Loading
Indexing
개념
인덱스(Index)는 사용자 쿼리에 대해 관련 있는 문맥을 빠르게 검색할 수 있도록 해주는 데이터 구조입니다. 라마인덱스(LlamaIndex)에서 인덱스는 검색-증강 생성(RAG) 사용의 기초입니다.
높은 수준에서 인덱스는 문서(Document)에서 생성됩니다. 이들은 쿼리 엔진(Query Engines)과 채팅 엔진(Chat Engines)을 구축하는 데 사용되며, 이를 통해 데이터에 대한 질문과 답변, 채팅이 가능해집니다.
인덱스는 노드객체(원본 문서의 chunk를 대표하는)에 데이터를 저장하며, 추가적인 구성 및 자동화를 지원하는 검색기(Retriever) 인터페이스를 노출합니다.
++ 인덱스는 문서의 일부를 나타내는 노드 객체에 데이터를 저장,
++ Node 객체는 원본 문서의 일부를 나타내며, 원본 문서를 작은 덩어리(청크)로 나눈 것이라고 이해
가장 일반적으로 사용되는 인덱스는 VectorStoreIndex이며, 이를 시작하는 가장 좋은 방법은 VectorStoreIndex 사용 가이드를 참조하는 것입니다.
Storing
개념
LlamaIndex는 외부 데이터를 가져오고(ingesting), 인덱싱하고(indexing), 쿼리하는(querying) 고수준의 인터페이스를 제공합니다.
내부적으로, LlamaIndex는 교체 가능한 저장소 구성 요소를 지원하여 다음과 같은 요소들을 사용자 정의할 수 있습니다:
- Document stores: 가져온 문서들(예: Node 객체)이 저장되는 곳
- Index stores: 인덱스 메타데이터가 저장되는 곳
- Vector stores: 임베딩 벡터가 저장되는 곳
- Property Graph stores: 지식 그래프가 저장되는 곳 (예: -- -- PropertyGraphIndex에 사용)
- Chat Stores: 채팅 메시지가 저장되고 구성되는 곳
문서/인덱스 저장소는 공통 키-값(Key-Value) 저장소 추상화에 의존하며, 이는 아래에 더 자세히 설명되어 있습니다.
LlamaIndex는 fsspec이 지원하는 모든 스토리지 백엔드에 데이터를 영구적으로 저장하는 것을 지원합니다. 현재 다음과 같은 스토리지 백엔드를 지원함을 확인했습니다:
- 로컬 파일 시스템
- AWS S3
- Cloudflare R2
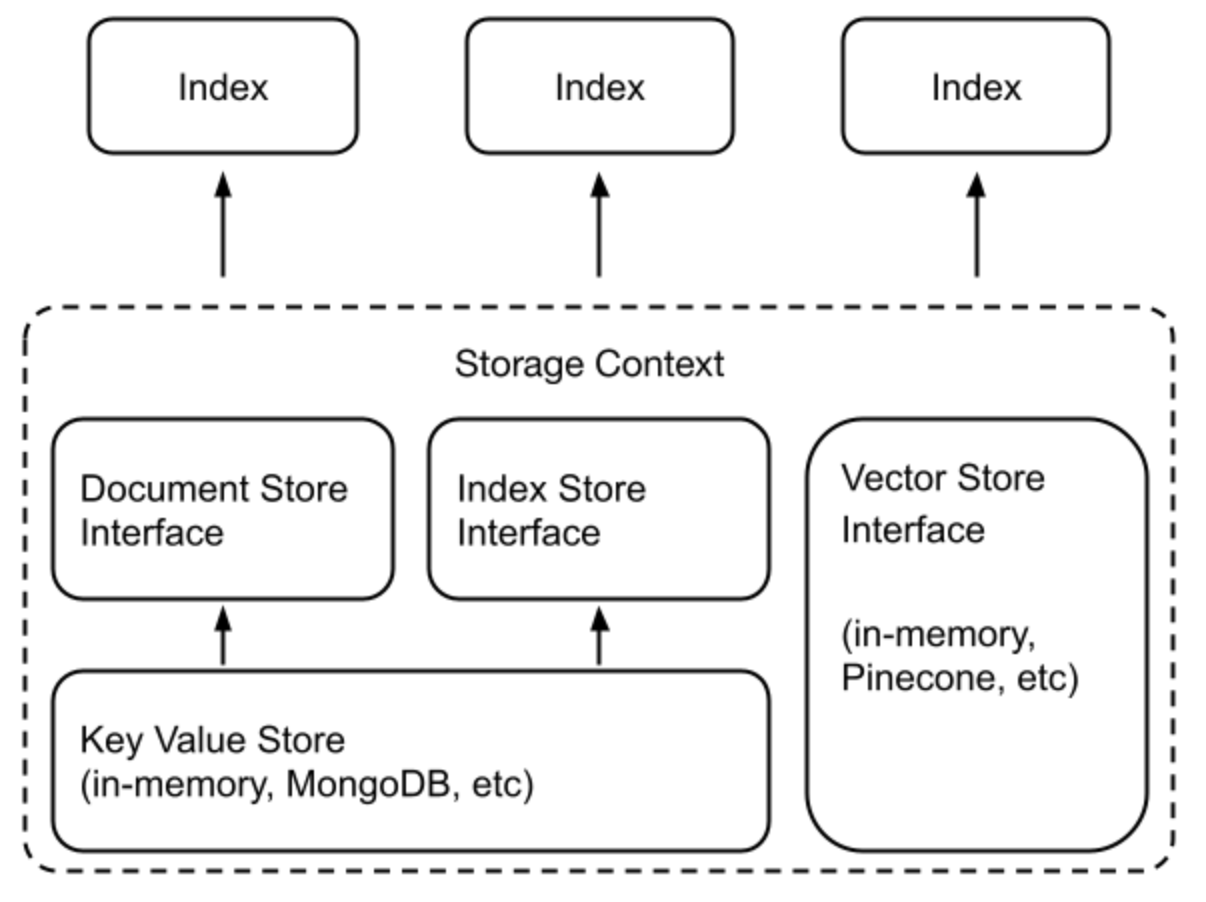
사용 패턴
많은 벡터 저장소(FAISS 제외)는 데이터와 인덱스(임베딩)를 모두 저장합니다. 이는 별도의 문서 저장소나 인덱스 저장소를 사용할 필요가 없음을 의미합니다. 또한, 이 데이터를 명시적으로 저장할 필요도 없으며, 이 과정은 자동으로 이루어집니다. 사용 예시는 새로운 인덱스를 구축하거나 기존 인덱스를 재로드하는 것과 같은 형태를 가집니다
## build a new index
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.deeplake import DeepLakeVectorStore
# construct vector store and customize storage context
vector_store = DeepLakeVectorStore(dataset_path="<dataset_path>")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Load documents and build index
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
## reload an existing one
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)일반적으로 저장소 추상화를 사용하려면 StorageContext 객체를 정의해야 합니다.
from llama_index.core.storage.docstore import SimpleDocumentStore
from llama_index.core.storage.index_store import SimpleIndexStore
from llama_index.core.vector_stores import SimpleVectorStore
from llama_index.core import StorageContext
# create storage context using default stores
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore(),
vector_store=SimpleVectorStore(),
index_store=SimpleIndexStore(),
)Quering
쿼리는 LLM(대규모 언어 모델) 애플리케이션에서 가장 중요한 부분입니다. 배포 가능한 최종 제품을 만드는 방법에 대해 더 알고 싶다면, 쿼리 엔진 및 채팅 엔진에 대한 내용을 확인하세요.
고급 추론을 도구 사용과 결합하고자 한다면, 에이전트(agents) 가이드를 확인해보세요.
쿼리 워크플로우
이벤트 기반의 워크플로우 인터페이스를 사용하여 쉽게 쿼리 워크플로우를 만들 수 있습니다. 자세한 내용은 워크플로우 가이드를 참조하세요.
그 외에도, 쿼리 모듈을 독립적인 구성 요소로 사용하는 방법에 대해 아래에서 확인할 수 있습니다 👇.
쿼리 모듈
- (Query Engines)
- (Chat Engines)
- 에이전트(Agents)
- 검색기(Retrievers)
- 응답 합성기(Response Synthesizers)
- 라우터(Routers)
- 노드 후처리기(Node Postprocessors)
- 구조화된 출력(Structured Outputs)
