데이터 집계 및 결합
필요한 정보가 DB 속에서 분산 저장되어 있을 때,
이를 결합 호출하는 것에 관한 내용을 다루고 있다.
아래의 표는 SQL 명령어 처리 순위를 나타낸다.
| 명령어 | 순위 | 설명 |
|---|---|---|
| FROM | 1 | 참조 테이블을 지정한다. |
| WHERE | 2 | 참조 테이블 호출 시 조건을 건다. |
| GROUP BY | 3 | 지정할 칼럼을 하나의 그룹으로 묶는다. |
| HAVING | 4 | 집계된 컬럼 데이터를 필터링한다. |
| SELECT | 5 | 조회할 컬럼을 선택한다. |
| DISTINCT | 6 | 컬럼에서 중복된 데이터를 제거한다. |
| ORDER BY | 7 | 지정된 컬럼을 오름차순 / 내림차순 정렬한다. |
| LIMIT | 8 | 지정한 수 만큼 조회할 칼럼을 제한한다. |
다음과 같은 예시를 통해, 처리 순위의 중요도를 느낄 수 있을 것 같다.
동일 수 의 칼럼이 있다는 전제 하, 100개의 로우가 있는 테이블이 있다고 치자.
그리고 어떠한 조건을 통해서 몇 단계의 집계 과정을 거친다고 했을 때, 필터링은 어느 단계에서 하는 것이 좋겠는가? 결과물이 동일하게 나온다면 최대한 빠른 프로시저에서 필터링 하는 것이 좋다고 생각한다.
물론 작성순서는 위와 다르다는 점을 오인하지 말자.
데이터 그룹화
데이터 그룹화 문법은 다음을 포함하고 있다.
- DISTINCT | 테이블에서 중복되는 데이터 없애기
- GROUP BY | 테이블에서 원하는 자료를 그룹화
- HAVING | 집계된 데이터에서 원하는 조건만 검색
3.1. WEHRE 절과의 차이
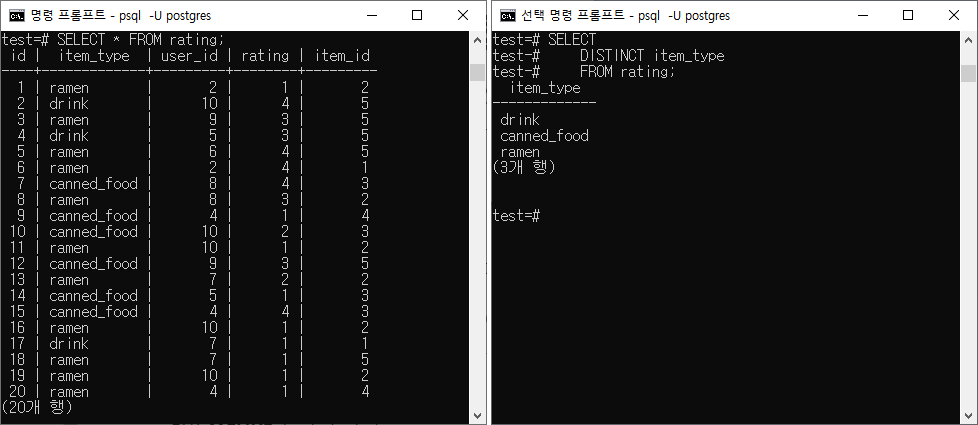
DISTINCT 알아보기
DISTINCT 는 중복 데이터를 제거하는데 사용된다.
사용 가능한 경우의 수는 두 가지가 있을 것 같다.
- 한 칼럼 안에 데이터들을 SET 자료구조화 시킬 때.
- 복수의 칼럼 안에 데이터들의 조합 경우의 수를 구할 때.
실제 서비스 차원에서 어떻게 활용할 지는 아직 모르겠다.
SELECT
DISTINCT 지우고 싶은 칼럼
FROM 테이블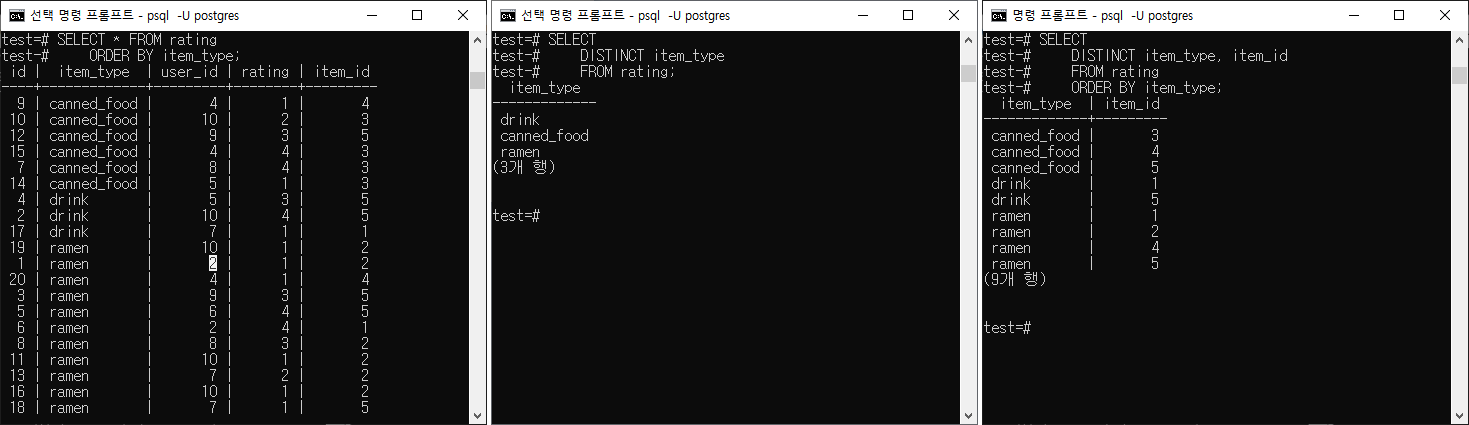
GROUP BY 알아보기
GROUP BY 는 사용에 따라 DISTINCT 와 같은 데이터값을 출력받을 수 있다.
그렇다면 어떤 경우에 GROUP BY를 사용하는 것이 옳을까?
- DISTINCT 로 받을 수 있는 데이터 값에 추가 집계함수를 적용하고 싶을 때.
DISTINCT , GROUP BY 로 중복을 제거했을 때, 중복의 숫자가 몇개인지 등을 알고 싶을 때, COUNT(*) 를 사용하여 해당 칼럼값이 중복인 로우의 수를 반환 받을 수 있다.
# 제안 1 | 기본 문법
SELECT
그룹화할 칼럼 ( * 혹은 칼럼명, 칼럼명 등 )
FROM 테이블
GROUP BY 그룹화할 칼럼;
# 제안 2 | 집계함수 활용 문법
SELECT
그룹화할 칼럼, 집계함수
FROM 테이블
GROUP BY 그룹화할 칼럼;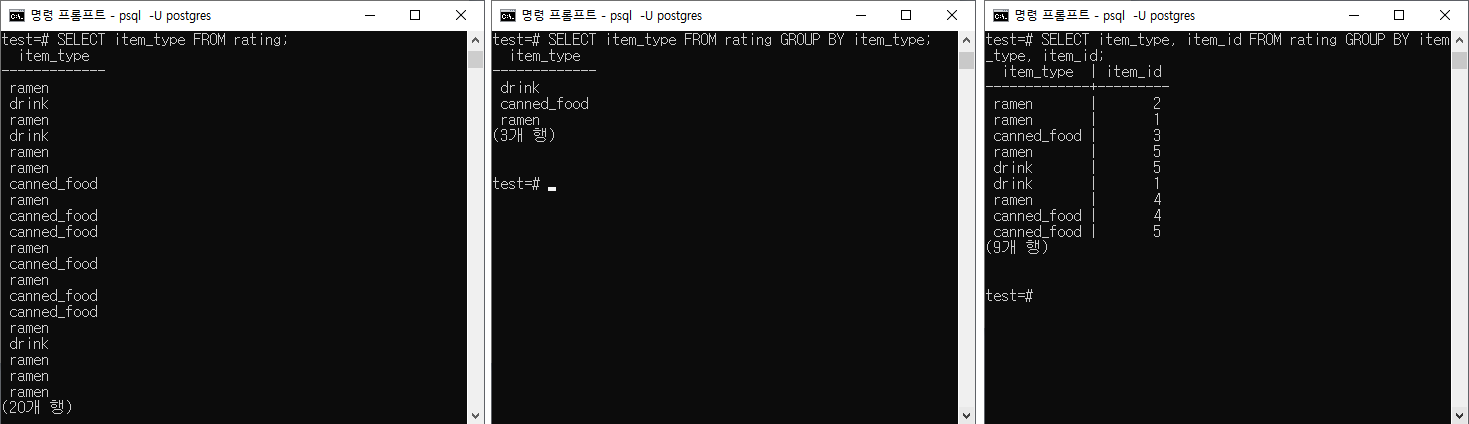
HAVING 알아보기
HAVING 은 집계가 끝난 데이터 군에 새로운 조건을 거는 것이다.
여기서 벌써 WHERE 문과 차이가 있는데, WHERE 은 집계 전에 조건을 거는 명령어이다.
# Having 문법
SELECT
그룹화할 칼럼
FROM 테이블
HAVING 조건;
# Where 문법
SELECT
그룹화할 칼럼
WHERE 조건
FROM 테이블;
# 조합
SELECT
그룹화할 칼럼, 집계함수
WHERE 집계 전 조건
FROM 테이블
HAVING 집계 후 조건;집계함수
여러 군데에 분산 저장되어있는 데이터를 집계 및 그룹화 하는데 성공했다면,
우리는 이 데이터들을 기반으로 새로운 유의미한 정보를 가공하기도 한다.
SELECT
집계함수(칼럼명 혹은 *)
FROM 테이블;이럴 때 사용되는 것 중 하나가 집계 함수이며 다음과 같은 것들이 존재한다.
- 기본 집계 함수
- 불리언 집계 함수
- 배열 집계 함수
- JSON 집계 함수
기본 집계 함수
| 함수 | 예시 | 출력내용 |
|---|---|---|
| avg() | avg(칼럼명) | null 값이 아닌 모든 입력 값의 평균 |
| count(*) | count("키워드 *") | 입력한 로우의 총 갯수 |
| count() | count(칼럼명) | null 값이 아닌 모든 입력 로우 값의 갯수 |
| max() | max(칼럼명) | null 값이 아닌 모든 입력 값의 최댓값 |
| min() | min(칼럼명) | null 값이 아닌 모든 입력 값의 최솟값 |
| sum() | sum(칼럼명) | null 값이 아닌 모든 입력 값의 최댓값 |
불리언 집계 함수
| 함수 | 예시 | 출력내용 |
|---|---|---|
| bool_and() | bool_and(boolean 타입 칼럼명) | 입력된 데이터가 모두 참이면 참을 출력 |
| bool_or() | bool_or(boolean 타입 칼럼명) | 입력된 데이터 중 하나라도 참이면 참을 출력 |
| every() | every(boolean 타입 칼럼명) | bool_and() 와 동일 |
배열 집계 함수
| 함수 | 출력내용 |
|---|---|
| array_agg() | 1. 배열로 연결된 null 값을 포함한 입력 값 2. 더 높은 차원의 배열로 입력된 입력배열 |
JSON 집계 함수
| 함수 | 출력내용 |
|---|---|
| json_agg() | null을 포함해 json 배열로 집계한 값 |
| jsonb_agg() | null을 포함해 jsonb 배열로 집계한 값 |
| json_object_agg(name, value) | name-value 쌍을 json 개체로 집계한 값 value 는 null 을 포함, name은 null 을 포함하지 않는다. |
| jsonb_object_agg(name, value) | name-value 쌍을 json개체로 집계한 값 value 는 null 을 포함, name은 null 을 포함하지 않는다. |

블로그 이전 : https://inblog.ai/unchaptered