주문 서비스 멀티레벨 캐시
캐싱 대상
- 읽기 비율이 압도적으로 높은 데이터
사용자 프로필: userId, 이름, 소속, 슬랙ID, 전화번호, 등급
상품 정보: 상품Id, 허브Id, 상품명
캐시 구조
1차 캐시 L1: Caffeine(in-memory)
2차 캐시 L2: Redis(공유 캐시)
조회 흐름
사용자 프로필: L1→ L2 → UserService API
상품 정보: L1→ L2 → HubService API
캐시 관리 전략
캐시 키 설계
user:profile:{userId}- userId, 이름, 소속, 슬랙ID, 전화번호, 등급
product:{productId}- 상품Id, 허브Id, 상품명, 업체명, 가격(X)
만료 전략
정상 캐시
L1: TTL 5분, TTI 2분30초
L2: TTL 20분
Negative Cache
L1: TTL 15초, TTI 7초 (정상 캐시의 5%)
L2: TTL 1분 (정상 캐시의 5%)
읽기 전략
- Cache Aside: 요청 시 캐시 조회, 없으면 DB 조회 후 캐시 저장
쓰기 전략
- Write Around: 사용자/상품 데이터 변경은 데이터 소유 서비스에서 처리, Order는 캐시만 관리
- 캐시에 저장 시 L1+L2 모두 저장
- 사용자, 상품 데이터 변경 시 이벤트 발행 → Order 서비스에서 구독 L1,L2 모두 캐시 삭제
1차 설계
- Redis pub/sub invalidation으로 L1 캐시 갱신(https://channel.io/ko/team/blog/articles/tech-distributed-cache-1-67a392c5)
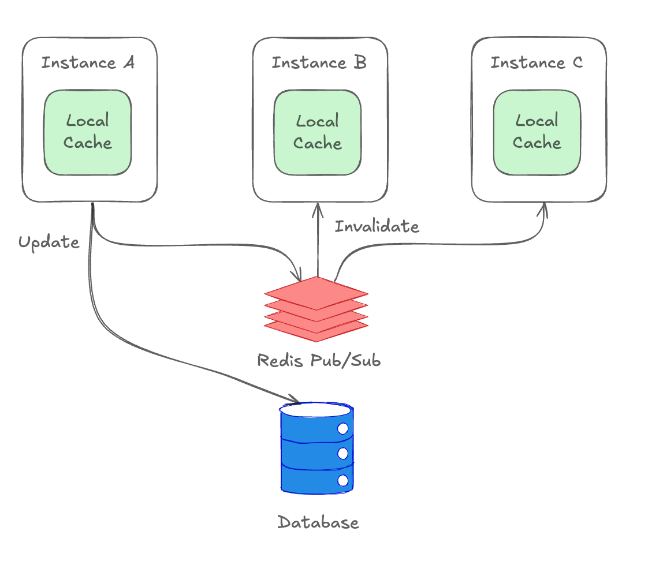
2차 설계
Redis Pub/Sub은 메시지 유실 가능성이 있어 kafka로 변경
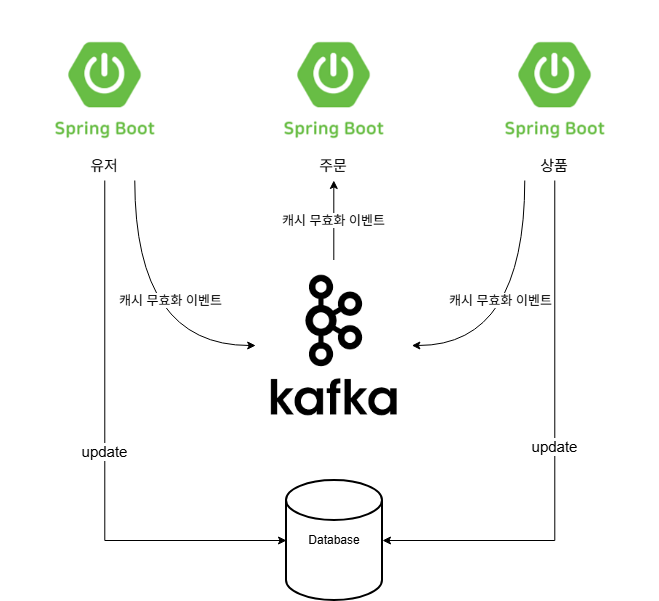
장애/실패 시나리오
Redis 장애 시
- L1 miss → L2(REDIS) 실패 → 사용자/상품 서비스 API 바로 호출
- 캐시 기능은 비활성에 가깝지만 기능은 정상 동작
UserService / HubService 장애 시
- L1/L2 모두 miss → UserService/HubService 호출 실패
- 404 NotFound: null 반환 + 네거티브 캐시 저장
- 5xx / 타임아웃 / 네트워크 장애 등: ExternalApiException 예외 던짐
이벤트 누락 시
- TTL로 만료 기간을 둬서 안전 장치
캐시 스탬피드(Cache Stampede) 방지
- 캐시 스탬피드: key(캐시 항목)가 만료되는 순간 다수의 요청이 동시에 캐시를 갱신하려고 하면서 발생하는 문제 (https://jhzlo.tistory.com/69)
- 문제점: DB 부하가 급증하고 시스템 응답 시간이 느려지거나 장애가 발생
- 대응
- TTL에 랜덤 지터(±10~20%) 적용해서 동시 만료 방지
- L2 캐시에서 PER(Probabilistic Early Refresh) 알고리즘 적용 : TTL 만료되기 전에 확률적으로 데이터를 갱신하는 기법

Stale Cache
L1 miss → L2 캐시 조회 하는 상황에서 만약 L2 캐시의 TTL이 만료 직전인 stale 데이터라면?
threshold 2분30초 ( L1 캐시의 TTL 시간의 50% )
L2의 데이터가 TTL <= threshold 이면 DB 조회해서 새로 갱신Negative Caching
존재하지 않는 데이터(= null, empty)도 캐시에 넣어서, ‘없는 데이터’ 조회가 반복될 때 원본(DB, 외부 API)을 계속 호출하지 않도록 막는 기법
TTL 시간 정상 캐시의 10%
L1: 30초
L2: 2분
모니터링/ 알람
모니터링 지표
- L1,L2 캐시 히트율
- Redis 지표: 메모리 사용량, 명령어 QPS
- Redis pub/sub 이벤트 소비 상태 -> kafka 이벤트 소비 상태
알람
- L1/L2 hit ratio가 특정 값 이하로 떨어질 때

한결같이