데이터 타입
| 숫자형 | Numberic Types | INTEGER, SMALLINT, BIGINT, NUMERIC(n,m) 등 |
|---|---|---|
| 화폐형 | Moneytary Types | MONEY |
| 문자형 | Character Types | VARCHAR(n), CHAR(N), TEXT (단, n 은 양의 정수며 데이터의 길이 의미) |
| 날짜형+ | Date & Time Types | TIMESTAMP, DATE, TIME 등 (자세한 내용은 아래에서 꼭 확인하자) |
| 불리언형 | Boolean Types | True | True, yes, on, 1 False False, no, off, 0| Null | 알 수 없는 정보 및 일부 불확실 |
| 배열형 | Array Types | |
| 제이슨형 | Json Types |
숫자형
| 숫자형 타입 | 설명 | 저장용량 |
|---|---|---|
| INTEGER | 나타낼 수 있는 수의 범위와 저장용량 사이의 밸런스가 적절. 일반적으로 많이 쓰며, 숫자 길이 제한이 불가 |
4 bytes |
| NUMERIC(p,q) | 소수점자리 표시 가능. DECIMAL 과 같음 |
가변적 |
| FLOAT | 부동소수점을 사용. REAL 또는 DOUBLE PRECISION 으로 인식 |
4 bytes 8 bytes |
| SERIAL | INTEGER 값으로 1씩 추가되며 값이 자동 생성. 프라이머리 키 데이터 타입으로 주로 사용. |
4 bytes |
화폐형
- 화폐형은 금액을 저장하는 데이터 타입이다.
- 화폐형은 분수의 형식으로 금액을 저장한다.
- 분수의 정밀도는 lc-monetary 설정을 따른다.
3.1. local 지역
3.2. monetary : 통화
3.3. 각국마다 화폐를 표기하는 규칙이 다르다. 참고 포스트
3.4. AWS 컴퓨팅 시 lc-monetary 설정은 필요한 상황에 구글링해보도록 하자. - 다만, TABLE 에서는 분수의 정밀도를 소수점 두 자리까지 표기한다.
막연한 개념인것 같아서, 별도의 예제 코드를 작성해보았다.
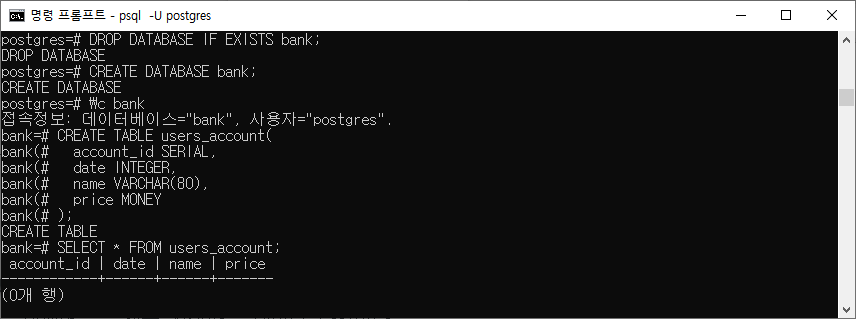
DROP DATABASE IF EXISTS bank; CREATE DATABASE bank; \c bank CREATE TABLE users_account( account_id SERIAL, date INTEGER, name VARCHAR(80), price MONEY ); SELECT * FROM users_account;
문자형
| 문자형 타입 | 설명 |
|---|---|
| VARCHAR(n) | 공백을 포함한 글자의 길이 저장. n 바이트의 문자열(고정형), 빈 자리는 그대로 남겨둔다. |
| CHAR(n) | 공백을 제외한 글자의 길이를 저장 글자의 공백도 포함한 상태로 저장함 n bytes 의 문자열(가변형), 빈 자리의 할당 해제 |
| TEXT | 나타낼 수 있는 수의 범위와 저장용량 사이의 밸런스가 적절. 일반적으로 많이 쓰며, 숫자 길이 제한이 불가 |
- PostgreSQL 에서 CHAR(n) 이 VARCHAR(n) 보다 퍼포먼스가 느리다.
따라서 특별한 이유가 없으면 VARCHAR(n) 을 사용하도록 하자.
1.1. CHAR(n) 은 부족한 공간을 공백으로 채운다. (in PostgreSQL)
날짜형 && 시간형
| 구분 | 대분류 | 줄임말 | 설명 | 저장용량 |
|---|---|---|---|---|
| 날짜 및 시간 | TIMESTAMP | 1. TIMESTAMP 2. TIMESTAMPTZ |
1. TIMESTAMP WITHOUT TIMEZOME 2. TIMESTAMP WITH TIME ZONE |
both 8 bytes |
| 날짜형 | DATE | - | - | 4 bytes |
| 시간형 | TIME | 1. TIME WITHOUT TIME ZONE 2. TIME WITH TIME ZONE |
8 bytes 12 bytes |
- TIMESTAMPTZ 가 더 정확하므로 사용이 권고된다.
1.1. TIMESTAMP 는 이를 기록하지 않는다.
1.2. TIMESTAMPTZ 는 시차에 따라 +hours 등의 정보가 기록된다.
1.3. 함수 등을 이용하면 시간 정보를 더욱 효율적으로 다룰 수 있다.
역시나 모호한 개념인 것 같아서 실제 코드를 작성해 보았다.
1. locale 미적용
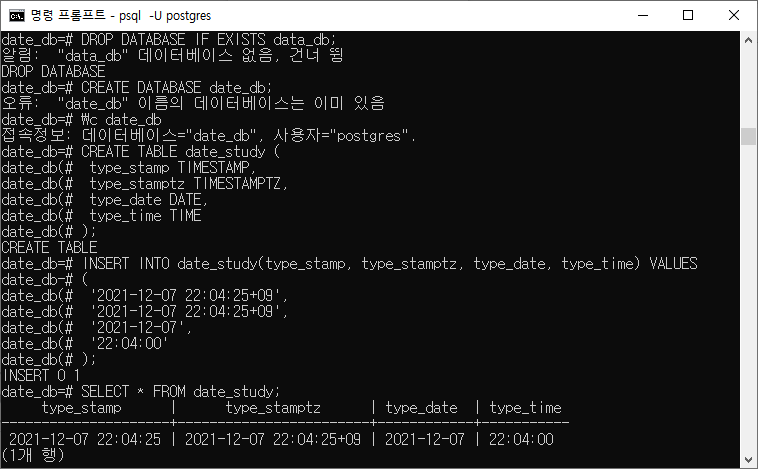
DROP DATABASE IF EXISTS data_db; CREATE DATABASE date_db; \c date_db CREATE TABLE date_study ( type_stamp TIMESTAMP, type_stamptz TIMESTAMPTZ, type_date DATE, type_time TIME ); INSERT INTO date_study(type_stamp, type_stamptz, type_date, type_time) VALUES ( '2021-12-07 22:04:25+09', '2021-12-07 22:04:25+09', '2021-12-07', '22:04:00' ); SELECT * FROM date_study;
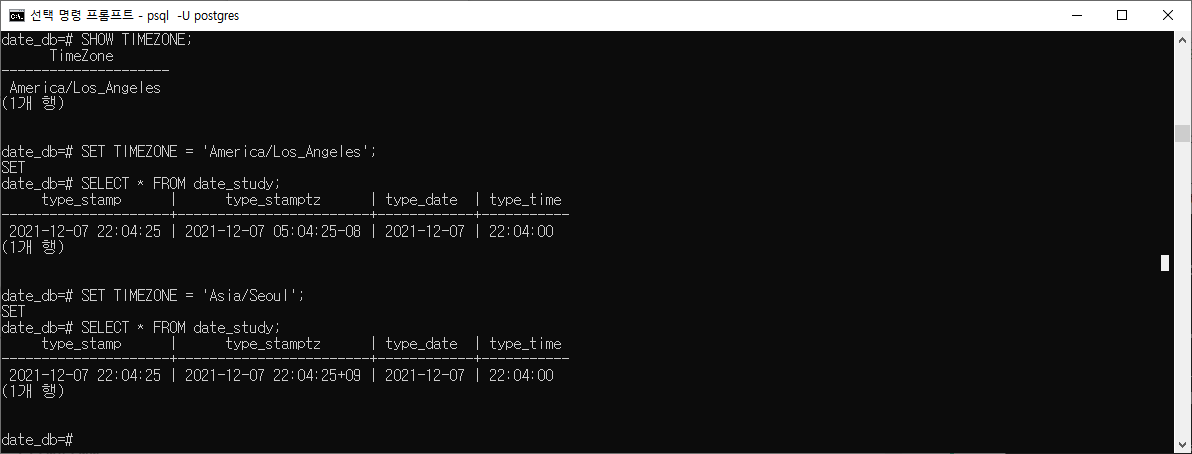
2. locale 적용SHOW TIMEZONE; SET TIMEZONE = 'America/Los_Angeles'; SELECT * FROM date_study; SET TIMEZONE = 'Asia/Seoul'; SELECT * FROM date_study;
불리언형
불리언형은 ## 데이터 타입에서 모두 설명하였으므로 넘어가도록 한다.
배열형
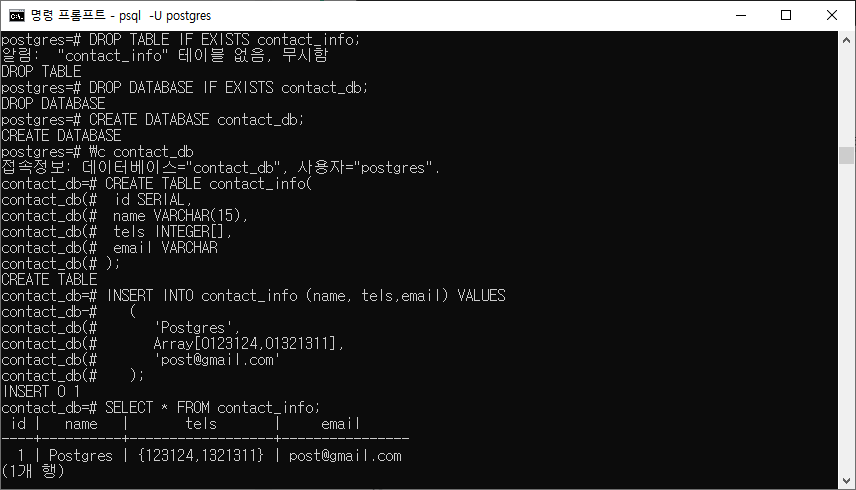
DROP TABLE IF EXISTS contact_info; DROP DATABASE IF EXISTS contact_db; CREATE DATABASE contact_db; \c contact_db CREATE TABLE contact_info( id SERIAL, name VARCHAR(15), tels INTEGER[], email VARCHAR );
- 배열 데이터 타입은 Array [ , ] 의 형태로 데이터를 입력할 수 있다.
INSERT INTO contact_info (name, tels,email) VALUES ( 'Postgres', Array[0123124,01321311], 'post@gmail.com' ); SELECT * FROM contact_info;
- 배열 데이터 타입은 { , } 의 형태로도 데이터 입력을 할 수 있다.
INSERT INTO contact_info (name, tels, email) VALUES ( 'Postgers', {0123124,01321311}, 'post@gmail.com' ); SELECT * FROM contact_info;
JSON 형
- JSON 은 입력한 텍스트의 정확한 사본을 생성한다.
1.1. 따라서 처리 속도가 느려진다. - JSONB 는 처리속도가 비교적 빠르나 데이터 저장 속도가 느리다.
- 일반적으로 대부분의 어플리케이션에서는 JSONB의 형태로 저장하는 것을 선호한다.
역시나 모호한 개념이기에 코드 예제를 확인해보자.
DROP DATABASE IF EXISTS order_db;
CREATE DATABASE order_db;
\c order_db;
DROP TABLE IF EXISTS order_sheet;
CREATE TABLE order_sheet (
id SERIAL,
info JSON NOT NULL
);
INSERT INTO order_sheet (info)VALUES
('{"customer":"홍길동", "price":18000}'),
('{"customer":"고길동", "price":22000}'),
('{"customer":"마장동", "price":30000}');
SELECT * FROM odrer_sheet;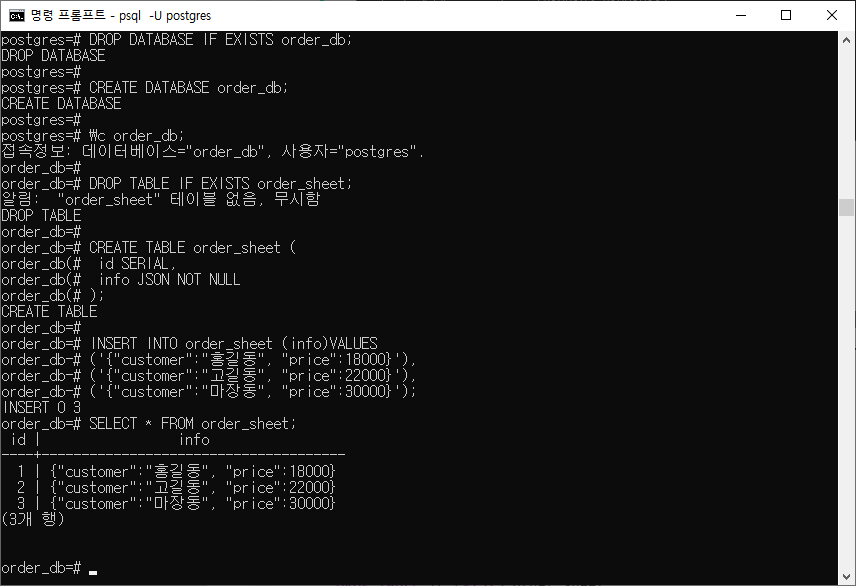

블로그 이전 : https://inblog.ai/unchaptered