연산자 목록
sql 에는 수많은 연산자가 있다
아래를 외운다라는 개념보다는 하나하나 정복해 나가는 방식으로 배우면 좋을 것 같다.
- 논리, 비교 연산자와 조건문 함수
- 배열 연산자와 함수
- JSON 연산자와 함수
- 날짜 및 시간 연산자와 함수
- 자주 쓰이는 연산자와 함수
논리 비교 연산자
논리 비교 연산자 사용 시 주의할 점은 NULL 값의 유무이다.
-
AND 연산자 | false, null, true 우선순위로 잡힌다고 생각하면 편하다.
1.1. 둘 중 하나라도 false 면 false 반환
1.2. 둘 중 하나라도 null 이면 null 반환 -
OR 연산자 | true, null, flase 우선순위로 잡힌다고 생각하면 편하다.
2.1. 둘 중 하나라도 true 면 true 반환
2.2. 둘 중 하나라도 null 이면 null 반환 -
NOT 연산자 | 참이면 거짓, 거짓이면 참, null 이면 null 반환한다.
비교 범위 연산자
비교 연산자 && 산술 비교 연산자
이전에 배웠던 = 나 != 연산자는 2 가지 값에 대한 비교라고 생각하면 편하다.
그러나 양쪽 항 중 한 곳에 null 이 들어가면 문제가 발생할 수 있다.
이렇게 null 값이 들어올 여지가 있을 때 사용하는 것이 술어 비교 연산자 이다.
# select 는 출력한다 라는 의미이다.
# null='false' 의 결과를 left_result 란 칼럼에 넣어서 출력하고
# , 라는 키워드로 다음 칼럼을 연결할 수 있다.
# null is 'false' 의 결과를 right_result 라는 칼럼에 넣어서 출력했다.
# 따라서 다음의 결과가 나오게 되었다.
SELECT null='false' AS left_result,
null is false AS right_result;
범위 연산자
SELECT * FROM test
WHERE 1<=컬럼이름 AND 컬럼이름 <=9;
SELECT * FROM test
WHERE BETWEEN 1 AND 9;
SELECT * FROM test
WHERE NOT BETWEEN 1 AND 9;조건문 연산자
조건문 연산자 연습을 위해 가상 데이터 베이스를 만들겠다.
DROP DATABASE IF EXISTS test;
CREATE DATABASE test;
\c test
CREATE TABLE student(
id SERIAL PRIMARY KEY NOT NULL,
name TEXT NOT NULL,
score INT NOT NULL
);
INSERT INTO student (name, score)VALUES
('1번 학생',12),
('2번 학생',22),
('3번 학생',32),
('4번 학생',42),
('5번 학생',52),
('6번 학생',62),
('7번 학생',72),
('8번 학생',82),
('9번 학생',92);
ALTER TABLE student
ADD COLUMN grade TEXT;CASE 문
CASE 문을 이용하여 70 80 90 점을 기준으로 f c b a 학점을 주자
위 CASE 문을 2가지 방법으로 사용할 것입니다.
SELECT 문으로 읽을 때 SELECT+CASE 문으로 새 칼럼을 추가하고 값을 부여하기
이미 칼럼이 추가된 테이블에 UPDATE+CASE 문으로 값을 부여하기
1. SELECT + CASE 문
SELECT
id, name, score,
CASE
WHEN score >= 90 THEN 'C'
WHEN score < 90 THEN 'D'
END grade
FROM student;- UPDATE + CASE 문
UPDATE student
SET grade=
CASE
WHEN score>=90 THEN 'A'
WHEN score<90 THEN 'F'
END;COALESCE 문
COALESCE() 함수는 주로 데이터를 조회할 때 null 값이 아닌 다른 값으로 대체할 때 주로 사용된다.
SELECT COALESCE(null, null, null, 'something', null) AS column;
SELECT id,name, COALESCE( score, 0 ),
CASE
WHEM score >= 90 THEM 'A'
WHEN socre < 90 THEN 'F'
END grade
FROM student;NULLIF 문
NULLIF() 함수는 주로 데이터를 조회할 때 일반값을 null 값으로 대체할 때 주로 사용한다.
SELECT NULLIF(20,20) column;
SELECT NULLIF(22,23) column;
DROP DATABASE IF EXISTS test;
CREATE DATABASE test;
\c test
CREATE TABLE student(
id SERIAL PRIMARY KEY,
name TEXT
);
INSERT INTO student (name)VALUES
(''),(''),(''),(''),(''),(''),('');
SELECT
NULLIF(id,0)
FROM student;배열 연산자
앞서 배운 배열 자료형에 대해서 깊게 들어가본다.
여기서의 목적은 세 가지로 작성해보았다.
- 배열의 선언
- 배열에 값 넣기
2.1. 연산자로 넣기
2.2. 배열함수로 넣기 - 배열함수
배열 선언
SELECT ARRAY[5.1, 1.6, 3] AS result;
-- ARRAY[5.1, 1.6, 3] 을 result 칼럼에서 출력
SELECT ARRAY[5.1, 1.6, 3]::INTEGER[] AS result;
-- ARRAY[5.1, 1.6, 3] 을 INTEGER[] 로 형변환하고 result 칼럼에서 출력
SELECT ARRAY[5.1, 1.6, 3]::INTEGER[] = ARRAY[5,2,3] AS result;
-- ARRAY[5.1, 1.6, 3] 을 INTEGER[] 로 형변환하고 ARRAY[5,2,3] 과 비교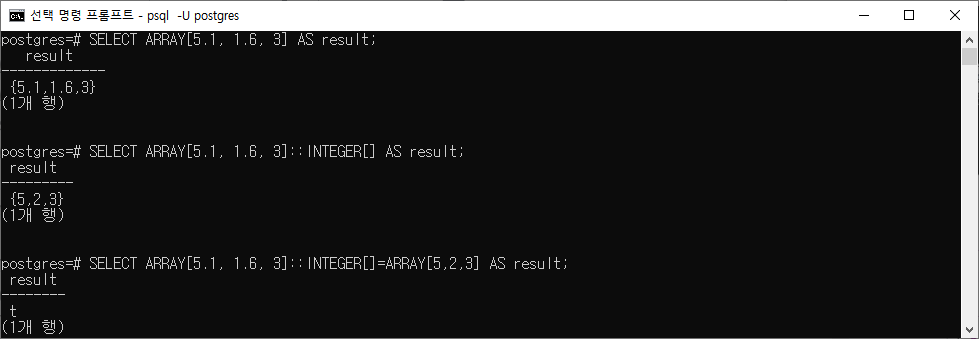
배열 원소 추가
배열에 원소를 추가하는 방법은 두 가지가 있다.
- || 연산자 사용하기
- array_append 사용하기
|| 연산자 사용하기
다음 sql 코드는 배열형 자료와 || 연산자의 설명을 하기 위한 단계적 예시이다.
1개의 원소 혹은 다수의 원소를 넣는 경우를 상정하고 작성한 코드이며,
어떤 sql 문이 정상적으로 작동하고 에러가 뜬다면 어떤 이유 때문인지 생각해보자.
SELECT ARRAY[] || 3 AS result; #1
SELECT ARRAY[]::INTEGER[] || 3 AS reulst; #2
SELECT ARRAY[]::INTEGER[] || 3,4,5 AS result; #3
SELECT ARRAY[]::INTEGER[] || {3,4,5} AS result; #4
SELECT ARRAY[]::INTEGER[] || [3,4,5] AS result; #5
SELECT ARRAY[]::INTEGER[] || 3 || 4 ||5 AS result; #6-
SELECT ARRAY[] || 3 result;
해당 코드를 실행해보면 원하는 형식으로 명시적으로 형변환하세요 라는 메세지가 발생한다. -
SELECT ARRAY[]::INTEGER[] || 3 AS result;
result 배열에 3이라는 원소가 들어간 것을 확인할 수 있다. -
SELECT ARRAY[]::INTEGER[] || 3,4,5, AS result;
특이한 결과물이 나왔고 비정상 결과물 을 받았음을 알리고 다음과 같이 2가지 질문을 만들었다.
3.1. 세 값 중 어떤 값이 배열에 삽입되었을까?
3.2. 세 칼럼 중 어떤 칼럼이 result 라는 이름을 가지게 되었을까?
3.3. result
-
SELECT ARRAY[]::INTEGER[] || {3,4,5} AS result;
처음에는 예상하지 못한 에러 라고 생각했고 문법이 틀린 것인가 라는 생각을 했으나, 조금 더 생각해보니 당연히 말도 안되는 문법 임을 알게 되었다. 이를 알리고 다음과 같은 질문을 만들었다.
4.1. result 칼럼은 배열정보를 받아들인다. 그렇다면 그 배열은 어떤 값을 받아들이는가?
4.2. {3,4,5} 를 일반적으로 어떠한 유형의 값으로 우리가 이해하고 있는가?
4.3. resultresult 칼럼이 받아들이는 배열, 그 배열이 받아들이는 것은 INTEGER 타입이다.
그러나 { 3, 4, 5 } 의 형태는 마치 객체 혹은 JSON 와 같은 형태이며, 이것이 뭐라고 정확히 확언할 수 없다고 하더라도, INTEGER 가 아니라는 것은 자명하다. -
SELECT ARRAY[]::INTEGER[] || [3,4,5] AS result;
4번과 같은 내용이므로 생략하겠다. -
SELECT ARRAY[]::INTEGER[] || 3 || 4 || 5 AS result;
처음에는 진짜 이해할 수가 없었으나 생각해보면 마치 Java 의 결합성 원리 와 같다라는 느낌이 들었다.
array_append 사용하기
array_append 는 배열함수 중 일종으로
이를 사용하여 선언한 배열에 값을 넣어보고 || 연산자처럼 다양한 케이스를 보겠다.
SELECT array_append(ARRAY[], 3) AS result; #1
SELECT array_append(ARRAY[]::INTEGER[], 3) AS result; #2
SELECT array_append(ARRAY[]::INTEGER[], {1,2}) AS result; #3
SELECT array_append(ARRAY[]::INTEGER[], [1,2]) AS result; #4
SELECT array_append(ARRAY[]::INTEGER[], 1, 3) AS result; #5
SELECT array_append(array_append(ARRAY[]::INTEGER[], 1), 3) AS result; # 6
SELECT array_append(ARRAY[1], 3) AS result; #7-
SELECT array_append(ARRAY[], 3) AS result;
보자마자 예상했듯이, 명시적 형변환 에러가 발생했다. -
SELECT array_append(ARRAY[]::INTEGER[], 3) AS result;
보자마자 예상했듯이, result 칼럼에 { 3 } 이라는 값이 나왔음을 알 수 있다. -
SELECT array_append(ARRAY[]::INTEGER[], {1,2}) AS result;
위의 || 연산자와 같은 이유로 문법 에러가 발생한다. -
SELECT array_append(ARRAY[]::INTEGER[], [1,2]) AS result;
위의 || 연산자와 같은 이유로 문법 에러가 발생한다. -
SELECT array_append(ARRAY[]::INETEGER[], 1,2 ) AS result;
솔직히 말하면 당연히 가능할 줄 알았다.
하지만 다음과 같은 에러 메세지가 나왔는데, 아마도 Java 의 메서드가 정해진 매개변수만을 받는 것처럼 PostgreSQL 도 같은 방식이기 때문에 발생한 문제이지 않을까 싶다.
5.1. 그래서 복수의 값은 어떻게 넣는거지?
-
SELECT array_append(array_append(ARRAY[]::INTEGER[], 1),2) AS result;
|| 연산자 썼을 때도 좀 더러운 코드라고 생각했는데 이건 진짜 너무 역겨운 모양인 것 같다.
그래도 만약 2개의 원소를 넣는 방법은 (지금 내가 배운 선으로써는) 이것이 최선인 것 같다. -
SELECT array_append(ARRAY[1], 3) AS result;
해당 배열은 이미 INTEGER 값이 들어있음으로써 INTEGER[] 로 명시적으로 선언되어있다. 따라서 바로 값을 넣을 수 있다.
array_prepend
array_append 와 완벽하게 동일하고 아래 부분만 다르다.
따라서 해당 부분만 짚고 넘어간다.
SELECT array_prepend(1, ARRAY[2,3]) AS result;array_remove
특별한 것은 없지만 예상 가능한 상황은 아래와 같다.
어떤 결과가 나올지 생각해보고 스크롤을 내려보자.
SELECT array_remove(ARRAY[1,2,3,4],4) AS result; #1
SELECT array_remove(ARRAY[1,2,3,4,4],4) AS result; #2
SELECT array_remove(ARRAY[1,2,3,4,4.0],4) AS result; #3
SELECT array_remove(ARRAY[1.0,2.0,3.0,4.0], 4) AS result; #4
SELECT array_remove(ARRAY[1.0,2.0,3.0,4.0,4.4], 4.0) AS result; #5
SELECT array_remove(ARRAY[1.0,2.0,3.0,4.0,4.4], 4) AS result; #6-
SELECT array_remove(ARRAY[1,2,3,4], 4) AS result;
예상한 대로 {1,2,3} 이라는 결과가 나왔다. -
SELECT array_remove(ARRAY[1,2,3,4,4], 4) AS result;
예상하기로는 둘 중 하나만 삭제 될 줄 알았다.
그래서 둘 중 앞에 써진 것과 뒤에 써진 것 중 어떤 것이 삭제될까? 를 알아보려고 했었다.
하지만 결과적으로 둘 다 사라져서 {1,2,3} 이라는 결과를 받게 되었다. 이 부분에서 주목을 해야 하는 점은 중복 원소를 전부 제거 한다는 점이다.
따라서 배열을 사용하는 경우가 있다면 이는 중복 가능성이 없는 데이터 타입 이어야 함을 알게 되었다. -
SELECT array_remove(ARRAY[1,2,3,4,4.0], 4) AS result;
아마 배열 안의 값들이 같은 값으로 형변환이 되고 그래서 삭제된 것 같다. -
SELECT array_remove(ARRAY[1.0 2.0, 3.0, 4.0], 4) AS result;
이 또한 자동으로 삭제가 되었다. >> {1.0 ,2.0, 3.0} -
SELECT array_remove(ARRAY[1.0, 2.0, 3.0, 4.0, 4.4], 4.0) AS result;
이 또한 자동으로 삭제가 되었다. >> {1.0 ,2.0, 3.0, 4.4}
아마도 array_remove 라는 배열함수는 첫 인자로 받아들이는 ARRAY[] 의 각 칸이 가지는 기본자료형에 맞게 두번째 인자를 형변환 해주고 있는 것 같다. -
SELECT array_remove(ARRAY[1.0, 2.0, 3.0, 4.0, 4.4], 4) AS result;
이 또한 자동으로 삭제가 되었다. {1.0 ,2.0, 3.0, 4.4}
여기서 궁금해진 것은 명시적 형변환을 해주지 않았을 때,
배열의 기본 자료형이 정수 실수 중 어떤 것으로 변하는지 그 기준이 무엇인지 였다.
예상가능한 가설은 다음과 같았다.
6.1. 배열의 첫 값을 기준으로
6.2. 배열의 다수결을 기준으로
따라서 배열의 다수는 실수이지만 오직 첫 값만 정수인 것으로 테스트해보았다. -
SELECT array_remove(ARRAY[1, 2.0, 3.0, 4.0], 4) AS result;
진짜 뜻밖의 결과가 나왔는데... 너무 충격적이어서 스크린샷을 바로 첨부를 하였다.
다른 sql 도 같을지는 모르겠지만, postgreSQL 에서는 숫자라는 정보만 구분하고 정수와 실수를 같은 배열에 넣을 수 있는 것이었다.
4와 4.0 과 같은 값도 같이 존재할 수 있었다. (array_remove(배열,4) 를 하면 둘 다 삭제가 된다.) + (array_remove(배열,4.0) 도 동일한 결과가 나온다.) 어떻게 이런 것이 가능한 것일까??

배열함수
| 함수 | 예시 | 설명 |
|---|---|---|
| array_append | array_append(ARRAY[1,2],3) | 배열 맨 뒤에 원소를 추가한다. |
| array_prepend | array_prepend(1,ARRAY[2,3] | 배열 맨 앞에 원소를 추가한다. |
| array_remove | array_remove(ARRAY[1,2],1) | 배열의 특정 원소를 삭제한다. |
| array_replace | array_replace(ARRAY[1,3],3,2) | 배열의 특정 원소를 다른 원소와 대체한다. |
| array_cat | array_cat(ARRAY[1,2],ARRAY[3,4]) | 두 개의 배열을 병합한다. |
JSON(B)
아직 명확한 개념이 잡히지 않은 듯해 JSON 및 JSONB 연산자는 여기서 일시 정지 하기로 하였다.
날짜 및 시간
자주 쓰이는
서브쿼리
- EXISTS
- IN 과 NOT IN
- ANY 와 SOME
- ALL
패턴매칭
- LIKE
- SIMILAR TO
- POSIX 정ㄱ슈기
SQL 문자열
- || 병합연산자
- length()
- substring(문자열, 조건);
- left(문자열, 자를 길이);
- concat(합칠 문자열, 합칠 문자열, ... , 합칠 문자열);
- position(타켓 문자열 in 검색 할 문자열);
// 검색 할 문자열에서 타켓 문자열의 위치를 찾는다. - replace(변경 할 문자열 , 타켓 문자열 , 변경 문자열);
// 변경 할 문자열에서 타켓 문자열을 검색하고 이를 변경 문자열로 바꾼다.
