1. 최장 증가 수열 (LIS, Longest Increasing Subsequence)
최장 증가 수열, 정확히 최장 증가 부분 수열은 어떠한 수열에서 오름차순으로 증가하는 가장 긴 부분수열을 의미한다.
이 떄, 부분 수열의 각 수는 서로 연속할 필요는 없다.
아래의 예시 수열을 보자.
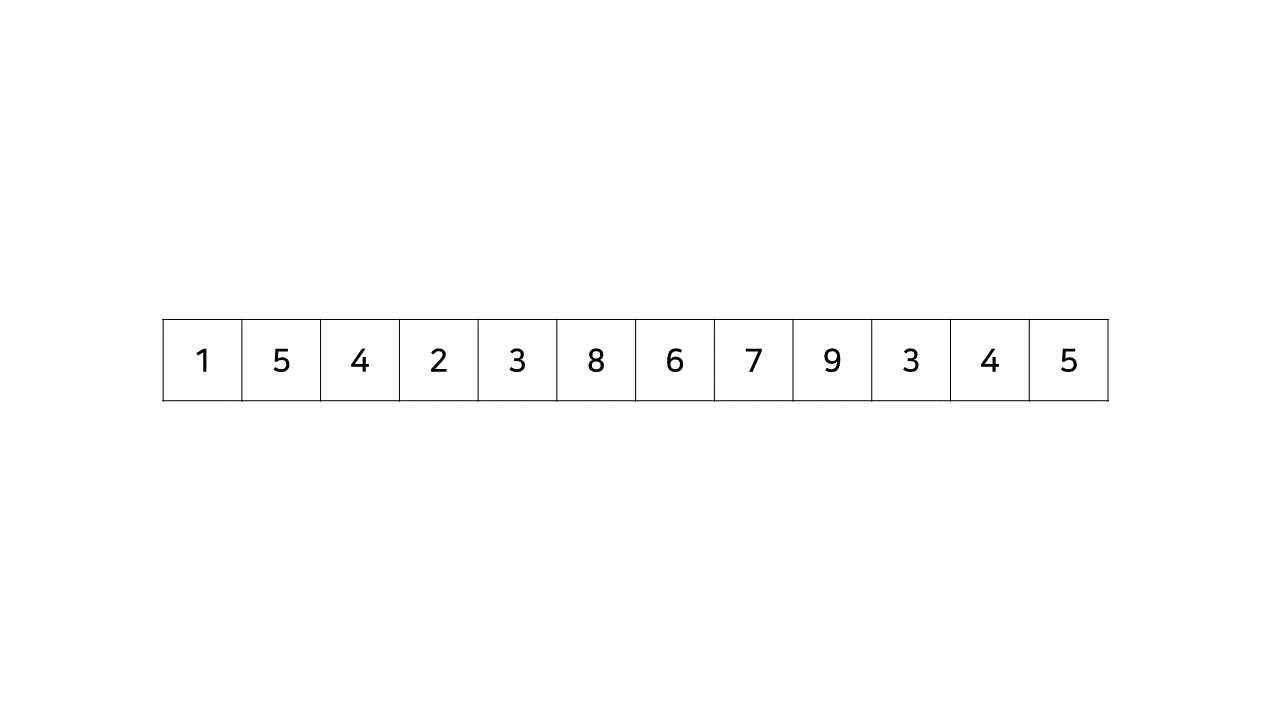
위 수열에서 최장 증가 수열을 찾으면 아래와 같다.
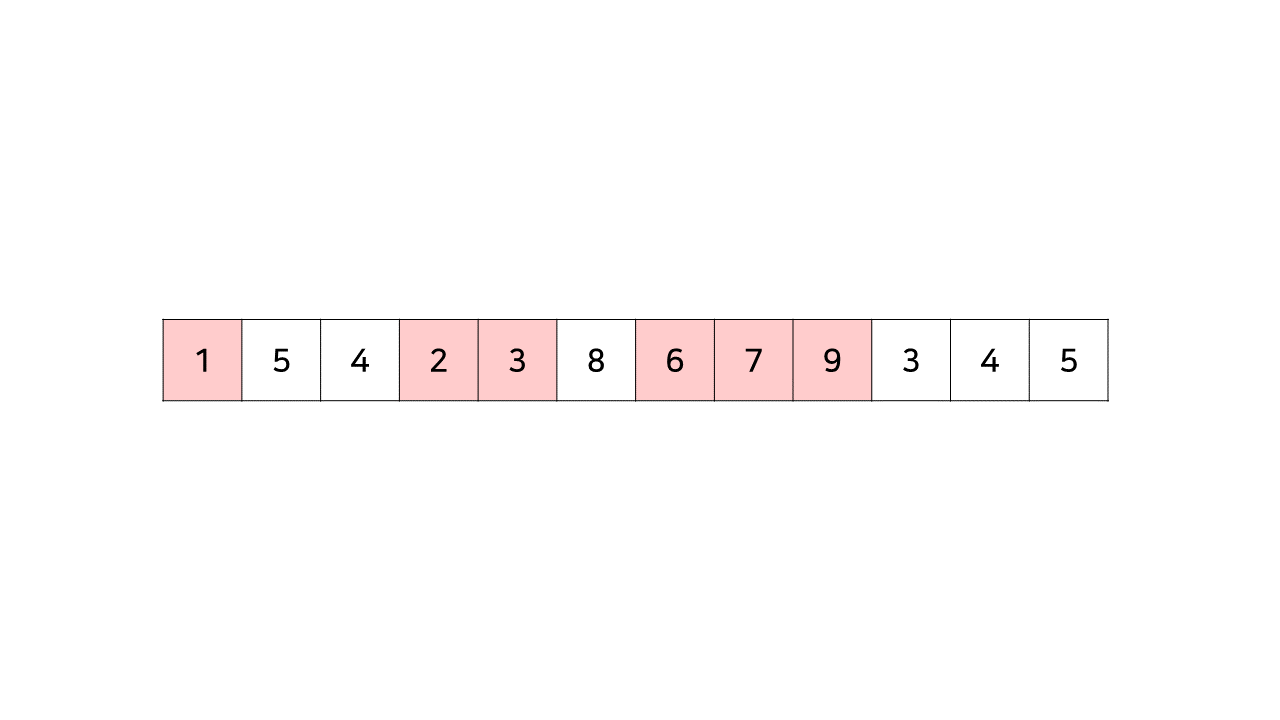
그림에서 붉은 칸으로 칠해진 부분 수열 (1, 2, 3, 6, 7, 9) 는 전체 수열 중 오름차순으로 증가하는 가장 긴 부분수열이다.
이제 주어진 수열에서 LIS의 길이를 구하는 두 가지 방법을 알아보자.
다이나믹 프로그래밍을 이용한 방법 : O(N^2)
이러한 최장 증가 수열을 찾는 가장 단순한 방법은 완전 탐색일 것이다.
하지만 수열에 존재하는 수의 개수가 k개일 때, 1개 이상의 원소를 갖는 모든 부분수열의 가짓수는 2^k개이므로, 모든 부분수열을 확인해 이들이 오름차순으로 정렬되어 있는지 확인하는 것은 매우 비효율적이다.
따라서 우리는 다이나믹 프로그래밍을 통해 이를 구현할 수 있다.
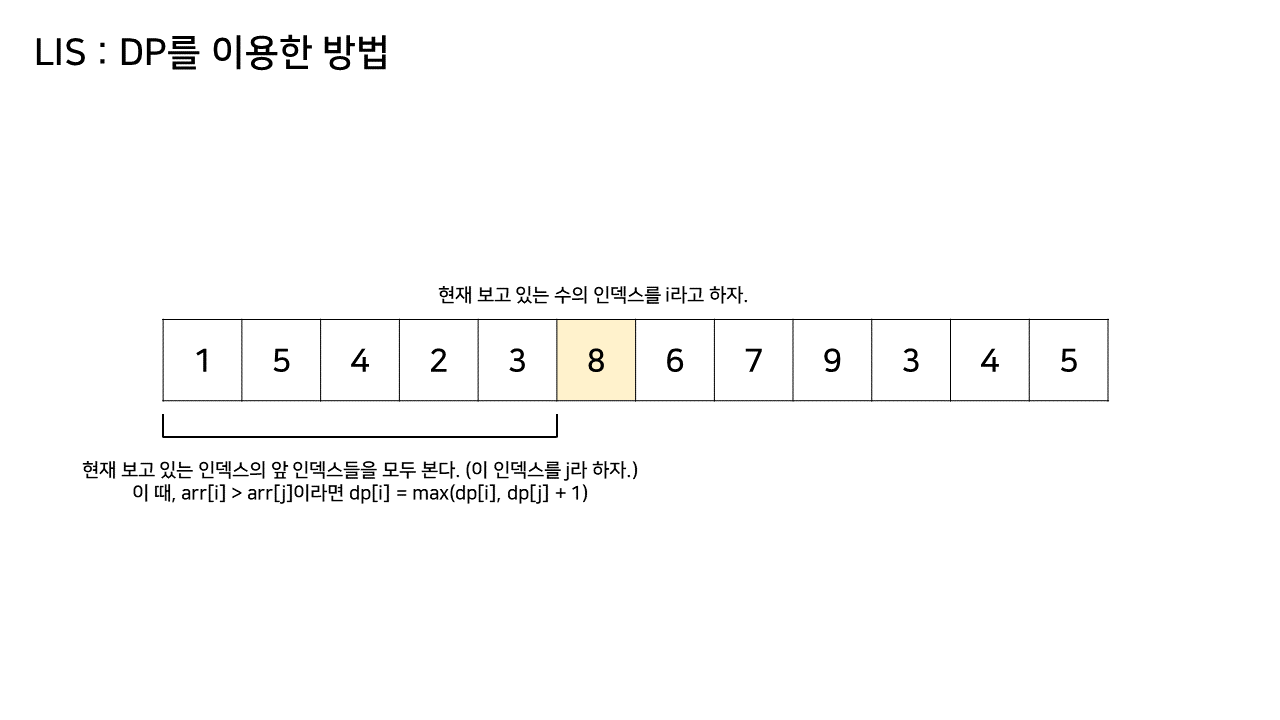
수열의 한 원소에 대해, 그 원소에서 끝나는 최장 증가 수열을 생각해보자. 그 최장 증가 수열의 k를 제외한 모든 원소들은 반드시 k보다 작아야 할 것이다.
따라서 k의 앞 순서에 있는 모든 원소들 중 값이 k보다 작은 원소에 대해, 그 각각의 원소에서 끝나는 최장 증가 수열의 길이를 알고 있다면, k에서 끝나는 최장 증가 수열의 길이도 구할 수 있을 것이다.
위의 예시에서는 8 이전의 (1, 5, 4, 2, 3)까지의 수열 중 각각의 원소에서 끝나는 최장 증가 수열의 길이는 다음과 같다.
-
1에서 끝나는 LIS 길이 : 1 (1)
-
5에서 끝나는 LIS 길이 : 2 (1, 5)
-
4에서 끝나는 LIS 길이 : 2 (1, 4)
-
2에서 끝나는 LIS 길이 : 2 (1, 2)
-
3에서 끝나는 LIS 길이 : 3 (1, 2, 3)
이들 중 가장 긴 (1, 2, 3)에 현재 수 8을 더한 (1, 2, 3, 8)이 8에서 끝나는 최장 증가 수열이 된다.
즉, 앞 순서의 모든 원소에서 끝나는 최장 증가 수열들의 길이 중 가장 긴 것을 골라 1을 더한 것이 곧 현재 수에서 끝나는 최장 증가 수열의 길이이다.
따라서 dp[i] = "i번째 인덱스에서 끝나는 최장 증가 수열의 길이"로 정의한다.
[코드]
void LIS_DP() {
for (int i = 0; i < n; i++) {
dp[i] = 1; //해당 원소에서 끝나는 LIS 길이의 최솟값. 즉, 자기 자신
for (int j = 0; j < i; j++) {
//i번째 이전의 모든 원소에 대해, 그 원소에서 끝나는 LIS의 길이를 확인한다.
if (arr[i] > arr[j]) {
//단, 이는 현재 수가 그 원소보다 클 때만 확인한다.
dp[i] = max(dp[i], dp[j] + 1); //dp[j] + 1 : 이전 원소에서 끝나는 LIS에 현재 수를 붙인 새 LIS 길이
}
}
}
}이분 탐색을 이용한 방법 : O(NlogN)
DP를 이용한 방법은 분명 완전 탐색에 비해 시간 복잡도 면에서 효율적이지만, 여전히 O(N^2)이라는 점이 발목을 잡는다.
이 때, 이분 탐색(Binary Search)을 사용하면 시간 복잡도를 O(NlogN)으로 줄일 수 있다.
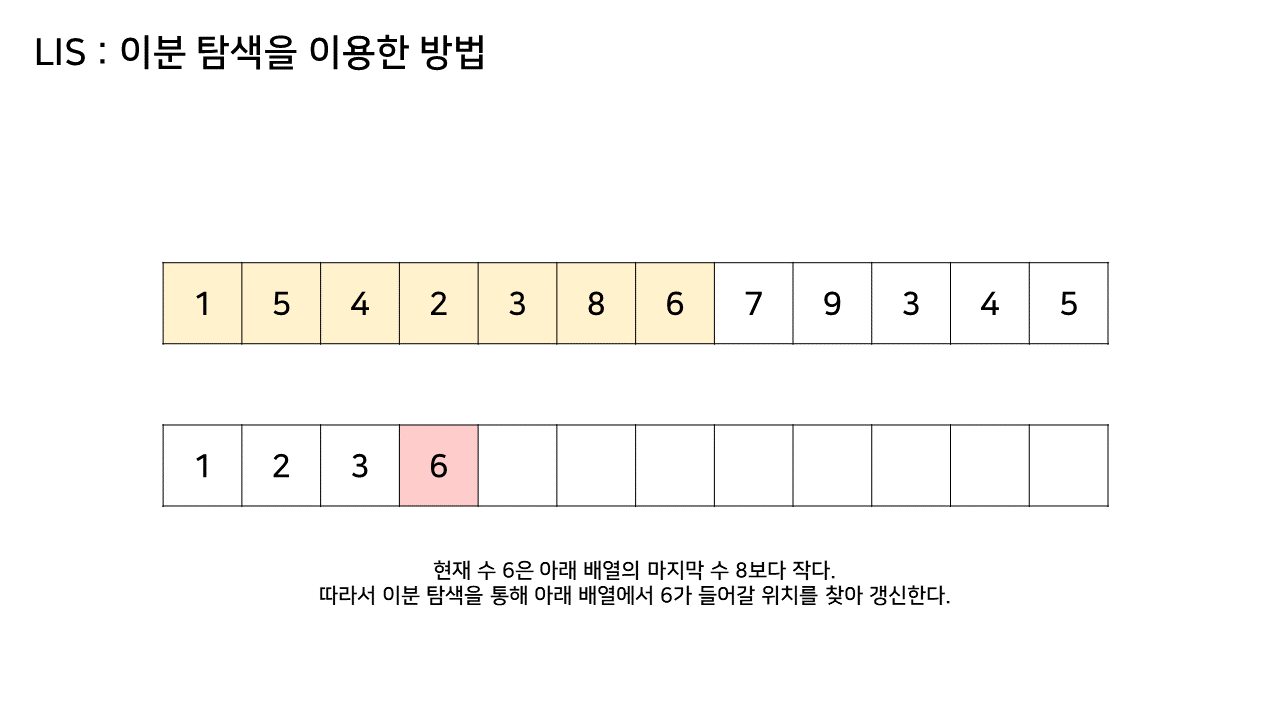
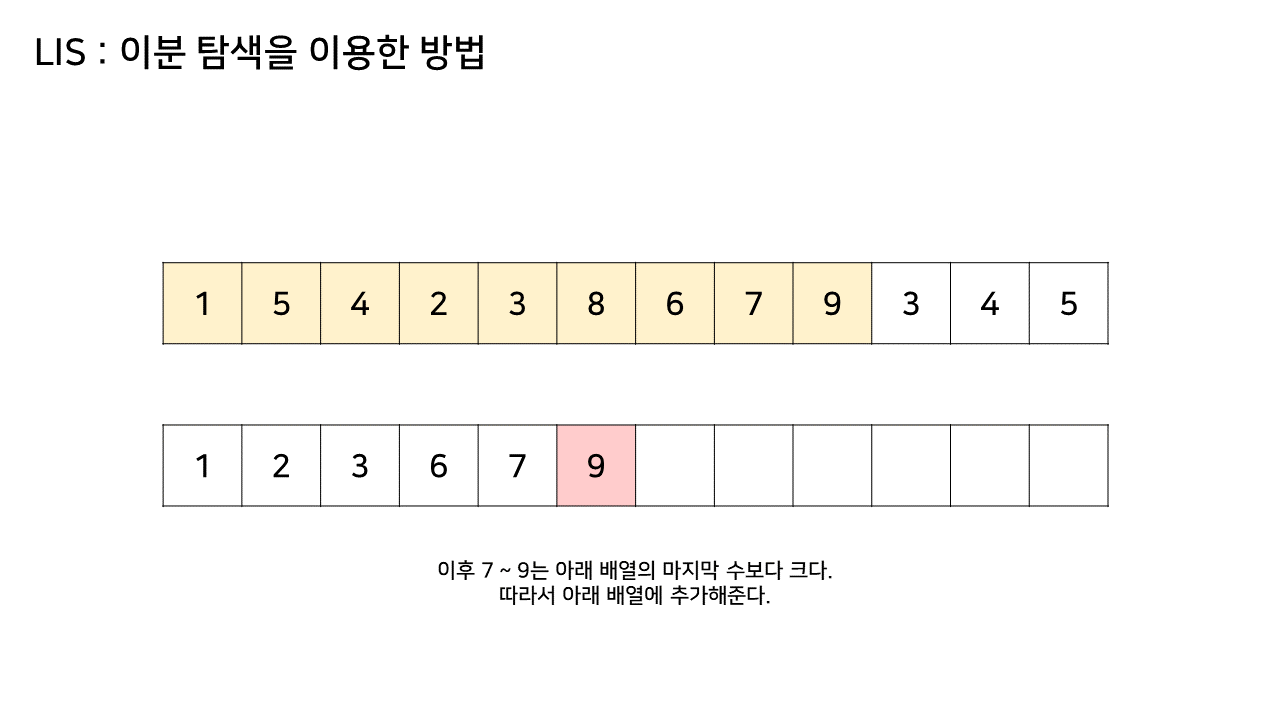
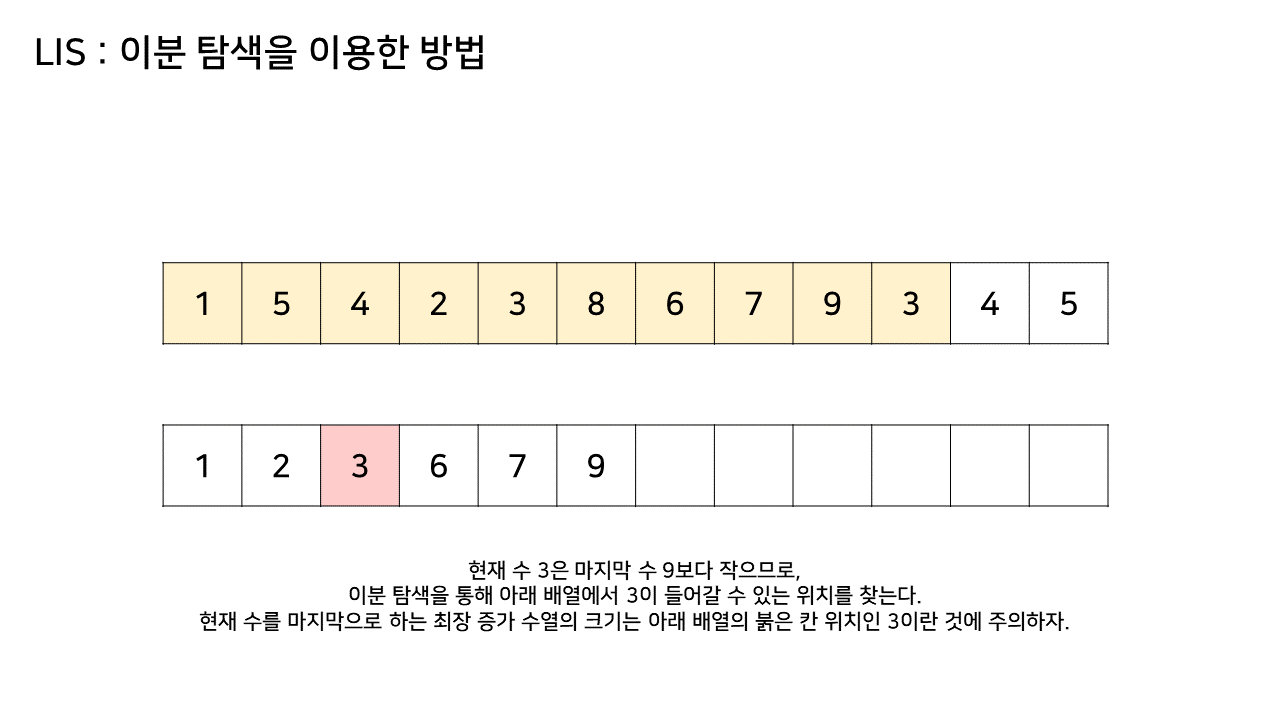
이 방법에서는 LIS를 기록하는 배열을 하나 더 두고, 원래 수열에서의 각 원소에 대해 LIS 배열 내에서의 위치를 찾는다.
자세한 것은 아래 과정을 보자.
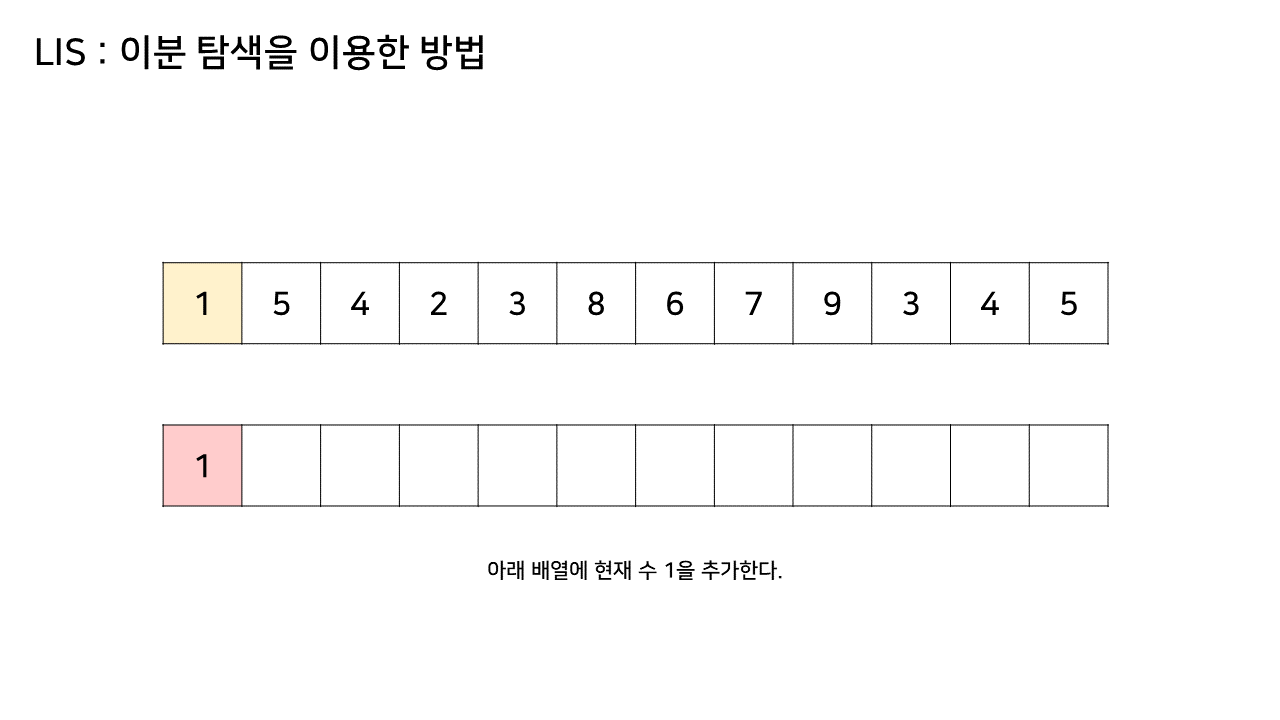
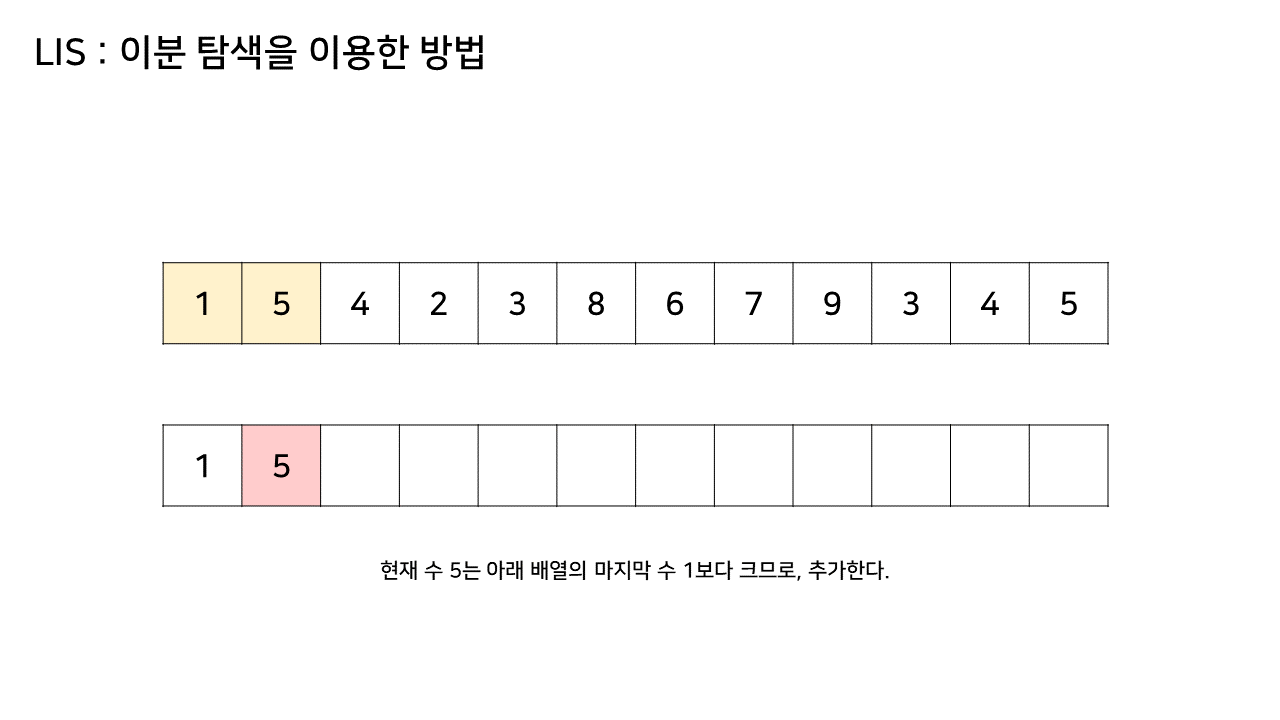
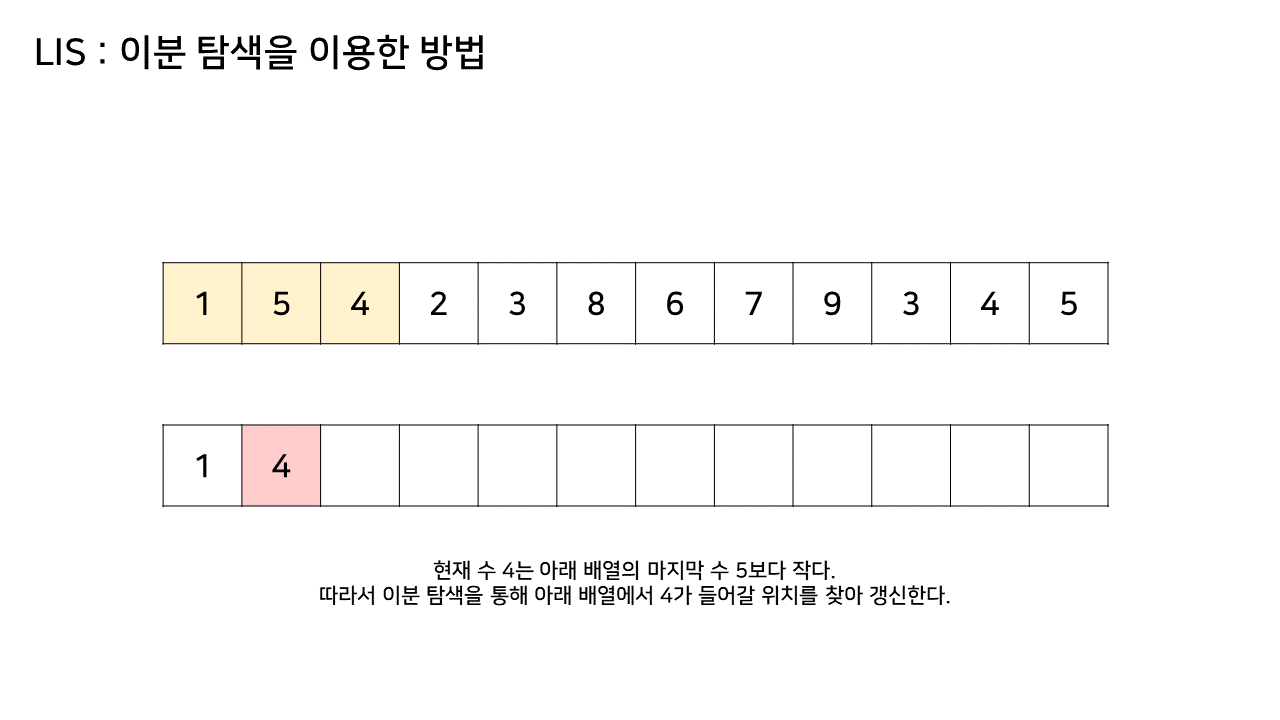
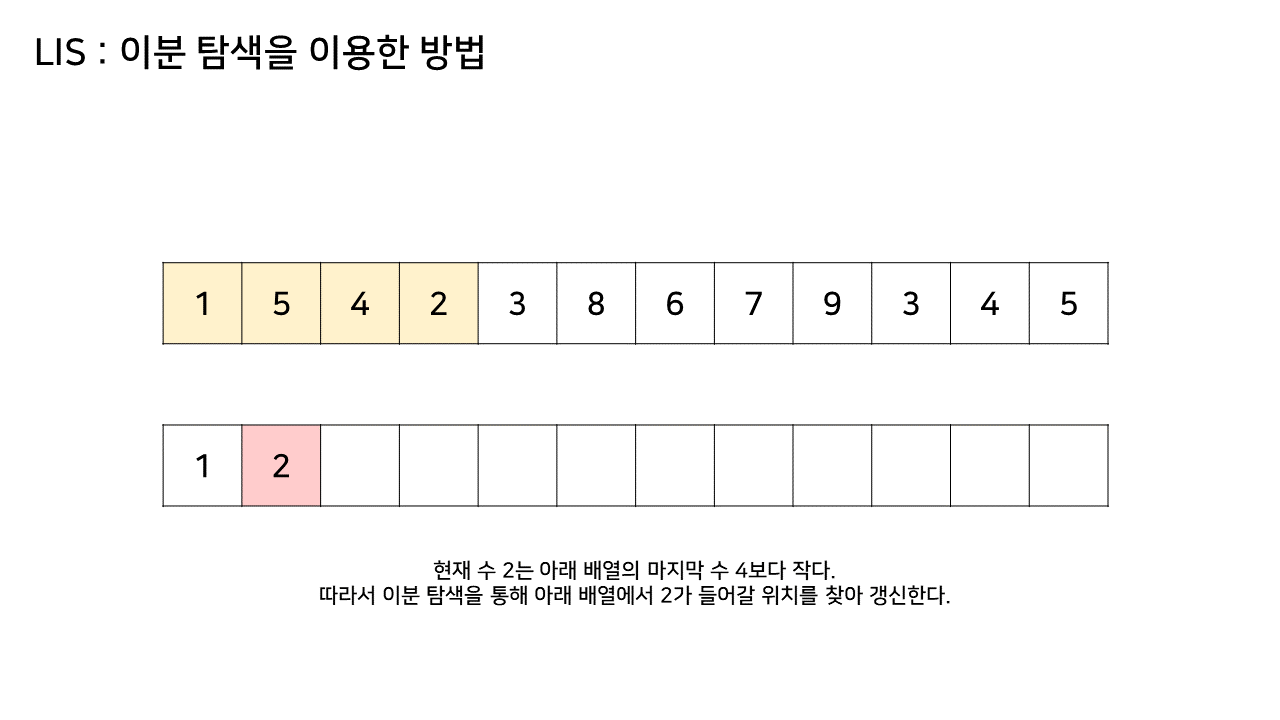
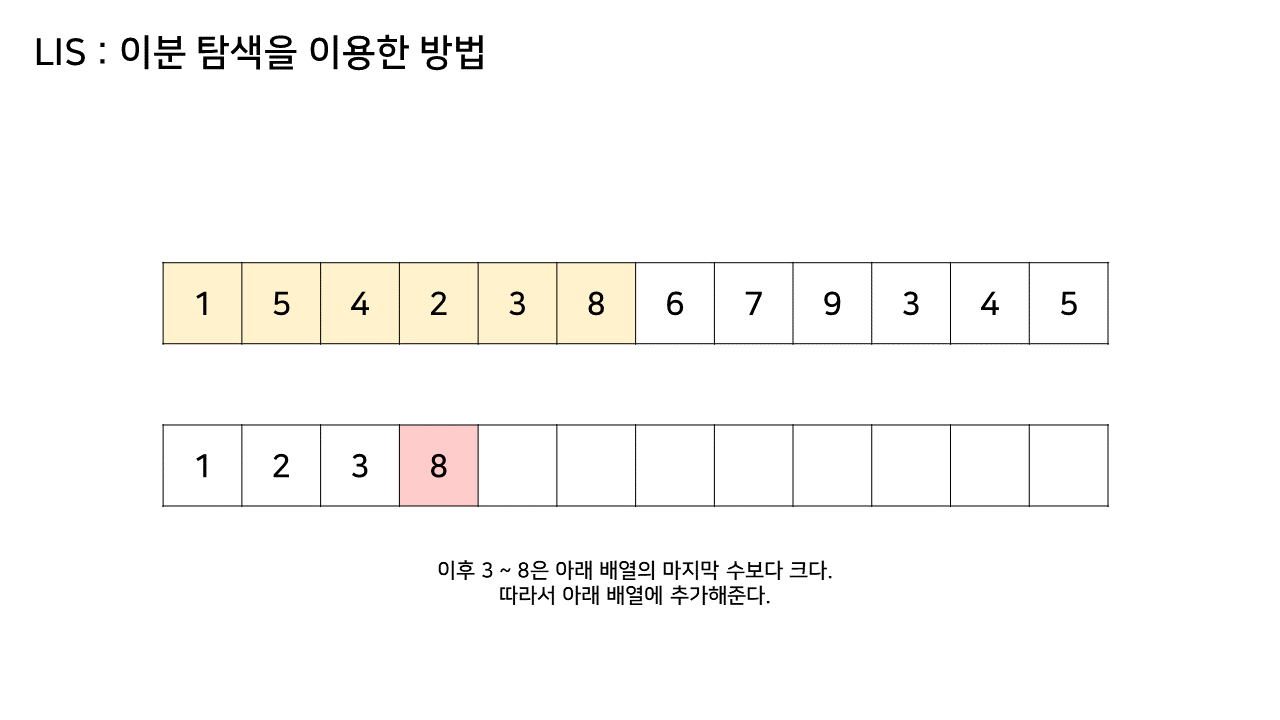
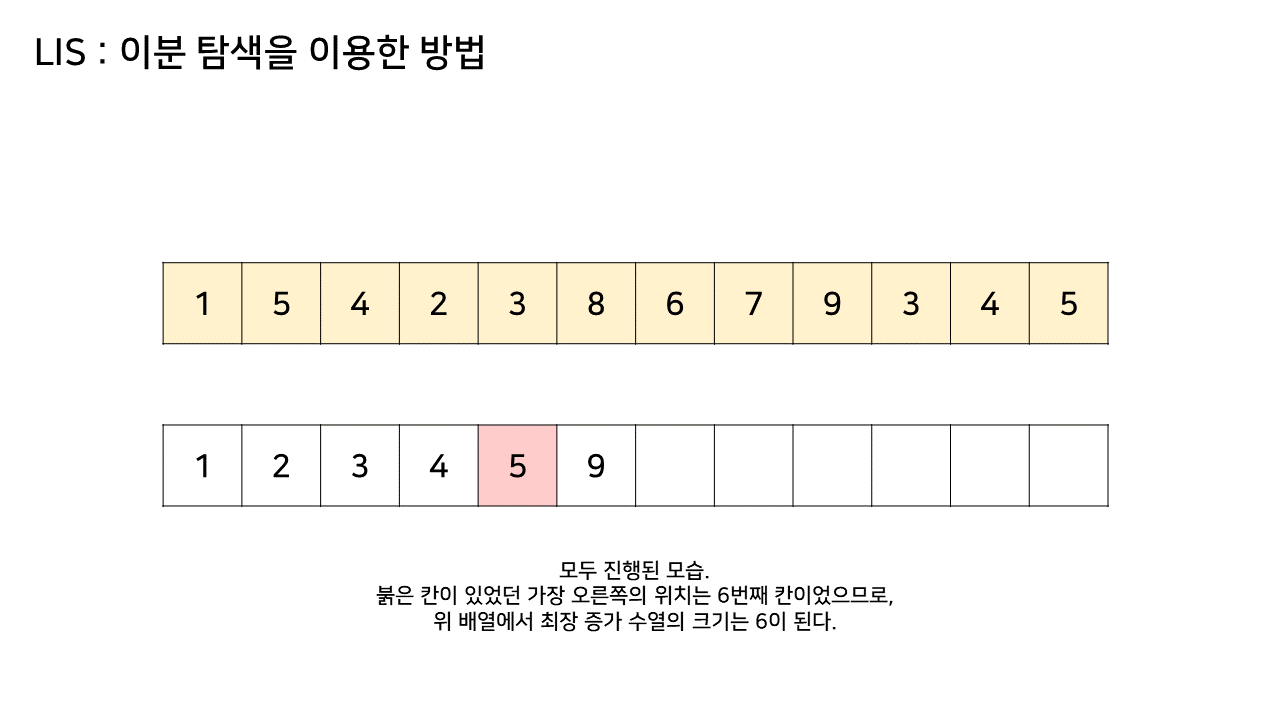
그림의 아래 배열의 크기는 최대 6까지 갔었으므로, LIS의 길이는 6이 된다.
이 방법은 그림의 아래 배열을 LIS의 형태로 유지하기 위해, 기존 수열의 각 원소가 LIS에 들어갈 위치를 찾는 원리로 동작한다.
즉, 현재 원소를 아래 배열에 넣어 LIS를 유지하려고 할 때, 그 최적의 위치를 찾는 것이다.
2. 실전문제
가장 긴 증가하는 부분 수열 (백준 11053)
다이나믹 프로그래밍(DP)을 이용한 방법
import java.io.*;
import java.util.StringTokenizer;
public class P11053_가장긴증가하는부분수열 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
int N = Integer.parseInt(br.readLine());
int[] A = new int[N];
int[] dp = new int[N];
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 0; i < N; i++) {
A[i] = Integer.parseInt(st.nextToken());
}
for (int i = 0; i < N; i++) {
dp[i] = 1;
for (int j = 0; j <= i; j++) {
if (A[i] > A[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}
}
int max = 0;
for (int i = 0; i < N; i++) {
if (max < dp[i]) max = dp[i];
}
bw.write(max + "");
bw.flush();
bw.close();
br.close();
}
}이분 탐색을 이용한 방법
import java.io.*;
import java.util.StringTokenizer;
public class P11053_가장긴증가하는부분수열 {
static int N;
static int[] A, dp;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
N = Integer.parseInt(br.readLine());
A = new int[N];
dp = new int[N];
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 0; i < N; i++) {
A[i] = Integer.parseInt(st.nextToken());
}
int LIS = 0;
for (int i = 0; i < N; i++) {
int idx = BinarySearch(A[i], 0, LIS, LIS + 1);
if (idx == -1) {
dp[LIS++] = A[i];
} else {
dp[idx] = A[i];
}
}
bw.write(LIS + "");
bw.flush();
bw.close();
br.close();
}
private static int BinarySearch(int num, int start, int end, int size) {
int res = 0;
while (start <= end) {
int mid = (start + end) / 2;
if (num <= dp[mid]) {
res = mid;
end = mid - 1;
} else {
start = mid + 1;
}
}
if (start == size) {
return -1;
} else {
return res;
}
}
}

