
📖 오늘의 학습
- Seaborn, wordcloud
1. Seaborn 라이브러리
- Python의 데이터 시각화 라이브러리
- 다양한 그래프를 커스터마이징하여 그릴 수 있다.
- 아래와 같이 터미널 코드 실행하여 설치
pip install seaborn- 그래프를 그릴 땐 x축과 y축을 명시해주는 것이 좋다.
✔️ 꺾은선 그래프(Line Plot) 그리기
sns.lineplot(x=[1, 3, 2, 4], y=[4, 3, 2, 1])
✔️ 막대 그래프(Bar Plot) 그리기
sns.barplot(x=["Amy","Bob","Cat","Dog"],y=[0.7,0.2,0.1,0.05])
✔️ pyplot을 이용한 그래프 속성 변경
- Seaborn 라이브러리는 matplotlib을 기반으로 만들어졌기 때문에 matplotlib.pyplot의 속성을 변경하여 그래프에 다양한 요소를 변경/추가할 수 있다.
그래프 제목 추가
sns.barplot(x=["Amy","Bob","Cat","Dog"],y=[0.7,0.2,0.1,0.05])
plt.title("BarPlot")
plt.show()
그래프의 x,y축에 설명 추가
sns.barplot(x=["Amy","Bob","Cat","Dog"],y=[0.7,0.2,0.1,0.05])
plt.title("BarPlot")
plt.xlabel("X Label")
plt.ylabel("Y Label")
plt.show()
그래프 축의 범위 지정
sns.lineplot(x=[1, 3, 2, 4], y=[4, 3, 2, 1])
plt.title("Line Plot")
plt.ylim(0,10)
plt.show()
그래프 크기 조정
# 크기를 먼저 지정해주어야 함
plt.figure(figsize = (20, 10))
sns.lineplot(x=[1, 3, 2, 4], y=[4, 3, 2, 1])
plt.title("Line Plot")
plt.ylim(0,10)
plt.show()✔️ 웹 스크래핑으로 얻은 데이터를 Seaborn으로 시각화하기
예제 1) 기상청 날씨(기온) 데이터 꺾은선 그래프로 시각화
1. 웹 스크래핑에 필요한 라이브러리 불러오기
from selenium import webdriver
from selenium.webdriver import ActionChains
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.actions.action_builder import ActionBuilder
from selenium.webdriver import Keys, ActionChains
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By2. 날씨 데이터 가져오기
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://www.weather.go.kr/w/weather/forecast/short-term.do")
driver.implicitly_wait(10)
# 데이터를 가져온 후 개행문자와 필요없는 단위를 잘라낸다
temps = driver.find_element(By.ID, "my-tchart").text
temps = [int(i) for i in temps.replace("℃","").split("\n")]3. 꺾은선 그래프로 나타내기
# x = Elapsed Time(0~len(temperatures)
# y = temperatures
import seaborn as sns
import matplotlib.pyplot as plt
plt.ylim(min(temps)-2, max(temps)+2)
plt.title("Expected Temperature from now on")
sns.lineplot(
x = [i for i in range(len(temps))],
y = temps
)
plt.show()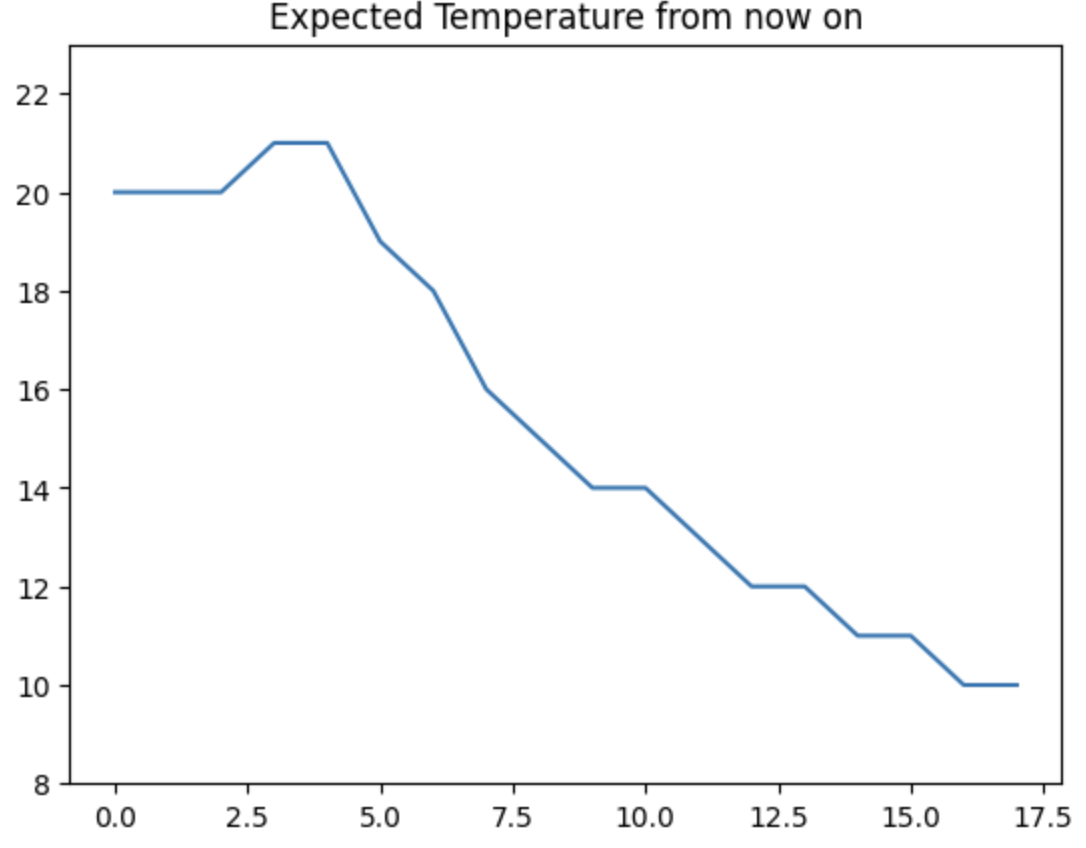
예제 2) 질문게시판 질문tag 빈도 막대 그래프로 시각화
1. 필요한 라이브러리 불러오기
import requests
from bs4 import BeautifulSoup
import time2. 질문 tag 데이터 가져오기
# dict를 만들어 tag의 빈도 수를 센다
frequency = {}
for i in range(1, 11):
res = requests.get(f"https://hashcode.co.kr/?page={i}", user_agent)
soup = BeautifulSoup(res.text, "html.parser")
for t in soup.find_all("ul", "question-tags"):
tag_name = t.find("li").find("a").find("span").text.strip()
frequency[tag_name] = frequency.get(tag_name, 0) + 1
time.sleep(0.5)3. Counter를 사용하여 가장 빈도가 높은 tag를 추출
from collections import Counter
counter = Counter(frequency)
counter.most_common(10)4. 막대 그래프로 그리기
# Seaborn을 이용해 이를 Barplot으로 그립니다.
import seaborn as sns
import matplotlib.pyplot as plt
x = [e[0] for e in counter.most_common(10)]
y = [e[1] for e in counter.most_common(10)]
plt.figure(figsize=(15,10))
plt.title("Frequency of question in Hashcode")
plt.xlabel("Tag names")
plt.ylabel("Frequency of tags")
sns.barplot(
x = x,
y = y
)
plt.show()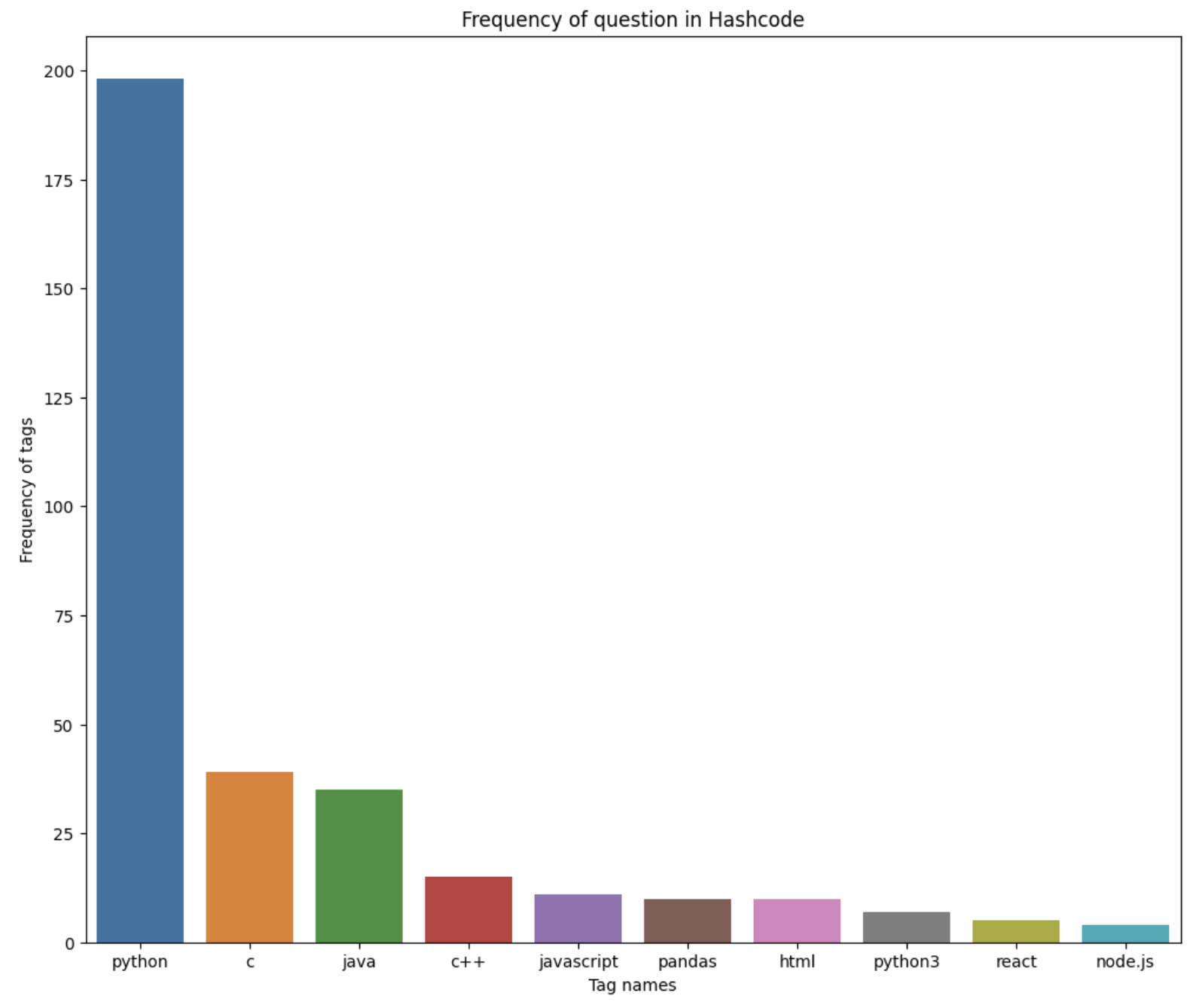
2. Wordcloud 라이브러리
- 자주 등장하는 텍스트를 중요도나 인기도를 고려하여 표기한 텍스트로 이루어진 구름모양의 이미지
WordCloud 생성 절차
- *konlpy 라이브러리로 한국어 문장을 전처리
- Counter를 이용해 빈도수 측정
- WordCloud를 이용해 시각화
* konlp란?
한국어 형태소 분석기 라이브러리로, 주어진 문장에서 명사 등을 뽑아 내는 데에 사용할 수 있다.
🚨 Java가 설치되어 있어야 동작한다.
예제 1) 애국가 가사 wordcloud 만들기
1. 필요한 라이브러리 불러오기
# 시각화에 쓰이는 라이브러리
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 횟수를 기반으로 딕셔너리 생성
from collections import Counter
# 문장에서 명사를 추출하는 형태소 분석 라이브러리
from konlpy.tag import Hannanum2. 형태소 분석기 객체를 사용해서 주어진 문자열에서 명사를 추출
national_anthem = """
동해물과 백두산이 마르고 닳도록
하느님이 보우하사 우리나라 만세
무궁화 삼천리 화려 강산
대한 사람 대한으로 길이 보전하세
남산 위에 저 소나무 철갑을 두른 듯
바람 서리 불변함은 우리 기상일세
무궁화 삼천리 화려 강산
대한 사람 대한으로 길이 보전하세
가을 하늘 공활한데 높고 구름 없이
밝은 달은 우리 가슴 일편단심일세
무궁화 삼천리 화려 강산
대한 사람 대한으로 길이 보전하세
이 기상과 이 맘으로 충성을 다하여
괴로우나 즐거우나 나라 사랑하세
무궁화 삼천리 화려 강산
대한 사람 대한으로 길이 보전하세
"""
hannanum = Hannanum()
nouns = hannanum.nouns(national_anthem)
words = [noun for noun in nouns if len(noun) > 1]
words[:10]3. Wordcloud 그리기
# font를 지정해주지 않으면 한글이 깨지므로 한글 폰트의 경로를 명시한다.
wordcloud = WordCloud(
font_path="/Users/ohyujeong/Library/Fonts/PyeongChangPeace-Bold.otf",
background_color="white",
width=1000,
height=1000,
)
img = wordcloud.generate_from_frequencies(counter)
plt.imshow(img)
예제 2) 질문게지판 질문 키워드로 Wordcloud 만들기
1. 데이터 스크래핑
import requests
from bs4 import BeautifulSoup
import time
questions = []
for i in range(1, 11):
res = requests.get(f"https://hashcode.co.kr/?page={i}", user_agent)
soup = BeautifulSoup(res.text, "html.parser")
for e in soup.find_all("li", "question-list-item"):
questions.append(e.h4.text.strip())
time.sleep(0.5)2. Wordcloud 그리기에 필요한 라이브러리 가져오기
# 시각화에 쓰이는 라이브러리
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 횟수를 기반으로 딕셔너리 생성
from collections import Counter
# 문장에서 명사를 추출하는 형태소 분석 라이브러리
from konlpy.tag import Hannanum3. 형태소 분석기 객체를 사용해서 주어진 문자열에서 명사를 추출 (순환문 사용)
hannanum = Hannanum()
words = []
for q in questions:
nouns = hannanum.nouns(q) # 1번 반복할 때 나온 명사들
words += nouns # 누적해서 나오는 명사들4. Wordcloud 그리기
# 각 단어의 갯수를 count
counter = Counter(words)
wordcloud = WordCloud(
font_path="/Users/ohyujeong/Library/Fonts/PyeongChangPeace-Bold.otf",
background_color="white",
height=1000,
width=1200
)
img = wordcloud.generate_from_frequencies(counter)
plt.imshow(img)
📝 주요메모사항
1. Wordcloud는 Python 3.9까지만 지원되는 문제
- 쓰고 있던 Python의 버전이 3.11이었기 때문에 버전을 변경해야 했다. 버전을 변경하는 방법을 검색하다 보니 pyenv로 Python의 버전을 관리하는 방법을 알게되었다! 다른 글에서 더 자세히 쓸 예정이다.
2. konlpy 라이브러리는 Java가 설치되어야 작동하는 문제
- 그래서 Java를 설치하고 환경변수까지 설정을 마쳤는데도 konlpy를 사용한 코드가 에러가 났다... 다양한 게시물의 해결방법을 따라해보다가 conda를 설치하여 conda의 가상공간(?)에서 jupyter notebook을 실행하여 에러가 났던 블럭을 실행하니 성공했다! 😅 왜 됐는지는 차차 알아가야겠다.
3. conda install, activate
- python가상환경을 생성해주어 내 컴퓨터의 python 버전과 상관없이 여러 버전관리가 용이하다.
conda activate,conda deactivate명령어로 가상환경을 활성화/비활성화 할 수 있다. 데이터 분석에 관한 라이브러리가 가상환경에 설치되어 있어 데이터분석에 많이 활용된다고 한다.
😵 공부하면서 어려웠던 내용
- 아이맥 M1 환경에서 수업을 진행했는데, 다수의 install 해야하는 라이브러리들이나 프로그램들이 M1 환경에서는 다른 환경이랑 다른 경우가 많아 설치할 때마다 검색해서 알아봐야했던게 좀 어려웠다.. 그래도 덕분에 .zshrc 파일에 어떤 내용을 작성하고, 작성한 내용이 어떤 영향을 미치는지 어느정도는 알게 되어 좋았다 😆

거친 돌이 다듬어져 조각이 되듯