🌱 Euron 세미나
32비트 부동소수점 연산을 8비트 정수로 변환하는 방식 사용
- pytorch와 tensorflow의 default data type = fp32
1) QAT: quantization을 함녀서 다시 training => weight와 activation의 값을 조정
2) PTQ: 학습이 끝난 모델에 quantization + 원 모델과 비교평가하는데 쓰이는 calibration datset
🐵 SoTA: State of the art(가장 최신)
+) orthogonal path: 이전 모델과 평행한 방향 - 함께 적용이 가능하다는 것!
🐵 Calibration Data: 원본 데이터와의 차이를 가장 줄일 수 있는 방향으로 데이터셋 선택
- DPM은 Markov Chain Monte Carlo 기반!
- 특정 time step의 데이터를 calibration 데이터셋으로 사용했을 때 성능이 좋았음을 실험적으로 보임
Abstract
최근 Denoising Diffusion Generative 모델이 중요한 성과를 이루었음. 그러나 현재의 방법은 반복적인 노이즈 추정으로 인하여 속도가 매우 느림. 이를 해결하기 위하여 노이즈를 추정하는 네트워크를 압축하여 생성 속도를 가속화하는 모델을 제안함. 이전의 DM(Diffusion Model)들은 샘플링하는 경로에 집중하여 속도를 높였으나, 이 방법은 노이즈를 추정하는 단계에서의 cost가 얼마나 많은지를 고려하지 못했음.
본 논문에서는 Post-Training Quantization(PTQ) 에 주목하여 DM을 가속화함. 노이즈 추적 네트워크의 training 분포가 시간 단계에 따라서 변화하기 때문에 이전의 단일 시간 단계 시나리오를 가정했던 PTQ방법들은 실패함. 따라서 DM에 특화된 PTQ를 고안하기 위해 양자화된 operation, 보정된 데이터셋, 보정된 지표 측면에서 탐구함.
해당 방법은 training 없이 완전 정밀 DM을 8비트 모델로 양자화할 수 있으며, 성능을 유지하거나 향상할시킬 수 있었음. 이 방법은 다른 빠른 샘플링 기법인 DDIM에서도 Plug and Play Module로 적용할 수 있음.
✅ 양자화: 신경망의 가중치 및 활성화 등을 낮은 비트 수의 정수로 근사화하는 프로세스. 신경망을 더 작고 효율적으로 만들어 네트워크의 저장과 실행 비용을 줄일 수 있음. 주로 어떤 신경망을 배포할 때 사용하며, 모델을 압축하는 과정이라고 보면 됨.
1. Introduction
Denosing Diffusion Generative Model이 이미지, 음성, 비디오 등 다양한 생성 작업에서 놀라운 성과를 거두고 있음. GAN보다 우수한 작업을 보이며, 생성된 샘플의 다양성과 품질이 뛰어남.
- DM 생성 과정: 실제 데이터를 점진적으로 가우시안 잡음으로 변환 => 다시 가우시안 잡음에서 실제 데이터를 생성
=> 해당 과정은 수천 번의 time step을 거쳐서 수행되며, 샘플 생성을 위한 estimation 비용이 높고 시간이 많이 소모된다는 단점이 있음.
📌 본 연구는
1) 잡음에서 이미지를 샘플링하는 긴 반복 과정
2) 각 반복에서 잡음을 추정하는 번거로운 네트워크
=> 이렇게 두 가지가 느린 생성의 원인이라고 파악함.
이전의 DM 가속화 방법들은 주로 1에만 초점을 맞추었으나, 후자를 간과함.
⭐ 따라서 PTQ를 DM 가속화에 도입하여 네트워크 압축을 위한 훈련 없는 기술이 필요함을 제안함.
=> PTQ는 DM에서의 구현이 어렵기 때문에 도전적임. DM에 대한 PTQ 설계가 최종 성능에 어떤 영향을 미치는지 조사하고, NDTC라는 DM에 특화된 보정 방법을 제안하여 PTQ4DM이라는 새로운 DM 가속화 방법을 제안함.
2. Related Works
2.1 Diffusion Model Acceleration
이전 연구들은 DM 가속화를 위한 짧은 샘플링 경로를 찾는데 집중하며 DM의 성능을 유지함과 동시에 가속화에 성공함. 그러나 본 연구에서 샘플링 경로를 찾는 것 이외에도 각 잡음 추정 반복에 대한 네트워크 압축을 통해 확산 모델을 더 가속화할 수 있음을 보임.
- PTQ4DM은 빠른 샘플링 방법과 별개의 경로로 Plug and Play 모듈로서 사용도 가능함.
+) 해당 연구가 Post Training Quantizationd을 통한 DM 양자화에 관한 첫 번째 연구임.
2.2 Post-training Quantization
양자화 = nn을 압축하는 가장 효과적인 방법 중 하나임.
- 양자화 방법
1) 양자화 인식 Training(QAT) => 신경망 훈련 단계에서 양자화 고려
2) Post Training 양자화(PTQ) => 훈련 후 네트워크를 양자화
- 시간&계산 적게 소비하여 네트워크 배포에 널리 사용
- 대부분의 작업을 각 층에서의 가중치와 활성화를 위한 양자화 매개변수 설정에 씀
ex. Uniform 양자화(가장 많이 이용): Scaling 계수 s와 Zero point z 이용
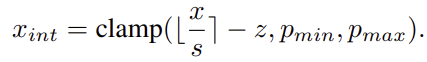
- clam 함수는 반올림된 값 (x/s) - z를 [pmin, pmax]의 범위로 제한함.
⚡ s와 z와 같은 양자화 매개변수 설정 방법: 양자화 전후 텐서의 MSE를 최소화하는 것으로 선택하는 것
- 사용 가능 metric: L1 거리, 코사인 거리, KL divergency 등으로 텐서 거리를 평가
⚡ 네트워크에서 활성화를 계산하기 위해 PTQ에서는 보정 샘플을 이용함.
- ZSQ(Zero-shot Quantization): PTQ의 특수한 경우로, 배치 정규화 레이어의 평균, 분산과 같은 네트워크에 기록된 정보에 따라서 보정 데이터셋을 생성함.
=> 활성화의 분포를 실제 샘프르이 분포와 유사하게 만들기 위해 경사하강법으로 입력 샘플을 생성함.
📌 DM에서의 이미지 생성은 네트워크 추론만 사용한다는 점에서 위의 ZSQ와는 다름.
3.1 PTQ on Diffusion Models
3.1 Preliminaries
- DM에 대한 설명으로 넘어감.
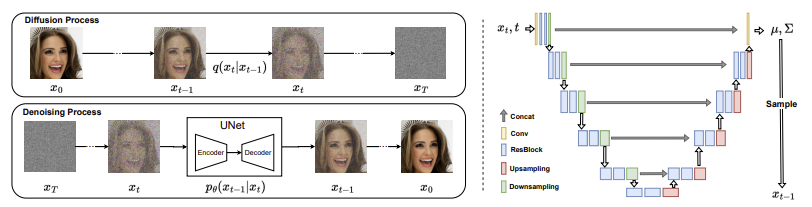
- DM은 잘 훈련된 노이즈 추정 모델 pθ(xt−1|xt)을 얻게 되는데, 이후 무작위 노이즈가 주어지면 pθ(xt−1|xt)에서 xt−1을 반복 샘플링하여 x0을 받을 때까지 노이즈를 제거하는 과정을 통해 샘플을 생성함.
-> 반복 과정이 매우 길고, 각 반복에서 노이즈 추정 네트워크는 매우 복잡하여 비용이 높음
PTQ
훈련된 네트워크에 대해서 각 레이어의 가중치 텐서와 활성화 텐서에 대한 양자화 매개변수를 선택함.
- 가중치에는 직접 적용
- 활성화 텐서에 대한 양자화는 입력이 없는 상태에서는 불가능하니까, 보정 데이터셋을 사용함
PTQ는 일반적으로 3단계로 네트워크를 양자화하게 됨.
3.2 Exploration on Operation Selection
DM에서는 이미지 생성 과정을 분석하여 어떤 작업을 양자화할지 결정 => xt에서 xt−1을 반복적으로 생성 주목
⚡ DM의 특징
- 각 타임 스텝에서 네트워크의 입력은 xt와 t이고 출력은 평균 µ와 분산 Σ
- xt-1은 정의된 분포에서 샘플링
- 유사 CNN 아키텍처인 U-Net 사용
📌 Convolution Layer와 FC는 양자화되어야 하고, BN은 Convolution Layer로 통합할 수 있음.
=> 결론적으로는 µ, Σ 및 xt−1을 생성하는 작업만 양자화하여 이들이 양자화에 민감하지 않으며 양자화가 가능함을 확인함.
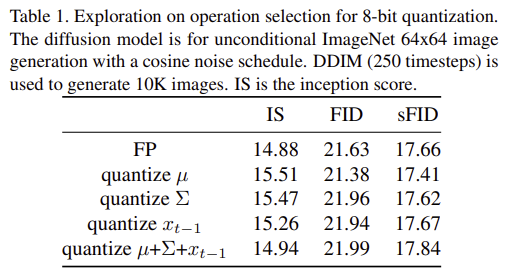
- IS: Inception Score - 이미지 생성 모델의 품질을 평가하는 지표; 품질과 다양성
- FID: 실제 이미지 분포와 생성된 이미지 분포 간의 프레쳇 거리
- sFID: FID의 변형으로 이미지 집합에서의 특정 측면을 측정하기 위해 FID 보완용
양자화를 하더라도 IS, FID, sFID의 변화가 거의 없음을 확인함.
3.3 Exploration on Calibration Dataset
DM을 양자화하기 위한 적절한 calibration 샘플 수집 방법을 확인
calibration: 측정 장비나 시스템의 정확성을 확인하거나 조정하는 과정 - 실제 값과 얼마나 일치하는가를 확인하여 정확한 결과를 보장하는 것. 특히 양자화에서는 적절한 양자화 매개변수를 선택하기 위해 calibration 데이터셋을 사용하여 양자화 과정을 보정함.
- Calibration 샘플의 분포 = 실제 데이터의 분포와 유사 => 양자화 오차 최소화
📌 확보된 Calibration 데이터셋의 크기가 매우 작고, 실제 데이터셋을 대표하지 못할 경우 = Overfit 문제 발생 = DM에 효과적인 데이터셋 수집 방법 필요
관찰0.
활성화 분포가 time step에 따라서 변화하므로 이에 맞춰 활성화 분포 조사
- 다양한 시간 단계에서 출력 분포 분석 ex. t1 = 0.1T 및 t2 = 0.9T일 때 pθ(xt1−1|xt1) 및 pθ(xt2−1|xt2)의 출력 활성화 분포를 분석
=> 이론 상으로는 분포가 time step에 따라서 변화한다면 이전의 PTQ Calibration을 구하기 어려움.(시간에 따라 불변인 Calibration을 위해 제안되었었기 때문)
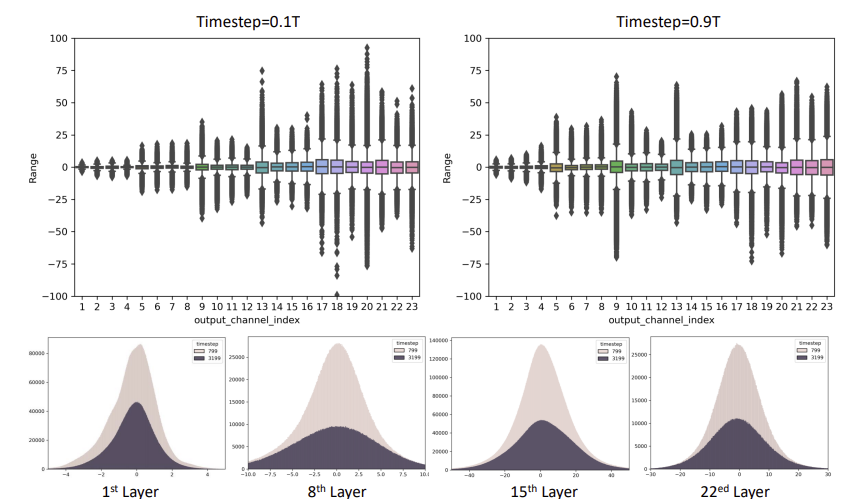
1) Box Plot: 중앙값에 대하여 분포의 range가 매우 크다는 것을 관찰할 수 있음
2) Histogram: time step에 따라서 변화가 극적으로 바뀌는 것을 관찰할 수 있음
📌 전통적인 single-time-step PTQ calibration 방법은 DM에 적용하기 어려움.
관찰1.
Diffusion Process와 노이즈 입력은 양자화된 디바이스 보정에 더 효과적 => 샘플은 보정에 더 유용한 결과를 제공함.
- 비교 실험을 통하여 기존 이미지 대신 가우시안 노이즈를 사용하는 방법이 더 나은 결과 도출함을 확인함.(Image + Gaussian Noise)
📌 Training data의 원시 이미지 이용 < 노이즈 입력을 활용 -> 양자화된 모델의 보정에 더 적합
관찰2.
실제 이미지 x0에 가까운 샘플 xt는 보정에 더 유리함을 발견 => DM의 PTQ 보정 기준을 설정
-
양자화된 DM은 time step t에서 샘플로 보정됨 = 단순 PTQ-for-DM 기준
-
가우시안 노이즈 XT ~ N(0, 1)에 대하여 전체 노이즈 추정 네트워크를 사용하여 Calibration 세트로 xt 집합을 생성함 => 다양한 time step에 대하여 실험 진행
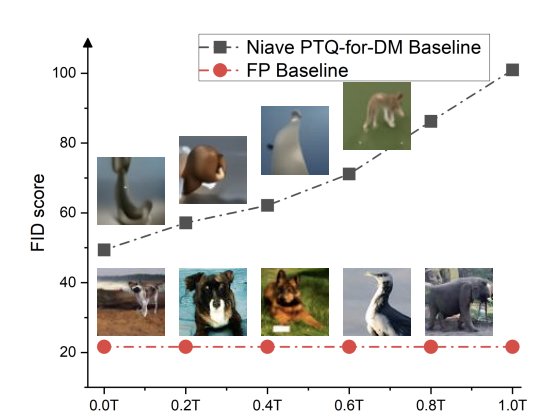
📌 PTQ 보정이 time step t가 실제 이미지 x0에 가까워질수록 더 도움이 된다는 사실을 확인함
=> t가 감소함에 따라, 네트워크 pθ(xt−1|xt)의 출력 분포가 실제 이미지의 분포와 유사해지며, 이는 이미지 생성 과정에서 더 중요한 단계라는 것
관찰3.
하나의 time step에서 생성된 샘플 데이터셋 대신에 보정 샘플은 다양한 time step으로 구성되어야 함.
-
과거와 달리 다중 time step을 위하여 수집되었으므로 DM을 위한 보정 데이터셋은 다양한 시간 단계의 샘플을 포함해야 함.
-
가설 검증을 위한 직관적인 방법: time step에서 균일하게 샘플링된 t를 생성한 후, 가우시안 노이즈 ti를 고려하여 샘플 생성하여 차이를 비교
📌 가우시안 노이즈로 생성된 보정 세트는 time step 범위를 포괄하므로 보정 샘플이 시간 단계의 차이를 반영할 수 있음.
=> time step의 차이를 반영하는 보정 샘플의 효과를 입증함.
Normally Distributed Time-step Calibration
⚡ 위의 내용을 고려한 보정 샘플의 만족 조건:
(1) 전체 정밀도 DM을 사용하여 노이즈 xT로부터 생성된 노이즈 제거 과정에 의해 생성된 샘플
(2) x0에 상대적으로 가까우며 xT로부터는 멀리 떨어진 위치에 있는 샘플
(3) 다양한 time step을 포함하는 샘플
=> (2)와 (3)은 동시에 충족될 수 없음
NDTC: DM 특정 보정 세트 수집 방법 제안
- 보정 세트가 노이즈 제거 과정에서 생성되며, time step t는 비대칭 정규 분포에서 샘플링 됨.
=> time step 범위에서 비대칭 정규 분포를 따르는 샘플 ti를 생성하고, 이를 통하여 xti를 생성함.
4. More Experiments
본 연구에서는 CIFAR10 이미지, ImageNet 이미지를 생성하는 DM을 선택함
=> DDIM time step 4000, 100 단계 모델 이용 + 1024개의 보정 샘플 사용, 8비트로 양자화
=> 비교를 위하여 10,000개 이미지 샘플링
양자화된 8비트 DDPM이 전체 정밀도 DDPM을 능가하는 결과도 나타남
5. Conclusion
노이즈에서 이미지를 샘플링하는데 시간이 오래 걸리는 문제를 DM 가속화 작업의 후자에 맞추어 탐구함. Pre-Training Quantization for Diffusion Models - PTQ4M을 제안하여 성능 저하가 없는 상태로 직접 양자화가 가능함을 보임. 또한, DDIM과 같은 다른 빠른 샘플링 방법에 추가도 가능하였음.
🐵 논의해보고 싶은 점: 모델을 양자화한다는 것을 해당 논문으로 처음 접해보았는데, 양자화 이외에도 다른 압축방법에는 무엇이 있을지 궁금하다.
