
자료형
기본형 변수
논리형 변수: boolean
True, False 값만 저장
문자형 변수: char
'A', '1'와 같은 문자 하나만 저장
정수형 변수: byte,short,int,long
각 변수 표현 범위를 넘는 숫자를 넣게되면 오버플로우가 발생하고, 해당 숫자를 출혁해보면 입력값과 다른 값으로 표현됩니다.
그렇기 떄문에 각 변수들의 표현 범위를 잘 알아야 버그가 생기지 않습니다.
- byte: -128~127
- short(2byte): -32768~32767
- int(4byte): -21억~21억
- long(8byte): 9백경 -> L 접미사 사용해야함(1004L)
실수형 변수: float,double
실수는 표현범위가 매우 넓어서 정수형 변수에서 담지 못할 수 있습니다.
- float(4bytr): 3.4 -10^38~3.410^39 -> f 접미사를 사용해야함(3.14f)
long보다 범위가 크다 (float를 long으로 자동 형변환 불가)
-> 이유는 자바가 부동소수점(소수점이 움직인다)을 사용하기 떄문
부동 소수점 방식: 가수와 지수를 구분해서 저장하고 이값들을 곱한 값을 저장하는 방식

참조형 변수
문자열 변수: String
"test"와 같은 문장을 저장
문장의 끝에 \0(NULL 문자)가 함께 저장이 됩니다.
(몇개의 byte를 쓸지 모르기 떄문에 끝을 표시해야 합니다)
- 참조형 변수 = 주소형 변수
다른 기본형 변수가 실제 값을 저장하는 저장공간 이라면 참조형 변수는 실제 값이 아닌 원본값의 주소값을 저장. - 저장 관점에서 차이점
-기본형 변수: 원본값이 Stack 영역에 있습니다
-참조형 변수: 원본값이 Heap 영역게 있습니다.
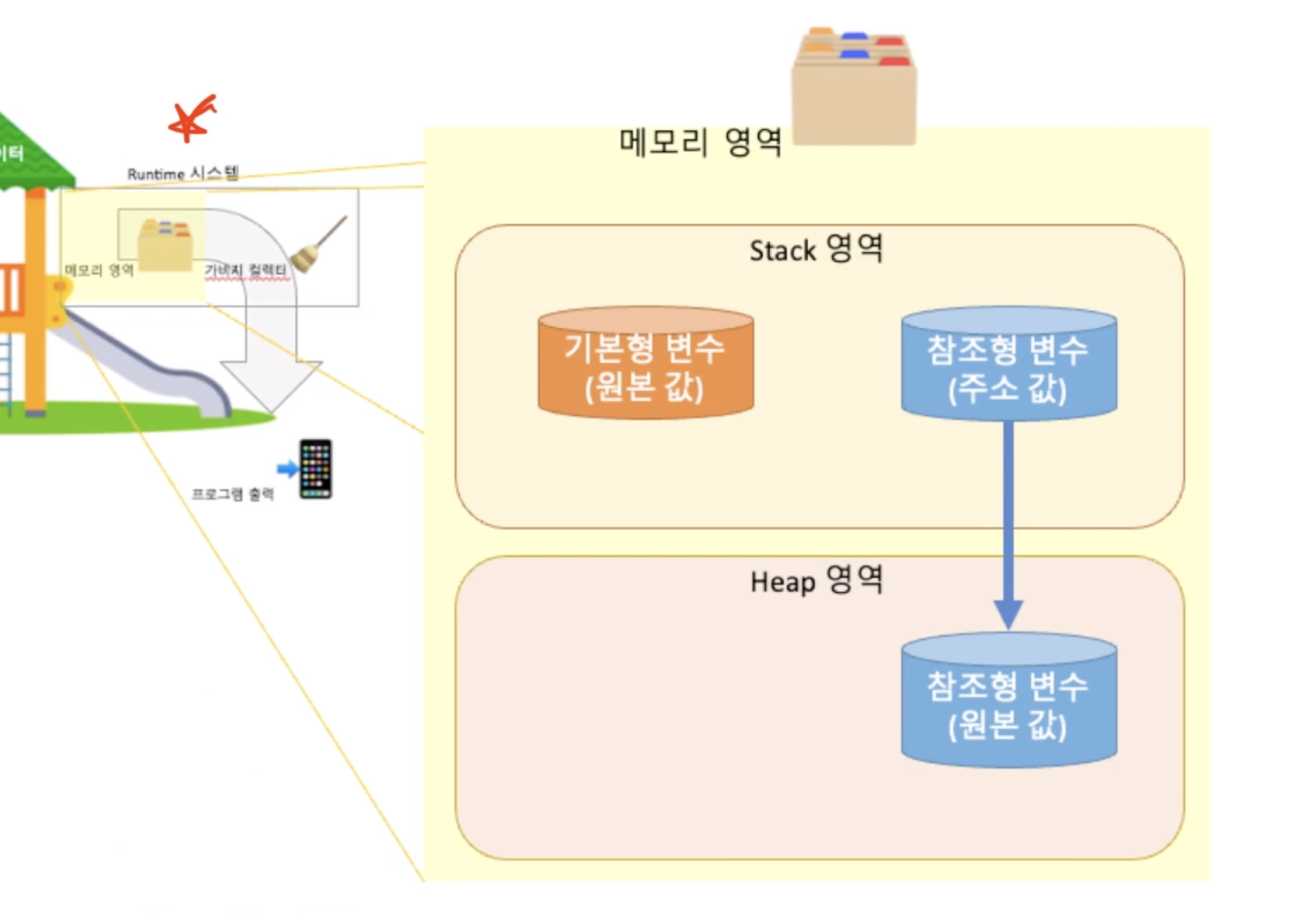
Stack 영역 VS Heap 영역
- Stack의 경우에는 정적(정해져 있는 크기)으로 할당된 메모리 영역
-> 그래서, 크기가 몇 byte인지 정해져있는 기본형 변수를 저장
-> 크기가 정해져 있는 참조형 변수의 주소값도 저장- Heap의 경우에는 동적(알 수 없는 크기)으로 할당된 메모리 영역
->크기가 계속 늘어날 수 있는 참조형 변수의 원본을 저장
기본형 변수 vs 참조형 변수
- 기본형 변수는 '소문자'로 시작하는데 참조형 변수는 '대문자'
- Wrapper class에서 기본형 변수를 감싸줄 떄(boxing), int -> Integer
- 기본형 변수는 값 자체를 저장, 참조형 변수는 별도의 공간에 값을 저장 후 그 주소를 저장
Object, Array, List ...
객체,배열,리스트와 같은 단일 저장공간에 담을 수 없는 값을 저장
래퍼 클래스 변수
래퍼 클래스는 "기본형 변수를 클래스로 한 번 감싸는 변수"
- 기본형 변수 타입명에서 첫글자를 대문자로 바꾸어서 래퍼 클래스를 정의
ex int - > Int
doduble -> Double
...
- 박싱 VS 언박싱
기본 타입에서 래퍼 클래스 변수로 변수를 감싸는 것을 "박싱"이라고 부르며
래퍼 클래스 변수를 기본 타입 변수로 가져오는 것을 "언박싱"이라고 부른다
int number = 21;
Integer num = number; // Boxing
System.out.println(num.intValue()); //Unboxing입력
- Java 프로그램에서는 기본적으로 Scanner.in 객체의 next() 명령을 사용해서 입력받습니다.
Scanner sc = new Scanner(System.in); // Scanner 객체를 new 명령어로 생성합니다.
String input = sc.next(); // sc(Scanner)의 .next(); 를 실행하면 input 변수에 입력한 글자를 받을 수 있습니다.묵시적 형변환(자동 형변환)
Java 프로그램 안에서 자동으로 형을 바꿔주는 케이스
변수 타입별 크기 순서
byte(1) -> short(2) -> int(4) -> long(8) -> float(4) -> double(8)
변수 크기가 큰 순서대로 자동으로 형변환이 된다
EX
int intNumber = 100;
long longNumber = intNumber;더큰 표헌범위를 가진 타입으로 변환되는것이라 값의 손실이 없습니다
그래서 컴파일러가 자동으로 형변환을 해준다.
명시적 형변환(강제 형변환 = 캐스팅)
정수 -> 실수
int intNumber = 10;
double doubleNumber = (double)intNumber;
System.out.println("double number: " + doubleNumber);더 작은 표현범위를 가진 타입으로 변환되는것이라 값의 손실이 생김
그러기 떄문에 자동으로 형변환 해주지 않고 개발자가 선택하여 형변환 시켜줘야함
