
들어가기에 앞서
자료구조 공부를 본격적으로 시작하기에 앞서 자료구조에서 중요한 개념인 시간 복잡도와 메모리에 대해서 간단하게 정리하고 시작하려 한다.
시간복잡도란?
자료구조의 오퍼레이션 혹은 알고리즘이 얼마나 느리고 얼마나 빠른지 측정하는 방법
시간복잡도는 실제로 시간을 측정하는 것이 아니라 단계(Steps)를 측정한다. 얼마나 많은 단계를 거쳐서 문제를 해결하는가로 측정하는 것이다. 즉 거쳐가야하는 단계가 낮을수록 좋다고 판단하는 것이다. 이 점을 기억하면서 자료구조에 대한 공부를 시작해보자.
메모리에 대한 이야기
다음은 메모리에 대해서 간단하게 이야기하고 넘어가려 한다. 우리가 흔히 접하는 컴퓨터의 메모리는 2가지 종류가 있다.
비휘발성(non-volatile) 메모리
컴퓨터의 하드드라이브와 같은 메모리로 우리가 컴퓨터를 재부팅하더라도 남아있는 메모리이다.
휘발성(volatile) 메모리
RAM(Random Access Memory)과 같이 컴퓨터를 재부팅하면 모든 데이터가 사라지면서 초기화 되는 메모리이다. 프로그램이 돌아가면서 우리가 선언한 변수 등이 저장되는 메모리가 바로 RAM이다.
RAM의 특징
RAM은 이름 그대로 랜덤으로 데이터에 접속한다.
위에 설명한 말이 잘 이해되지 않을 수도 있다. RAM을 그림으로 설명해보자.
먼저 RAM을 박스들이 가득 들어있는 그룹이라고 생각해보자.
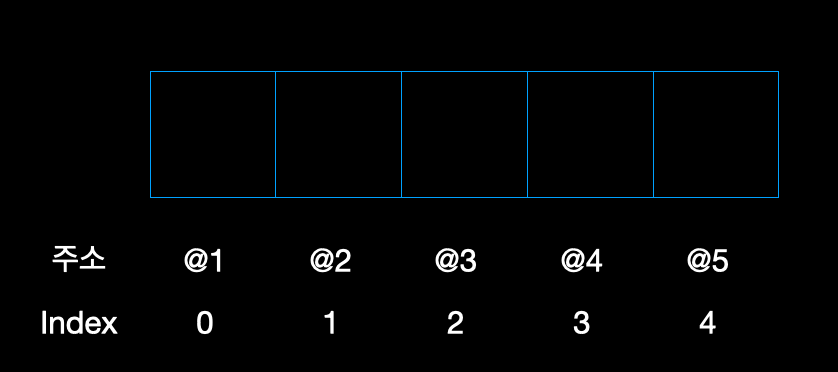
이렇게 박스마다 데이터가 랜덤하게 들어가 있다고 가정해보자. 또한, 데이터들이 들어있는 각각의 박스는 이름을 가지고 있는데 그 이름을 Memory Address라고 한다.

위 그림처럼 각각의 박스에는 Memory Address가 있고, 프로그램이 해당 주소를 지정하면 RAM은 바로 빠르게 데이터에 접속이 가능한 것이다. 이때 RAM은 랜덤접근 방식이기 때문에 순차적으로 접근하는 것이 아닌 해당 데이터의 주소로 바로 접근을 하는 것이다.
이러한 개념을 전제로 메모리의 관점에서 배열(Array)에 대해 알아보자.
메모리 관점에서의 배열
배열은 JS와 Python 등에서는 길이를 지정하지 않고 사용하지만 Java 또는 C와 같은 언어에서는 크기가 정해진 상태로 사용을 한다. 그렇다면 RAM에서는 배열을 어떻게 받아들일까? 다음 그림을 보면서 알아가보자.
예를 들어 내가 저장할 배열의 길이가 4라고 가정했을때 컴퓨터에게 배열의 길이를 사전에 알려주고 나란히 들어갈 수 있도록 메모리의 위치를 예약 및 할당해야한다. 컴퓨터는 우리가 저장하려는 배열이 어느정도 긴지를 기억하고 최대 길이가 얼마이며 어디서 시작하는지 알고있다.
하지만 위에서 이야기했던 JS와 Python 등의 언어는 내부적으로 핸들러가 배열의 길이를 조절하고 관리하기 때문에 배열이 얼마나 길 것인지 생각하지 못 할 수도 있다. 내부적으로 핸들러가 조작을 한다는 것은 프로그램 속도의 저하가 발생한다는 뜻이기도 하다.
여기까지 메모리의 관점에서 바라본 배열의 아주 기초적인 모습을 보았으니 각각의 오퍼레이션에서는 어떤 원리로 동작하는지 알아보자.
오퍼레이션 동작원리
읽기(Reading)
가장 기초적인 동작이다. 배열은 0부터 인덱싱을 한다. 컴퓨터는 0부터 읽어드리기 때문에 배열의 인덱싱은 0부터 시작하는 것이다.
인덱스(Index) : 사전적 의미로는 '색인'이라하며, 보통 전산분야에서는 데이터를 찾는 지표, 지수 정도로 해석
인덱싱(Indexing) : 인덱스를 이용하여 데이터를 찾거나 지표, 지수 등을 지정하는 것을 의미
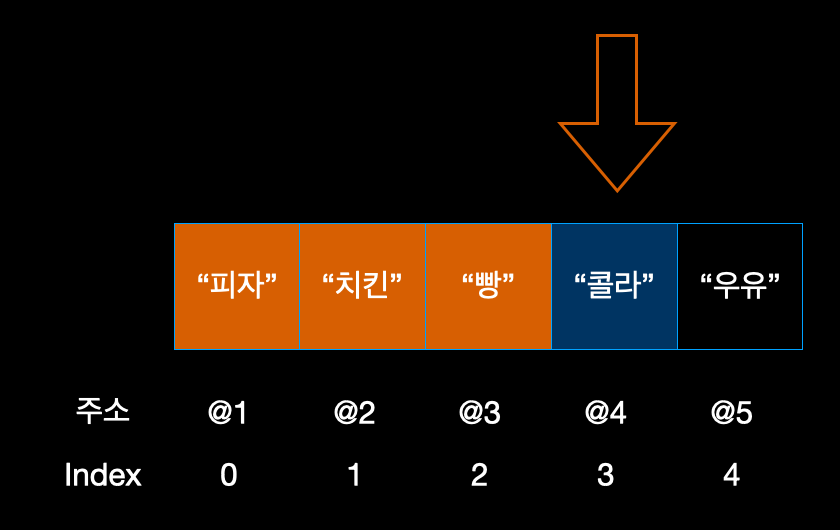
이러한 인덱스 번호를 이용하면 배열에서 해당 인덱스 번호로 위치를 지정하기 때문에 쉽게 배열의 데이터에 접근이 가능하다. 아래의 예시를 보자. "콜라"라는 데이터를 읽어드리기 위해서는 인덱스 3번의 데이터를 컴퓨터에게 달라고하면 된다.
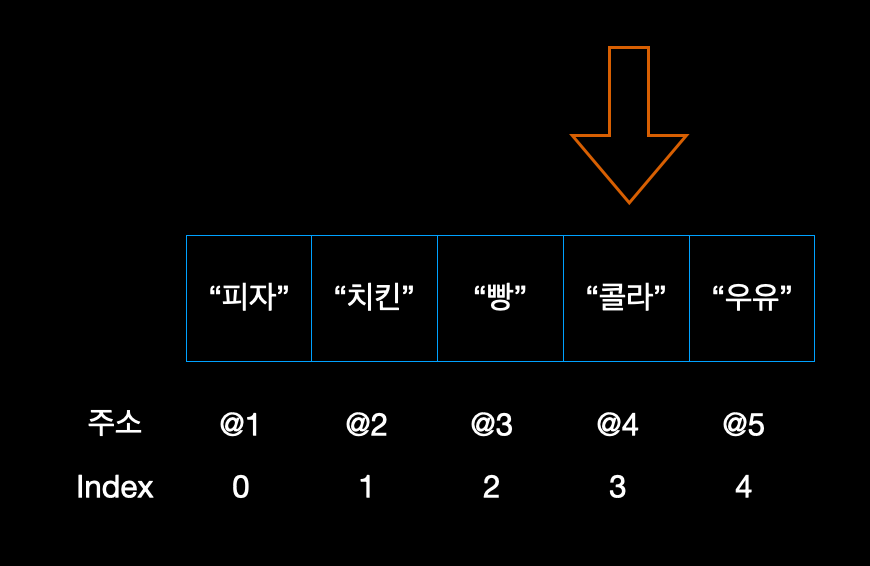
배열에서 읽기에 대한 속도는 굉장히 빠르다. 이유는 앞서 설명한 것처럼 컴퓨터는 배열의 시작과 끝을 이미 알고 있는 상태이기 때문이며, RAM은 메모리 영역의 데이터에 대해서 랜덤으로 접근한다. 또한, 배열의 읽기는 단계가 1단계에서 끝난다. 이 말은 배열의 인덱스를 지정만 해준다면 해당 데이터를 가져오기란 굉장히 편하다는 것이다. 결론적으로 많은 자료를 읽어야 한다면 배열이 성능이 좋다는 것이다.
참고로 여기서의 읽기는 지정한 인덱스의 데이터를 가져오는 것을 이야기한다. 특정 데이터를 찾아나서는 검색과 혼동하지 말자.
검색(Searching)
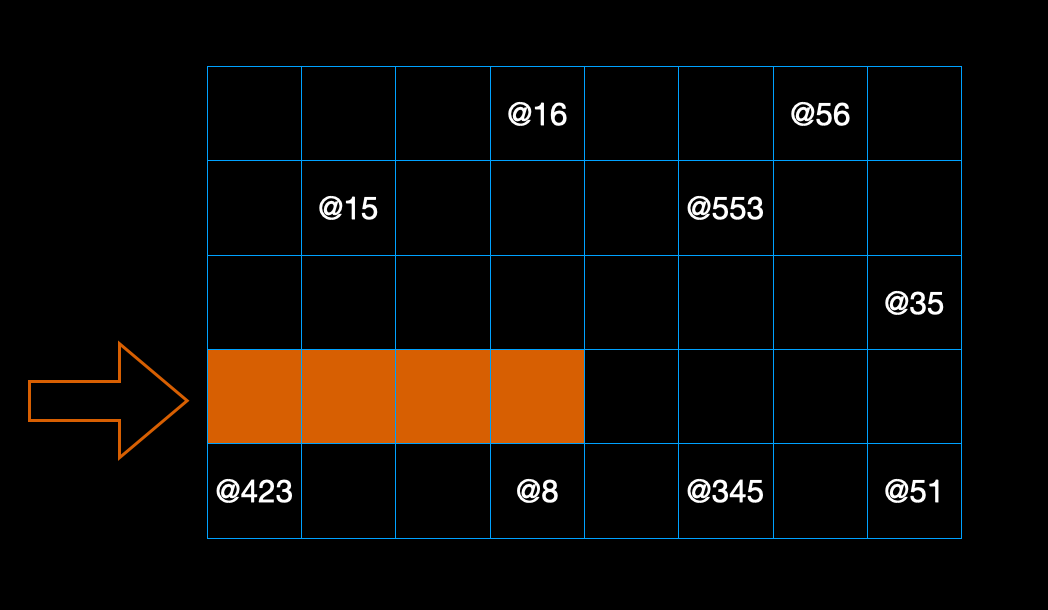
검색은 읽기와 성질이 다르다. 얻고자하는 데이터가 어디에 있는지 알 수 없으며, 심할 경우에는 해당 배열에 들어있지 않을수도 있다. 이 말은 데이터를 찾기 위해서 배열의 뚜껑을 하나하나 다 열어봐야 한다는 말이다. 아래 그림을 보자.

위에서 설명한 것처럼 박스들은 주소를 가지고 있다. 때문에 박스 내부의 데이터가 어떤 것이 들어있는지는 열어봐야 아는 것이다. 랜덤접근으로 박스에 접근은 쉬우나 찾고자하는 데이터가 어디에 들어있는지는 열어봐야하는 것이다. 검색이 바로 찾고자 하는 데이터를 박스를 열어 찾는 과정이다.
위 그림처럼 하나하나 박스들을 열어가면서 데이터를 찾아나서야 한다. 인덱스를 지정해서 바로 이동하는 읽기와는 많이 다르다는 것을 실감할 수 있다. 그래도 다행인 상황은 첫번째에서 찾고자 하는 데이터가 나온 경우이다. 나머지 박스들을 열어보지 않아도되니 얼마나 시간이 단축되겠는가.
하지만 항상 좋은 상황만 있는 것은 아니다. 혹시라도 중간에 껴있으면 불행 중 다행이지만 데이터가 찾고자하는 마지막 순번에 있다면 처음부터 끝까지 접근해서 확인해야하는 상황이 발생한다. 즉, 배열의 길이를 n이라 했을때 검색은 1/n확률로 이루어진다는 것이다.
이러한 배열의 검색은 처음(0)부터 끝까지 찾는 검색 방식을 선형 검색(Linear Search)이라고 한다. 다른 방법도 있다고하니 더 공부를 해보고 알려주도록 하겠다.
추가(insert or add)
배열은 만들어지면서 크기가 정해지고 정해진 크기에 따라 메모리 공간이 미리 확보되어야한다. 이러한 상태에서 배열에 데이터를 추가하는 경우에 대해서 알아보자.
첫번째로 배열의 공간이 데이터로 가득 차있는 상태가 아니라 한자리가 비어있다고 가정하자. 이 경우에는 새로운 데이터를 추가하는 것은 간단하다. 아래의 그림처럼 끝자리에 해당 데이터를 추가하면 다른 데이터들은 영향을 받지 않는다.
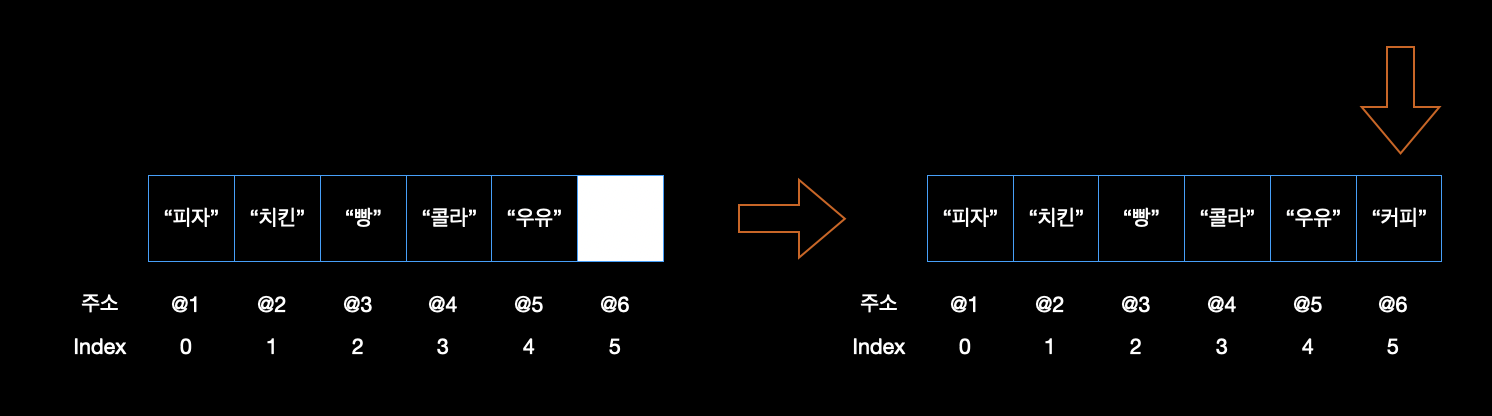
이 경우 크게 속도의 영향을 미치거나 데이터를 처리하는 과정이 복잡하지는 않다. 그렇다면 만약 기존 데이터들 사이에 새로운 데이터를 추가하게되면 어떤 일이 벌어지는지 아래 그림을 통해 알아보자.
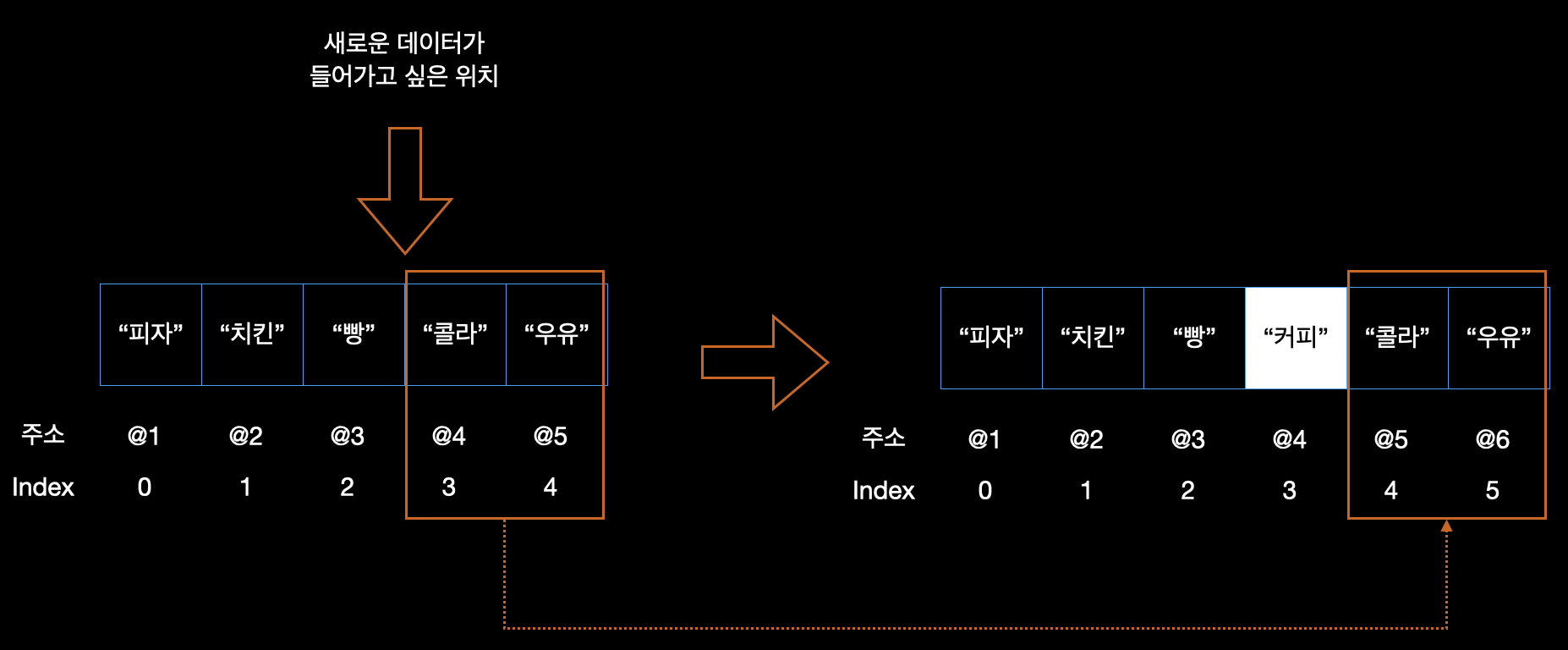
새로운 데이터 "커피"를 기존 데이터인 "빵"과 "콜라" 사이에 추가하려고한다. 이 때 발생하는 과정을 보자.
- "빵"의 위치변화는 일어나지 않으나 "콜라"는 뒤로 한칸 밀려남
- "콜라"의 위치가 밀려남에 따라 그 뒤에 데이터들도 모두 밀려남
- "콜라"의 기존 인덱스(3)을 "커피"가 물려받으며 "콜라"부터는 인덱스가 1씩 증가
위에서 설명한 과정대로 배열내의 데이터의 위치가 변경이 일어난다. 이 말은 배열내에 데이터가 만약 5000개 인데 2500번째 자리에 새로운 데이터를 추가하면 2500번 이후의 데이터는 모두 각각의 인덱스가 1씩 증가해야한다는 말이다. 이러한 데이터가 1만개 이상이라면 어떠한가? 또는 배열의 첫번째 인덱스에 새로운 데이터가 들어간다면? 말하지 않아도 과정이 번거롭다는 것을 알 수 있다.
또한, 배열의 크기가 정해져있고, 이미 데이터도 꽉차있는 상태라면 더 피곤해진다. 이런 경우에는 기존의 배열을 담을 수 있는 더 큰 배열을 만들어 기존 배열을 복사한 뒤 새로운 데이터를 추가해야한다. 복사하고... 데이터들의 인덱스를 1씩 증가시켜 미루고....추가된 데이터는 아무래도 욕을 많이 먹을 것이다.
이러한 이유로 배열에서 데이터 추가는 성능이 좋지 못하고 생각보다 번거롭다.
삭제(Delete)
배열의 삭제는 추가와 비슷한 개념이다. 맨 끝의 데이터를 삭제해야하는 경우 그냥 삭제하고 끝이다. 하지만 추가와 같이 중간 또는 처음 데이터를 삭제하는 경우 각 배열의 데이터들간의 인덱스 조정이 이루어진다. 아래 그림을 보자.
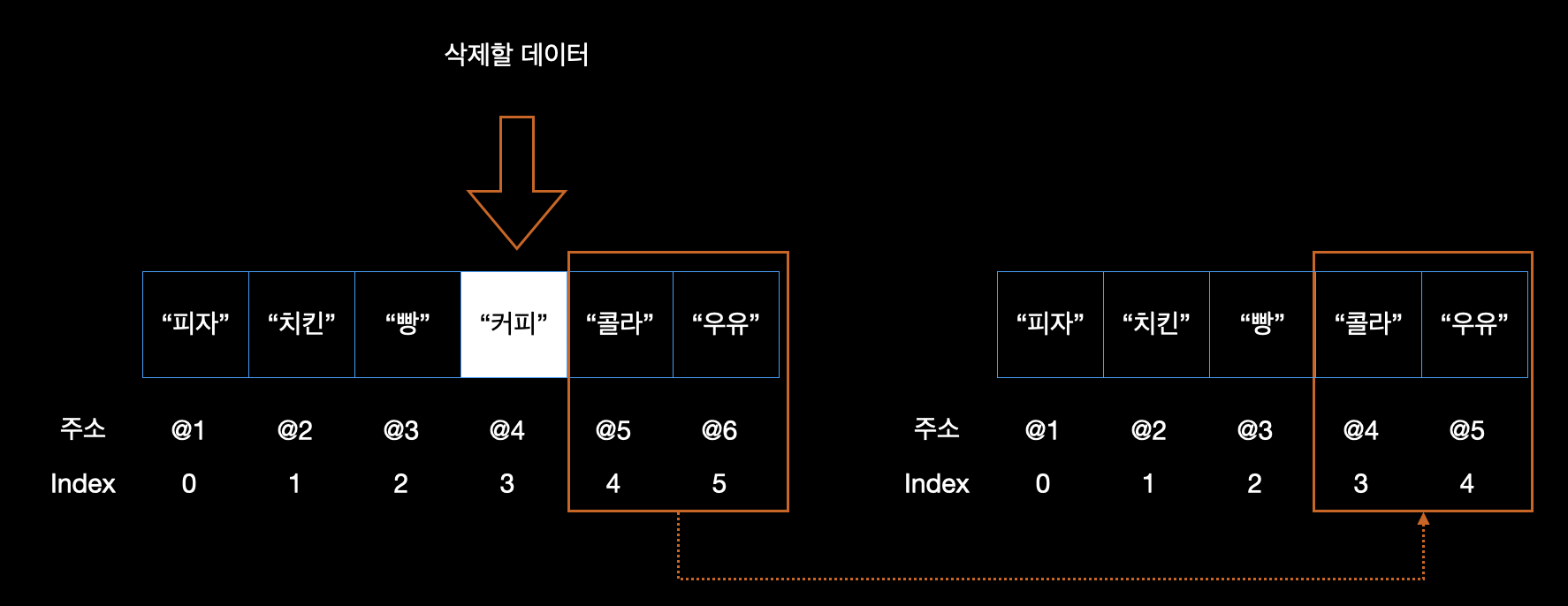
인덱스 3번의 "커피"를 삭제하면 인덱스 4번의 "콜라"부터 그 뒤로 줄줄이 인덱스가 1씩 당겨지는 것이다. 인덱스가 0번이면? 말안해도 알 것이다. 배열은 중간에 공백이 있는 것을 허락하지 않기 때문에 공백을 메우기 위해서 삭제된 데이터의 다음 인덱스부터 앞으로 당겨지는 것이다.
마무리
이렇게해서 오늘은 자료구조의 첫번째 '배열'에 대해서 알아보았다. 부족한 부분도 있을테고 설명이 누락된 부분이 있을 수도 있으니 혹시 있다면 댓글로 남겨주면 감사하겠다.
결론을 말하자면 다음과 같다.
- 읽기 : 배열에서 속도가 가장 빠른 동작
- 검색 : 배열에서 속도가 그다지 빠르지도 느르지도 않은 동작
- 추가 및 삭제 : 배열에서는 속도가 좋지 못한 동작
각 상황에 따라서 구현하고자 하는 기능이 위에서 설명한 부분과 같을 때 참고해서 배열을 사용하면 될 듯하다.
참고
https://www.youtube.com/watch?v=NFETSCJON2M&list=PL7jH19IHhOLMdHvl3KBfFI70r9P0lkJwL&index=2
