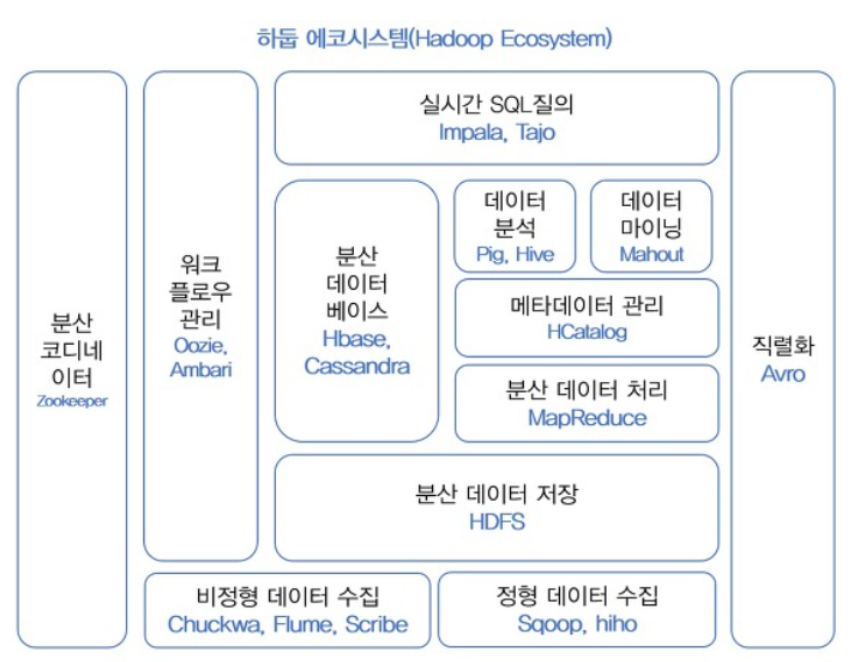
하둡 에코시스템
우리는 여러 프레임워크를 알아보았다. 하둡에서 데이터를 분석 유지 저장 관리 할 때 필요한 모든 것들을 에코시스템이라 한다. 즉, 하둡은 효율적인 데이터 처리와 분석을 위해 맵리듀스, 분산형 파일시스템(HDFS) 말고도 많은 구성요소로 포함된다. 구성요소들에 대해 알아보도록 하자.
하둡 코어 프로젝트 : HDFS(분산데이터 저장), MapReduce(분산처리)
하둡 서브 프로젝트 : 하둡 코어 프로젝트를 제외한 나머지 프로젝트로 데이터 마이닝, 수집, 분석 등을 수행한다.
하둡 서브 프로젝트 (분산데이터를 다루기 위해 만들어진 추가 project)
지금부터는 기존의 데이터가 아닌 분산 데이터이기 때문에 새롭게 생긴 용어들이다. 사실상 기존의 데이터를 다루는 데 사용되어지는 개념이지만, 분산되어 저장된 데이터를 처리하는 방식에 대한 이름을 붙인 것이라고 할 수 있다.
하둡 에코시스템
주요 기술별 역할
작업 흐름도
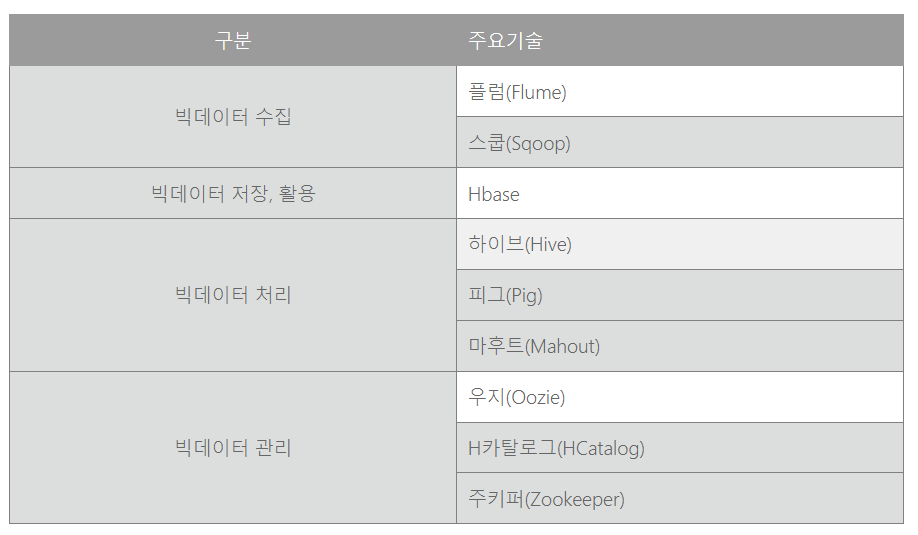
HDFS(하둡 저장 시스템) => MapReduce(데이터를 key value로 변경) => Hbase(변경된 데이터를 데이터베이스로 저장) => Pig, Hive, Mahout, Oozie(데이터를 분석해주는 툴)
0. 하둡 사용자 인터페이스(Hue, Zeppelin)
하둡 휴(Hue, Hadoop User Experience)는 하둡과 하둡 에코시스템의 지원을 위한 웹 인터페이스를 제공하는 오픈 소스 이다. Hive 쿼리를 실행하는 인터페이스를 제공하고, 시각화를 위한 도구를 제공한다. 잡의 스케줄링을 위한 인터페이스와 잡, HDFS, 등 하둡을 모니터링하기 위한 인터페이스도 제공한다.
Zeppelin은 한국의 NFLab이라는 회사에서 개발하여 Apache top level 프로젝트로 최근 승인 받은 오픈소스 솔루션으로, Notebook 이라고 하는 웹 기반 Workspace에 Spark, Tajo, Hive, ElasticSearch 등 다양한 솔루션의 API, Query 등을 실행하고 결과를 웹에 나타내는 솔루션입니다.
- Flamingo framework
1. Hbase
하둡에서 사용하는 데이터베이스는 관계형 데이터베이스가 아닌 NoSQL(비정형화된 데이터베이스) 이다. Hbase는 자바 언어로 만들어졌으며, HDFS를 이용하여 분산된 컴퓨터에 데이터를 저장한다. 그리고 Hbase는 압축 기능과 자주 사용되는 데이터를 미리 메모리에 캐싱하는 인-메모리(In-Memory)기술을 사용하여 데이터 검색 속도를 높인다.
HDFS와 Hbase가 헷갈릴 수 있다. HDFS가 원초적인 데이터를 분산저장 하는 곳이라고 생각하면되고, Hbase는 그 원초적 데이터를 가져와서 key, value 형태와 같이 가공을 해서 쉽게 가져다 쓸 수 있게 만든 데이터베이스라고 생각하면 된다.
NoSQL(Not Only SQL)은 대용량 데이터를 처리하기 위해서 탄생된 데이터베이스이다. 대용량 데이터를 저장하고 처리하기 위해서는 지리적으로 분산되어 있는 노드들에 대한 안정적인 관리가 필요하며, 속도보다는 데이터를 손실하지 않고 저장하는 방법과 더 많은 데이터를 처리하기 위해서 노드들을 쉽게 확장할 수 있는 방법에 중점을 두고 설계가 되었다고 보면 된다.
NoSQL의 큰 종류에 대해 알아보자. 'Key-Value store' 제품군으로는 멤캐시드(Mem-Cached)와 레디스(Redis, Remote Dictionary Server)등이 있으며, 키-밸류 형태로 이루어진 비교적 단순한 데이터 타입을 데이터베이스에 저장한다. 'Graph Database' 제품에는 네오포제이(Neo4j)가 있으며, 그래프 모델에서 필요한 정점(Vertex)와 간선(Edge) 그리고 속성(Property)등과 같은 정보를 데이터베이스에 저장하고, 'Document Store' 제품군에는 카우치DB와 몽고DB가 있으며, 문서 형태의 정보를 JSON 형식으로 데이터베이스에 저장한다. 마지막으로 'Wide Colum Store' 제품군에는 H베이스(HBase)와 카산드라(Cassandra)가 있으며, 컬럼안에 여러 정보들을 JSON 형태로 저장할 수 있다.
하둡 진영에서는 관계형 데이터베이스에 호감을 가지고 있는 분석가와 사용자들의 마음을 돌리기 위해서, 빠른 속도와 손 쉬운 사용 그리고 관계형 데이터베이스에서 사용하던 도구들을 이용할 수 있는 시스템을 만들기 위해서 노력하고 있다. 이러한 데이터베이스 제품들을 'NewSQL'이라고 부르고 있으며, 여기에는 그루터(Gruter)의 타조(Tajo), 구글의 드레멜(Dremel), 호튼웍스의 스팅어(Stinger), 클라우데라의 임팔라(Impala)등이 있다. 관련 내용은 아래의 Hive에서 다시 나오니 참고하자.
2. 주키퍼(Zookeeper)
Zookeeper(사육사)는 이름에서 그 역할을 쉽게 짐작할 수 있다. 분산 시스템 간의 정보 공유 및 상태 체크, 동기화를 처리하는 프레임워크로 이러한 시스템을 코디네이션 서비스 시스템이라고 한다. Zookeeper를 많이 사용하는 이유는 기능에 비해 시스템이 단순하기 때문이다. 분산 큐, 분산 락, 피어 그룹 대표 산출 등 다양한 기능을 가진다. 쉽게 설명하면, 리소스와 하둡의 구성요소 간의 불일치 문제를 중간에서 해결하는 역할이다
3. Pig와 Hive Project
맵리듀스을 구현을 하려면 여러 언어들을 사용해야한다. 기본적으로 하둡은 자바로 개발되어 있기 때문에, 가장 많이 활용되는 언어는 자바이다.(다른 언어도 지원을 한다.) 따라서 초창기는 MapReduce를 자바를 통해서 직접 코딩을 했다. 그러나 자바코드는 굉장히 길기 때문에 자동으로 자바가 작동할수 있도록 스크립트 언어를 만들었는데, 그것이 Pig와 Hive이다.
Pig : [Yahoo] 많은 사람들이 사용할 수 있도록 MapReduce 프로그램을 만들어 주는 고수준 언어를 만들겠다는 목적으로 만들어짐
HIVE : [Facebook] SQL(유사) 구문에서 MapReduce를 자동생성하겠다는 목적으로 만들어짐
정리하면, Pig와 HIVE의 탄생으로 어려운 자바을 통해 MapReduce를 할 필요없어진 것이다.
3.1 Pig Project
맵리듀스 어플리케이션으로 개발해서 처리할 수도 있지만, 맵리듀스를 사용하지 않고 Pig를 사용해서도 분산파일 시스템에 저장된 데이터를 처리할 수 있게 만든 스크립트 언어이다. Pig는 Yahoo에서 개발되어 졌으며, Pig Latin language는 SQL과 유사한언어를 기본으로한 쿼리이다. pig는 명령 실행 작업을 수행한 후에 백그라운드에서 MapReduce의 모든 활동을 처리한다. 처리 후엔 결과물를 HDFS에 저장한다.
3.2 Hive Project
하둡은 하이브(Hive)가 없었던 시절인 하둡 v1에서는 맵-리듀스(Map-Reduce) 언어를 사용하여 하둡 분산 파일 시스템(HDFS)에 저장된 정보들을 조회(Query) 했다. 그러나 프로그램을 모르는 일반 사용자들이 맵-리듀스 언어를 사용하여 조회(Query)하는 일이 어려울 수 밖에 없었다. 이러한 문제점을 해결하기 위한 하이브는 하이브큐엘(HiveQL)이라는SQL과 거의 유사한 언어를 사용하여 일반 사용자들이 쉽게 데이터를 조회(Query)할 수 있도록 지원한다.
데이터를 다루는데는 관계형데이터베이스인 SQL이 일반적으로 가장 많이 사용된다. 따라서 분산파일로 저장된 데이터를 SQL로 다루기 위해 탄생한 것이 Hive이다. 최근에는 Hive를 활용하여 분산파일을 핸들링하는 것이 가장 일반적인 방법이다. 그러나 정형데이터의 경우만 SQL로 처리하는 것이 가능하고 반정형 데이터나 비정형 데이터는 SQL로 처리하기가 쉽지가 않다. 이런 경우는 맵리듀스로 다시 프로그래밍을 해야할 필요가 있다. 정리하면 Hive는 SQL로 분산데이터 처리를 하기 위한 것이다.
SQL 방법론 및 인터페이스의 도움으로 HIVE는 대용량 데이터 세트를 읽고 쓰기가 가능해진다. 쿼리 언어는 HQL (Hive Query Language)라고 불리며 실시간 처리와 일괄 처리를 모두 허용하므로 확장성이 뛰어나고 모든 SQL 데이터 유형이 Hive에서 지원되므로 쿼리 처리가 더 쉬워진다.
하지만 하이브에도 몇가지 단점이 있다. 하이브큐엘(HiveQL)을 통해서 조회(Query)를 실행하면 내부적으로 맵-리듀스 언어로 변환하는 작업을 거치기 때문에, 맵-리듀스는 맵과 리듀스간의 셔플링 작업으로 인하여 속도가 느리다는 단점이 있다. 하이브큐엘(HiveQL)이 일반 사용자들에게 손쉽게 조회(Query)할 수 있는 방법을 제공하고 있지만 처리 속도가 느리다는 문제점은 여전히 가지고 있고, 하이브큐엘(HiveQL) 언어는 SQL과 비슷한 언어이지만 표준 SQL(Ansi SQL)의 규칙을 준수하지 않으며, 사용자들은 이러한 차이점을 다시 배워야하는 문제점을 가지고 있다.
하이브가 가지고 있는 문제점을 개선하기 위한 하둡 진영은 크게 두 갈래로 나뉘게 된다. "하이브를 완전히 대체하는 새 기술을 쓸 것인가?" 아니면 "하이브를 개선해 속도를 높일 것인가?" 이다.
하이브를 살려야 한다는 입장을 가장 강력하게 내세운 회사는 호튼웍스이다. 호튼웍스는 하이브를 최적화하고 파일 포맷 작업을 통해 하이브 쿼리 속도를 100배 끌어올리겠다는 비젼을 내 놓았다. 이것이 바로 스팅어(Stinger)이다.
하이브를 버리고 새로운 엔진을 찾아야 한다는 진영은 그루터의 타조와 클라우데라의 임팔라가 있다. 타조는 하이브를 개선하는데 한계가 명확하기 때문에 대용량 SQL 쿼리 분석에 적합하지 않다는 입장이며, 기획 단계부터 하이브를 대체하는 새로운 엔진을 개발하고 있다. 클라우데라의 임팔라는 좀 특이한 경우인데, 일정 규모 이상의 데이터는 임팔라로 분석이 불가능하다. 임팔라는 메모리 기반 처리 엔진이어서, 일정 용량 이상에서는 디스크 환경의 하이브를 사용해야 한다. 하지만 전체 틀에서는 하이브를 버리는 쪽으로 무게를 두고 있다고 이해하면 된다.
4. Mahout(마하웃)
복잡한 머신러닝이나 인공지능 알고리즘을 큰 데이터를 가지고 처리하려면, 별도의 알고리즘이 구현되어 있는 구현체가 필요하다. 즉, 머신러닝 알고리즘을 분산데이터에서 처리할 수 있도록 만드는 아웃풋 구현체라고 할 수 있다.
5. Sqoop
관계형데이터베이스(ex_마리아DB, 오라클, MySQL)와 하둡 간 데이터를 주고받는 것을 쉽게 할 수 있는 프레임워크이다. 보통 Sqoop은 정형화된 데이터를 수집하는 기술로 많이 쓰인다. 만약, 소셜 네트워크 서비스에서 만들어지는 비정형 데이터의 경우는 클라우데라(Cloudera)의 플룸(Flume)과 아파치(Apache) 척화(Chukwa)등이나, 페이스북에서 사용하는 스크라이브(Scribe)를 비정형데이터 수집 기술로 쓰인다..
6. HCatalog
하둡에 저장된 데이터를 다루는 엔진이다. 사용자마다 자신이 편한 Hive나 Pig 등 다른 명령어를 사용한다. 이럴 때 기본적인 메타나 스키마를 통일되게 공유하는 경우가 필요하다. 즉, HCatalog는 하나의 카탈로그로 관리를 하겠다는 의미이다.
7. Mrunit (엠알유닛)
맵리듀스를 테스트 하는 프레임워크이다.
8. Oozie(우지)
데이터를 시 용도에 맞게 데이터 마트를 만들 때, 중간중간에 있는 workflow들을 관리해 준다. 즉, Oozie는 단순히 스케줄러의 작업을 수행하므로 작업을 예약하고 단일 단위로 함께 바인딩한다.
9. YARN(Yet Another Resource Negotiator)
YARN은 Hadoop v1에 있던 Job Tracker의 병목현상을 제거하기 위해 Hadoop v2에 도입이 되었다. 클러스터 전체에서 리소스를 관리하고 하둡 시스템에 대한 스케줄링 및 리소스 할당을 수행함으로 YARN은 빅데이터 처리에 사용되는 대규모 분산 운영체제 라고도 할 수 있다.
YARN은 또한 그래프 처리, 대화형 처리, 스트림 처리 및 배치 처리와 같은 다양한 데이터 처리 엔진을 통해 HDFS (Hadoop 분산 파일 시스템)에 저장된 데이터를 실행하고 처리 할 수 있기 때문에 시스템을 훨씬 더 효율적으로 만든다. 다양한 구성 요소를 통해 다양한 리소스를 동적으로 할당하고 응용 프로그램 처리를 예약 할 수 있다.
10. Solr, Lucene
자바 라이브러리의 도움으로 검색 및 인덱싱 작업을 수행하는 두 서비스이다.
11. Spark
일괄 처리, 반복적 실시간 처리, 그래프 변환 및 시각화 등과 같은 소모적인 프로세스 작업을 처리하는 플랫폼이다. 메모리 리소스를 소비하므로 최적화 측면에서 이전보다 빠르다. Spark는 실시간 데이터에 가장 적합한 반면, Hadoop은 구조화 된 데이터 또는 일괄 처리에 가장 적합하다. 따라서 대부분의 회사에서는 두가지 다 변환해가면서 사용되어진다.
