 'x' 값을 'eax' register에 save.
add eax, eax ; 'eax'에 대한 double operation.
jmp .L3
.L2: ; "return x / 2;"에 대한 instructions.
mov eax, DWORD PTR [rbp-4] ; 'x'의 value를 'eax' register에 save.
mov edx, eax ; 'eax' register의 'edx' register에 save.
shr edx, 31 ; 'x'의 sign bit checking을 위한 shift right operation.
add eax, edx ; 'edx' register value를 'eax' register에 add opeartion.
sar eax ; 'eax' register에 대해 shift arithmetic right operation. Divide by 2에 대한 operation.
.L3:
pop rbp ; restore the value of base pointer.
ret이렇게만 봐서는 __builtin_expect keyword가 오히려 방해가 되는것처럼 보입니다. 그러나 compiler optimization level을 올려주면 성능 차이를 확인할 수 있습니다. -O1을 적용하는 경우, performOperation은 대략 219.729ms이 걸리고 rawperfromOperation은 222.102ms이 걸리는 것을 확인했습니다. 측정된 시간은 환경에 따라 다르게 측정될 수 있고, branch statement가 많은 program일수록 성능 최적화의 영향이 클 것으로 보입니다.
-O1 Optimization
-O1을 적용하는 경우에 대한 assembly code를 보면 아래와 같은데, 우선 rawperformOperatoin함수에 대한 assembly를 먼저 살펴보겠습니다.
'raw_performOperation'의 Assembly Code
raw_performOperation(int):
test edi, edi ; edi와 edi를 AND 연산하여 결과를 테스트
js .L7 ; 테스트 결과가 부호 비트가 설정된 음수라면 .L7로 점프
mov eax, edi ; edi 값을 eax 레지스터로 복사
shr eax, 31 ; eax 값을 오른쪽으로 31비트 시프트 (부호 비트 확장)
add eax, edi ; eax에 edi 값을 더함 (음수이면 -1, 양수이면 0)
sar eax ; eax 값을 부호 있는 오른쪽 시프트 (2로 나눔)
ret ; 함수 종료
.L7:
lea eax, [rdi+rdi] ; rdi의 두 배 값을 eax에 저장
ret ; 함수 종료위 어셈블리 코드는 raw_performOperation 함수의 C 코드 표현에서의 동작을 수행합니다. 함수 인자 x를 테스트하여 음수인 경우는 x * 2를, 양수인 경우는 x / 2를 반환합니다. test와 js 명령을 통해 부호 비트를 테스트하여 조건에 따라 다른 코드 경로로 분기하고, mov, shr, add, sar 명령을 사용하여 적절한 연산을 수행합니다. 최종 결과는 eax 레지스터에 저장되고, 함수가 종료됩니다.
'performOperation'의 Assembly Code
performOperation(int):
mov edx, edi ; edi 값을 edx 레지스터로 복사
shr edx, 31 ; edx 값을 오른쪽으로 31비트 시프트 (부호 비트 확장)
add edx, edi ; edx에 edi 값을 더함 (음수이면 -1, 양수이면 0)
lea eax, [rdi+rdi] ; rdi의 두 배 값을 eax에 저장
sar edx ; edx 값을 부호 있는 오른쪽 시프트 (2로 나눔)
test edi, edi ; edi와 edi를 AND 연산하여 결과를 테스트
cmovns eax, edx ; 테스트 결과가 부호 비트가 설정되지 않은 양수라면 edx 값을 eax로 조건부로 복사
ret ; 함수 종료위 어셈블리 코드는 performOperation 함수의 C 코드 표현에서의 동작을 수행합니다. 함수 인자 x를 테스트하여 음수인 경우는 x / 2를, 양수인 경우는 x * 2를 반환합니다. mov, shr, add, lea, sar, test, cmovns 등의 명령을 사용하여 적절한 연산을 수행합니다. cmovns 명령은 테스트 결과가 부호 비트가 설정되지 않은 양수인 경우에만 실행되며, 해당 경우에는 edx 값을 eax로 조건부로 복사합니다. 최종 결과는 eax 레지스터에 저장되고, 함수가 종료됩니다.
'performOperation' 함수에서는 test와 cmovns 명령을 사용하여 분기 예측이 용이한 형태로 코드를 작성했습니다. test 명령은 분기 조건을 평가하고, cmovns 명령은 분기 예측에 영향을 주지 않고 조건에 따라 값을 복사합니다. 분기 예측을 통해 잘못된 예측으로 인한 지연을 최소화하고 성능을 향상시킬 수 있습니다. 이에 반해 'raw_performOperation' 함수는 명시적인 분기 명령(je, jmp)을 사용하여 분기를 수행하기 때문에 분기 예측이 더 어려울 수 있습니다.
결과적으로, 'performOperation' 함수는 분기 예측을 더 잘 활용할 수 있으며, CPU의 명령어 파이프라인을 효율적으로 사용하여 더 빠른 성능을 보일 수 있습니다.
