부제: 복잡한 Conversational AI, NeMo와 함께라면 A부터 Z까지 손쉽게!
1. 서론: 왜 지금 NeMo에 주목해야 하는가?
"ChatGPT와 같은 대화형 AI, 직접 만들어볼 수는 없을까?"
생성 AI 시대가 도래하면서 많은 개발자들이 혁신적인 아이디어를 품고 있습니다. 하지만 아이디어를 현실로 만드는 과정은 결코 만만치 않습니다. 대규모 언어 모델(LLM)이나 음성 AI 모델을 밑바닥부터 훈련하는 것은 상상 이상의 복잡성, 막대한 컴퓨팅 자원, 그리고 긴 개발 기간을 요구합니다. 데이터 정제, 분산 학습 설정, 모델 최적화 등 수많은 난관이 아이디어를 실제 서비스로 구현하는 길을 가로막습니다.
이러한 장벽을 허물기 위해 NVIDIA가 제시하는 해답이 바로 NVIDIA NeMo 프레임워크입니다. NeMo는 연구자와 개발자가 고성능 생성 AI 모델을 효율적으로 구축(Build), 맞춤화(Customize), 배포(Deploy)할 수 있도록 지원하는 엔드투엔드(End-to-End) 프레임워크입니다.
이 글에서는 NeMo의 핵심 개념을 명확히 이해하고, 실제 개발 환경을 구축하여 간단한 예제까지 실행해보는 것을 목표로 합니다. NeMo가 어떻게 여러분의 AI 개발 여정을 가속화할 수 있는지 함께 알아보겠습니다.
2. NVIDIA NeMo 프레임워크란?
NeMo를 한 문장으로 정의하면 "확장 가능하고(Scalable) 클라우드 네이티브(Cloud-Native)인 생성 AI 프레임워크"입니다. 이는 NVIDIA의 강력한 GPU 기술과 방대한 AI 생태계를 기반으로, 대규모 모델의 전체 수명 주기(데이터 준비부터 훈련, 배포까지)를 관리하도록 설계되었다는 의미입니다.
NeMo의 핵심 철학은 "바퀴를 재발명하지 마세요" 입니다. 개발자는 아무것도 없는 상태에서 시작하는 대신, NVIDIA가 미리 훈련한 강력한 사전 훈련 모델(Pre-trained Models)을 기반으로 개발을 시작할 수 있습니다. 그리고 필요에 따라 손쉽게 미세 조정(Fine-tuning)하여 특정 도메인이나 작업에 최적화된 맞춤형 모델을 만들 수 있습니다. 이러한 모듈화된 접근 방식은 개발 생산성을 극적으로 향상시킵니다.
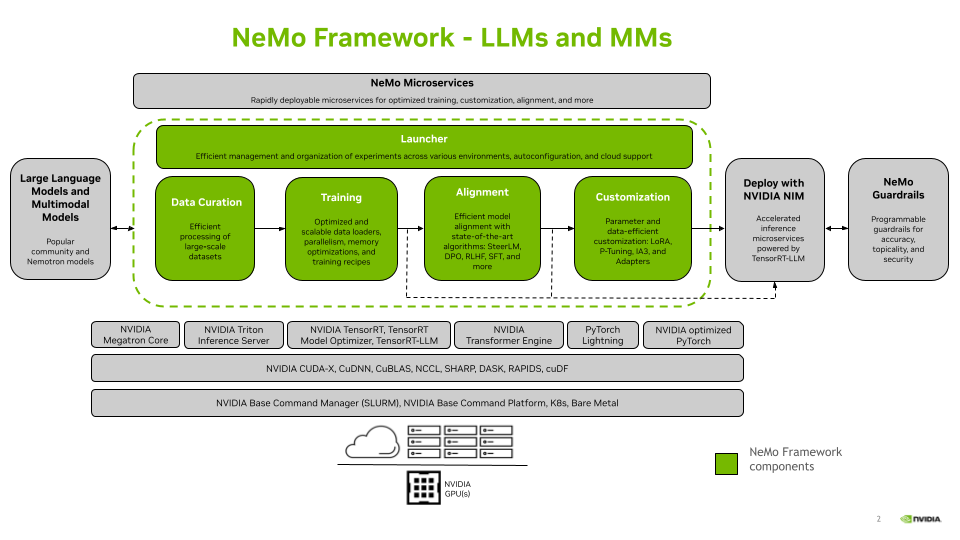
주요 지원 영역:
- 자동 음성 인식 (ASR): 음성을 텍스트로 변환
- 자연어 처리 (NLP) & 대규모 언어 모델 (LLM): 텍스트를 이해하고 생성
- 텍스트 음성 변환 (TTS): 텍스트를 자연스러운 음성으로 합성
- 멀티모달 (Multimodal): 텍스트, 이미지, 음성 등 여러 종류의 데이터를 동시에 처리
3. 핵심 구성 요소 심층 분석
NeMo는 크게 세 가지 핵심 기둥을 중심으로 구성되어 있습니다. 각 구성 요소가 어떤 기능과 강점을 가지고 있는지 자세히 살펴보겠습니다.
3.1. 자동 음성 인식 (ASR: Automatic Speech Recognition)
ASR은 사람의 음성을 정확한 텍스트로 변환하는 기술입니다. NeMo는 이 분야에서 단순한 변환을 넘어선 강력한 기능들을 제공합니다.
-
NeMo의 강점:
- 고성능 사전 훈련 모델: 다양한 언어와 소음이 섞인 환경에서도 높은 정확도를 보이는 모델들을 기본으로 제공합니다.
- 타임스탬프(Timestamp) 기능: 단순히 전체 텍스트만 출력하는 것이 아니라, 각 단어 또는 문장이 오디오의 어느 시점에 나타나는지 정확한 시간 정보를 추출합니다. 이 기능은 미디어 분석, 자동 자막 생성, 데이터 라벨링 작업에 매우 유용합니다.
- 전문 도구 제공:
NeMo Forced Aligner: 기존 오디오 파일과 텍스트 스크립트가 있을 때, 둘 사이의 싱크를 자동으로 맞춰주는 도구입니다.Speech Data Processor: 대용량 음성 데이터의 전처리(자르기, 필터링 등)를 위한 효율적인 스크립트를 제공합니다.ASR Evaluator: 개발된 ASR 모델의 성능(단어 오류율 등)을 정량적으로 평가하기 위한 다양한 벤치마크와 도구를 지원합니다.
-
주요 활용 사례: 실시간 회의록 자동 작성, 음성 명령 인터페이스, 동영상 자동 자막 생성, 콜센터 통화 내용 분석.
3.2. 자연어 처리 및 LLM (NLP & Large Language Models)
NLP 및 LLM은 텍스트 데이터를 이해, 요약, 번역하고 새로운 텍스트를 생성하는, 생성 AI의 핵심 기술입니다. NeMo는 이 복잡한 과정을 체계적인 워크플로우로 지원합니다.
- NeMo의 엔드투엔드 워크플로우:
- 데이터 큐레이션 (Data Curation): 고품질 모델은 고품질 데이터에서 나옵니다.
NeMo Curator라는 특화된 도구를 사용하면, 웹에서 수집한 방대한 텍스트 데이터셋의 품질을 개선하고, 중복을 제거하며, 특정 기준에 따라 필터링하는 작업을 체계적으로 수행할 수 있습니다. - 훈련 및 맞춤화 (Training & Customization):
- 지도 미세 조정 (Supervised Fine-Tuning, SFT): 특정 작업(예: 고객 문의에 대한 답변 생성, 긴 글 요약)에 맞게 모델 전체를 추가 학습시키는 방법입니다. 모델의 성능을 특정 작업에 깊게 최적화할 수 있습니다.
- 파라미터 효율적 미세 조정 (Parameter-Efficient Fine-Tuning, PEFT): LoRA, Adapter와 같은 기술을 활용하여 거대한 모델의 일부 파라미터(전체의 1% 미만)만 업데이트하는 방식입니다. 적은 컴퓨팅 자원과 시간으로도 빠르고 효율적인 맞춤화가 가능하여, 최근 가장 각광받는 기법 중 하나입니다.
- 지원 모델 (Supported Models): NeMo는 Llama, Mistral, Gemma 등 최신 오픈 소스 LLM뿐만 아니라, NVIDIA가 직접 개발한 모델까지 폭넓게 지원하여 선택의 유연성을 제공합니다.
- 데이터 큐레이션 (Data Curation): 고품질 모델은 고품질 데이터에서 나옵니다.
| 모델 계열 | SFT 지원 | PEFT 지원 | 배포 최적화 (TensorRT-LLM) |
|---|---|---|---|
| Llama 2/3 | ✅ | ✅ | ✅ |
| Mistral | ✅ | ✅ | ✅ |
| Mixtral 8x7B | ✅ | ✅ | ✅ |
| Gemma | ✅ | ✅ | ✅ |
| NV-Command | ✅ | ✅ | ✅ |
3.3. 텍스트 음성 변환 (TTS: Text-to-Speech)
TTS는 텍스트를 사람처럼 자연스러운 음성으로 변환하는 기술입니다. NeMo TTS는 기계적인 목소리를 넘어, 감정이 풍부하고 명료한 고품질 음성을 생성하는 데 중점을 둡니다.
-
NeMo의 강점:
- 고품질 음성 생성: 기본으로 제공되는 모델만으로도 매우 자연스럽고 듣기 편한 음성을 만들 수 있습니다.
- 음성 맞춤화 (Voice Cloning/Customization): 단 몇 분 분량의 소량의 음성 데이터만으로도 특정 화자(예: 기업의 브랜드 보이스, 특정 인물)의 목소리를 복제하거나, 완전히 새로운 스타일의 음성을 생성하는 것이 가능합니다.
Text Normalization Tool: 텍스트를 음성으로 변환하기 전, 문맥에 맞게 적절히 변환하는 것은 음성 품질에 매우 중요합니다. NeMo는 "123달러"를 "백이십삼 달러"로, "Dr."를 "Doctor"로 변환하는 등 복잡한 텍스트 정규화 규칙을 쉽게 처리할 수 있는 도구를 제공합니다.
-
주요 활용 사례: AI 비서 목소리, 오디오북 자동 제작, IVR(전화 자동응답 시스템), 교육 및 뉴스 콘텐츠 내레이션.
4. 아키텍처 및 사용법: 개발자는 NeMo를 어떻게 사용하는가?
NeMo는 강력한 기능을 갖추었지만, 개발자가 이를 쉽고 직관적으로 사용할 수 있도록 설계되었습니다.
핵심 API: NeMo AutoModel
NeMo AutoModel은 개발자가 NeMo를 사용하는 가장 쉽고 강력한 방법입니다. Hugging Face 라이브러리의 AutoModel 클래스에 익숙한 개발자라면 쉽게 이해할 수 있습니다. 단 몇 줄의 코드로 NVIDIA의 사전 훈련된 모델을 로드하고, SFT나 PEFT와 같은 미세 조정 작업을 간편하게 실행할 수 있도록 설계된 고수준 API입니다. 복잡한 분산 학습 환경 설정 등을 자동으로 처리해주므로, 개발자는 모델 로직 자체에 집중할 수 있습니다.
두 가지 실행 방식
NeMo는 개발자의 필요에 따라 두 가지 주요 실행 방식을 제공합니다.
-
NeMo Run(CLI 기반 런처):- 터미널에서 명령어 한 줄로 훈련이나 추론 작업을 실행하는 방식입니다. NVIDIA가 제공하는 최적화된 설정 파일(레시피)을 사용하여,
nemo run training --config-name=my_sft_config.yaml ...과 같은 형태로 실행합니다. 표준화된 작업을 코드를 거의 수정하지 않고 빠르게 실행하고 싶을 때 매우 유용합니다.
- 터미널에서 명령어 한 줄로 훈련이나 추론 작업을 실행하는 방식입니다. NVIDIA가 제공하는 최적화된 설정 파일(레시피)을 사용하여,
-
NeMo 2.0 API(프로그래밍 방식):- Python 스크립트나 Jupyter 노트북에서
import nemo.automodel과 같이 NeMo의 기능을 직접 라이브러리로 임포트하여 사용하는 방식입니다. 개발자가 직접 커스텀 로직을 추가하거나 기존 애플리케이션에 NeMo를 통합할 때 높은 유연성을 제공합니다.
- Python 스크립트나 Jupyter 노트북에서
모델 배포 (Deployment): 훈련이 끝이 아니다!
훌륭한 모델을 훈련했다면, 이제 실제 서비스에 배포해야 합니다. NeMo는 훈련된 모델을 실제 프로덕션 환경에 배포하기 위한 다양한 고성능 옵션을 제공합니다.
| 배포 옵션 | 특징 | 추천 대상 |
|---|---|---|
| NVIDIA NIM | 최적화된 AI 모델을 표준화된 컨테이너(마이크로서비스)로 제공. 쿠버네티스 환경에 가장 쉽고 빠르게 배포 가능. | 클라우드 네이티브 환경에서 빠르고 안정적인 배포를 원하는 개발자. |
| NVIDIA Riva | 실시간 음성 AI(ASR/TTS) 서비스에 특화된 고성능 추론 SDK. | 낮은 지연 시간(Low-latency)이 절대적으로 중요한 음성 챗봇, 콜센터 솔루션. |
| TensorRT-LLM | NVIDIA GPU에서 LLM 추론 성능을 극한으로 최적화하는 오픈소스 라이브러리. | 최대 처리량과 최소 지연 시간이 필요한 고성능 LLM 서비스 구축 시. |
| vLLM | PagedAttention 등 최신 기술을 활용하는 인기 있는 오픈소스 추론 라이브러리. NeMo와의 호환성을 제공. | 오픈소스 생태계와의 유연한 통합을 선호하고, 커뮤니티의 최신 기술을 활용하고 싶은 개발자. |
5. 실전! NeMo 개발 환경 구축 및 예제
이제 이론을 넘어 직접 NeMo를 사용해보겠습니다.
5.1. 개발 환경 구축
NeMo를 시작하는 가장 간단하고 확실한 방법은 NVIDIA NGC(NVIDIA GPU Cloud)에서 제공하는 공식 도커 컨테이너를 사용하는 것입니다. 복잡한 라이브러리 의존성 문제를 완벽하게 해결해 줍니다.
-
사전 준비물:
- NVIDIA GPU (최신 드라이버 설치 완료)
- Docker
- NVIDIA Container Toolkit
-
설치 과정 (단계별 명령어):
-
NGC에서 NeMo 컨테이너 이미지 다운로드:
docker pull nvcr.io/nvidia/nemo:latest -
컨테이너 실행:
# 모든 GPU를 사용하고, Jupyter Notebook 접속을 위해 8888 포트를 포워딩합니다. docker run --gpus all -it --rm -p 8888:8888 nvcr.io/nvidia/nemo:latest /bin/bash
이제 여러분은 NeMo의 모든 도구와 라이브러리가 완벽하게 준비된 환경에 들어왔습니다.
-
5.2. 간단한 코드 예제: AutoModel로 LLM 미세 조정하기
작은 규모의 사전 훈련된 모델을 가지고, 우리가 원하는 형식의 데이터로 간단히 SFT(지도 미세 조정)를 수행하는 과정을 코드로 살펴보겠습니다.
-
목표: 사전 훈련된 LLM을 특정 질문/답변 스타일로 미세 조정하기
-
Python 코드 스니펫 (Jupyter Notebook 또는 Python 스크립트에서 실행):
from nemo.collections import llm import nemo_run as run nodes = 1 gpus_per_node = 1 # Note: we use peft=None to enable full fine-tuning. recipe = llm.hf_auto_model_for_causal_lm.finetune_recipe( model_name="meta-llama/Llama-3.2-1B", # The Hugging Face model-id or path to a local checkpoint (HF-native format). dir="/ft_checkpoints/llama3.2_1b", # Path to store checkpoints name="llama3_sft", num_nodes=nodes, num_gpus_per_node=gpus_per_node, peft_scheme=None, # Setting peft_scheme=None disables parameter-efficient tuning and triggers full fine-tuning. ) # Add other overrides here ... run.run(recipe)
6. 결론: NeMo와 함께 열어가는 생성 AI의 미래
이번 여정을 통해 우리는 NeMo가 단순한 라이브러리가 아니라, 데이터 준비부터 훈련, 맞춤화, 그리고 최종 배포까지 생성 AI 개발의 전 과정을 아우르는 강력한 플랫폼임을 확인했습니다.
- 핵심 요약:
AutoModel과 같은 높은 수준의 API는 개발의 복잡성을 크게 낮춰줍니다.- PEFT와 같은 효율적인 맞춤화 기술은 제한된 자원으로도 고성능 모델을 만들 수 있게 합니다.
- NIM, Riva, TensorRT-LLM 등 다양한 배포 옵션은 개발된 모델을 실제 서비스로 연결하는 마지막 마일을 안정적으로 책임집니다.
NeMo는 NVIDIA의 전체 AI 생태계와 긴밀하게 통합되어 계속해서 빠르게 발전할 것입니다. 개발자들은 NeMo를 통해 더 적은 노력으로 더 강력하고 창의적인 AI 애플리케이션을 만들 수 있는 새로운 가능성을 얻게 되었습니다.
이 글을 통해 NeMo의 잠재력을 엿보셨다면, 이제 직접 경험해볼 차례입니다. 지금 바로 NVIDIA NGC에서 NeMo 컨테이너를 다운로드하고, 공식 문서에 풍부하게 제공되는 튜토리얼과 Jupyter 노트북 예제를 따라 여러분만의 생성 AI 모델을 만들어보세요.
- NVIDIA NeMo 프레임워크 공식 문서:
https://docs.nvidia.com/nemo-framework/user-guide/latest/overview.html
