1. 트리 (tree)
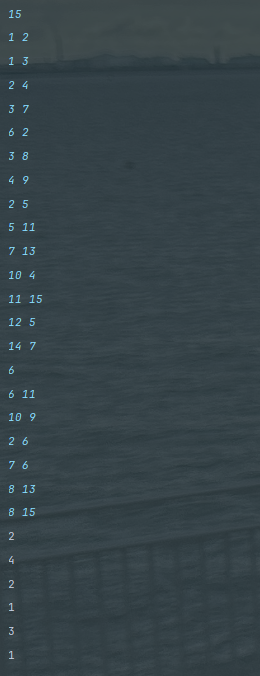
트리는 노드와 에지로 연결된 그래프의 특수한 형태이다.
트리의 특징
- 순환 구조를 지니고 있지 않고, 1개의 루트 노드가 존재한다.
- 루트 노드를 제외한 노드는 단 1개의 부모 노드를 갖는다.
- 트리의 부분 트리 역시 트리의 모든 특징을 따른다.
트리의 핵심 이론

2. 이진 트리
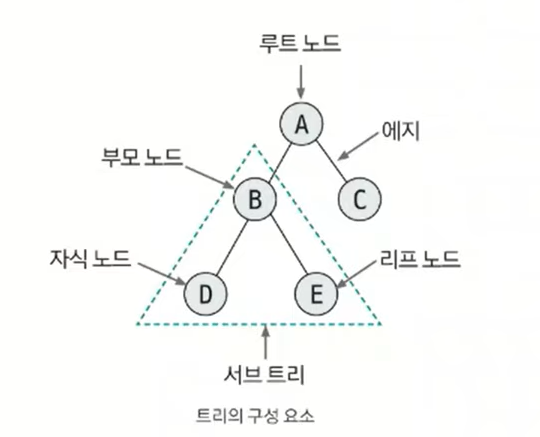
이진 트리는 각 노드의 자식 노드(차수)의 개수 2이하로 구성된 트리를 말한다.
트리 영역에서 가장 많이 사용되는 형태이다.
이진 트리의 핵심이론
이진 트리의 종류
이진 트리에는 편향 이진 트리, 포화 이진 트리, 완전 이진 트리가 있다. 편향 이진 트리는 노드들이 한쪽으로 편향돼 생성된 이진 트리, 포화 이진 트리는 트리의 높이가 모두 일정하며 리프 노드가 꽉 찬 이진 트리, 완전 이진 트리는 마지막 레벨을 제외하고 완전하게 노드들이 채워져 있고, 마지막 레벨은 왼쪽부터 채워진 트리이다.
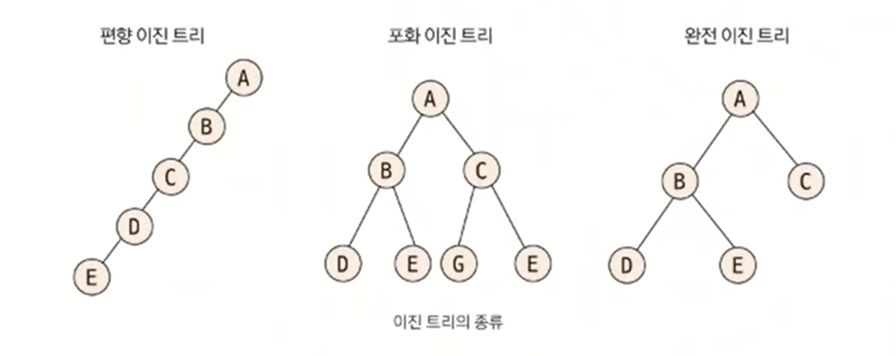
데이터를 트리 자료구조에 저장할 때 편향 이진 트리의 형태로 저장하면 탐색 속도가 저하되고 공간이 많이 낭비되는 단점이 있다. 일반적으로 코딩 테스트에서 데이터를 트리에 담는다고 하면 완전 이진 트리 형태를 떠올리면 된다.
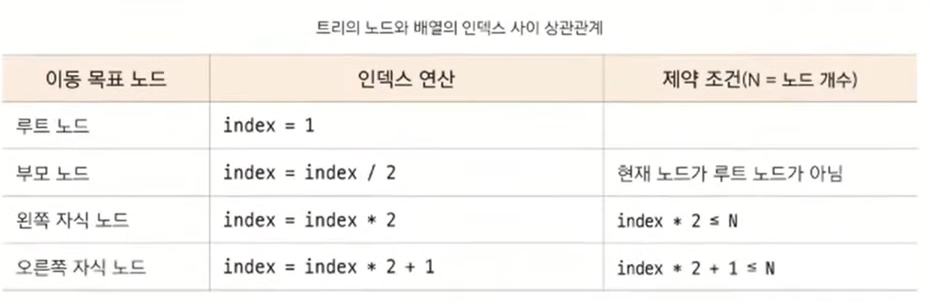
이진 트리의 순차 표현
가장 직관적이면서 편리한 자료구조 형태는 '배열'이다.
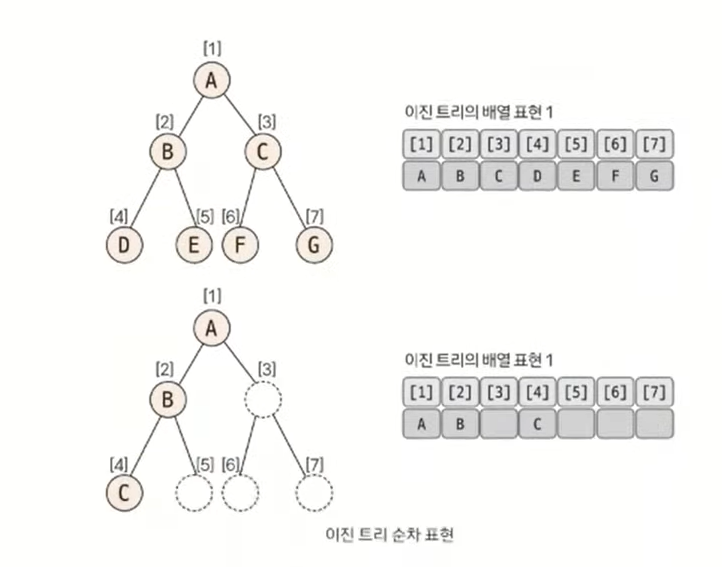
이진 트리는 위와 같이 1차원 배열의 형태로 표현할 수 있다.
3. 세그먼트 트리
주어진 데이터의 구간 합과 데이터 업데이트를 빠르게 수행하기 위해 고안해낸 자료구조의 형태가 바로 세그먼트 트리이다. 더 큰 범위는 '인덱스 트리'라고 불리는데, 코딩 테스트 영역에서는 큰 차이가 없다.
세그먼트 트리의 핵심 이론
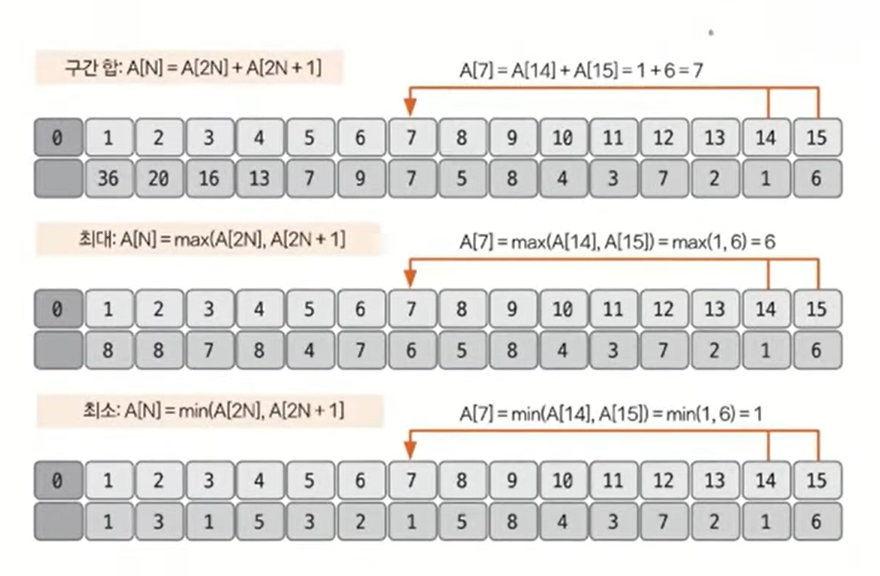
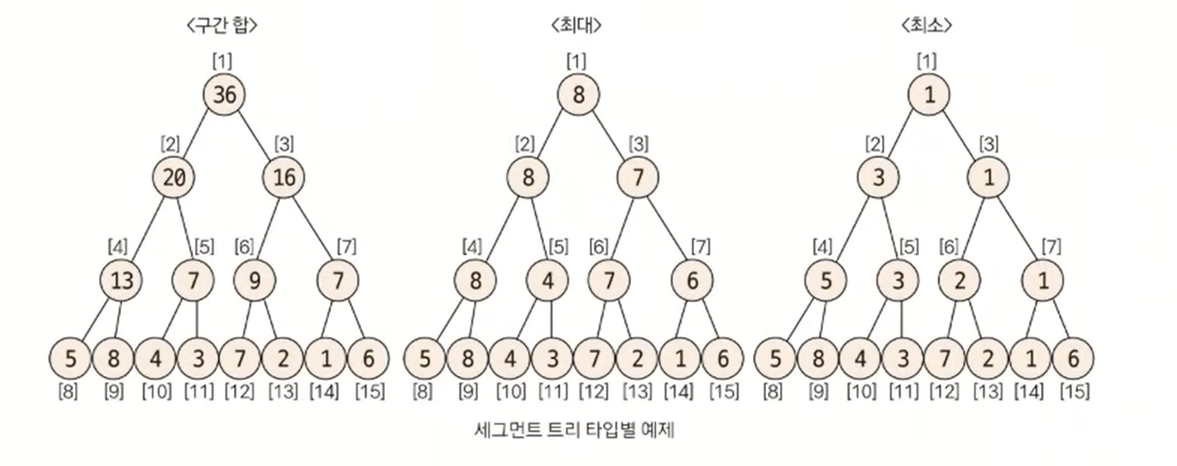
세그먼트 트리의 종류는 구간 합, 최대&최소 구하기로 나눌 수 있고, 구현 단계는 트리 초기화하기, 질의값 구하기(구간합 또는 최대&최소), 데이터 업데이트하기로 나눌 수 있다.
1. 트리 초기화하기
리프 노드의 개수가 데이터의 개수(N)이상이 되도록 트리 배열을 만든다. 트리 배열의 크기를 구하는 방법은 2^k >= N을 만족하는 k의 최솟값을 구한 후 2^k x 2를 트리 배열의 크기로 정의하면 된다. 예를 들어 N = 8이면 2^3 >= 8이므로 배열의 크기를 2^3 x 2 = 16으로 정의한다.
샘플 데이터 = {5, 8, 4, 3, 7, 1, 6}
리프 노드에 원본 데이터를 입력한다. 이때 리프 노드의 시작 위치를 트리 배열의 인덱스로 구해야 하는데, 구하는 방식은 2^k를 시작 인덱스로 취하면 된다. 예를 들어 k의 값이 3이면 start index = 8이 된다.

리프 노드를 제외한 나머지 노드의 값을 채운다. 채워야 하는 인덱스가 N이라고 가정하면 자신의 자식 노드를 이용해 해당 값을 채울 수 있다. 자식 노드의 인덱스는 이진 트리 형식이기 때문에 2N, 2N+1이 된다.
2. 질의값 구하기
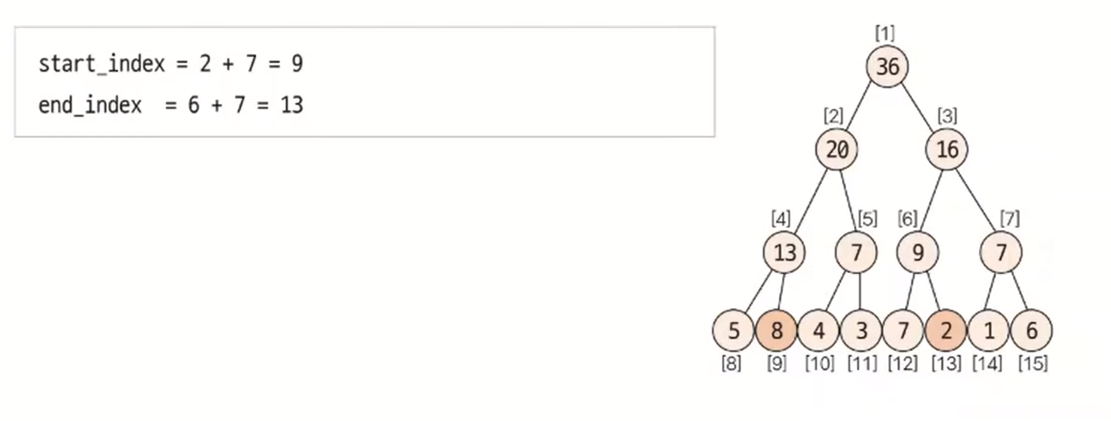
주어진 질의 인덱스를 세그먼트 트리의 리프 노드에 해당하는 인덱스로 변경한다. 기존 샘플을 기준으로 한 인덱스값과 세그먼트 트리 배열에서의 인덱스값이 다르기 떄문에 인덱스를 변경해야 한다.
질의 인덱스를 세그먼트 트리 인덱스로 변경하는 방법
세그먼트 트리 index = 주어진 질의 index + 2^k - 1
질의에서의 시작 인데스와 종료 인덱스에 관해 부모 노드로 이동하면서 주어진 질의에 해당하는 값을 다음과 같이 구한다.
질의값 구하는 과정
1. start_index % 2 == 1일 때 해당 노드를 선택한다.
2. end_index % 2 == 0일 때 해당 노드를 선택한다.
3. start_index depth 변경 : start_index = (start_index + 1) / 2 연산을 실행한다.
4. end_index depth 변경 : end_index = (end_index + 1) / 2 연산을 실행한다.
5. 1~4를 반복하다가 end_index < start_index가 되면 종료한다.
먼저 리프 노드의 인덱스로 변경
부모 노드로 이동

3. 데이터 업데이트
업데이트 방식은 자신의 부모 노드로 이동하면서 업데이트한다는 것은 동일하지만, 어떤 값으로 업데이트할 것인지에 관해서는 트리 타입별로 조금 다르다.
*부모 노드로 이동하는 방식은 세그먼트 트리가 이진 트리이므로 index = index / 2 로 변경하면 된다.
구간 합에서는 원래 데이터와 변경 데이터의 차이만큼 부모 노드로 올라가면서 변경한다. 최댓값 찾기에서는 변경 데이터와 자신과 같은 부모를 지니고 있는 다른 자식 노드와 비교해 더 큰 값으로 업데이트한다. 업데이트가 일어나지 않으면 종료한다. 마지막으로 최솟값 찾기에서는 변경 데이터와 자신과 같은 부모를 지니고 있는 다른 자식 노드와 비교해 더 작은 값으로 업데이트한다. 업데이트가 일어나지 않으면 종료한다.
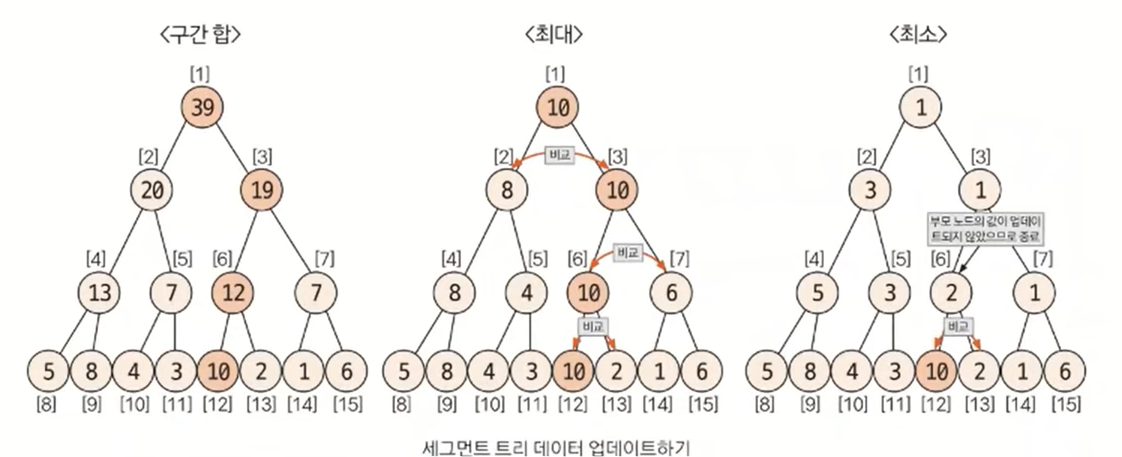
요약
-
트리 초기화하기
1-1. 크기 정하기 ( 2^k >= N의 k의 최솟값 구한 후 x2)
1-2. 부모 노드까지 값 채우기 (2^k부터 리프 노드 채운 후 부모 노드 채운다) -
질의값구하기
2-1. 질의 index를 트리에 맞게 변경 (주어진 질의 index + 2^k - 1)
2-2. start_index % 2 == 1 & end_index % 2 == 0일 때 해당 노드를 선택 -
업데이트
4. 일반적인 최소 공통 조상 (LCA)
트리 그래프에서 임의의 두 노드를 선택했을 때 두 노드가 각각 자신을 포함해 거슬러 올라가면서 부모 노드를 탐색할 때 처음 공통으로 만나게 되는 부모 노드를 '최소 공통 조상'이라고 한다.
최소 공통 조상의 핵심 이론
일반적인 최소 공통 조상 구하기
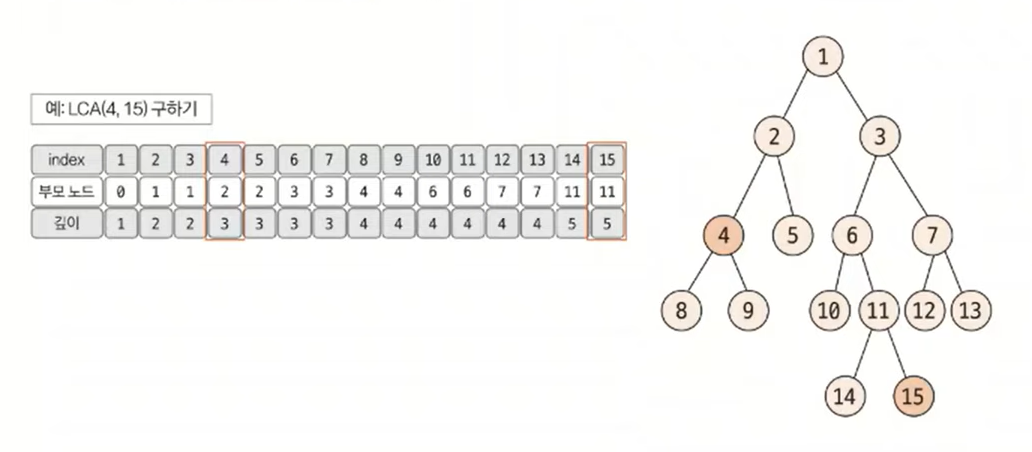
먼저 트리의 높이가 크지 않을 때 사용한다. 다음과 같은 트리에서 4번, 15번 노드의 최소 공통 조상을 구해보자. 먼저 루트 노드에서 탐색을 시작해 각 노드의 부모 노드와 깊이를 저장한다.
선택된 두 노드의 깊이가 다른 경우, 더 깊은 노드의 노드를 부모 노드로 1개씩 올려 주면서 같은 깊이로 맞춘다. 이 떄 두 노드가 같으면 해당 노드가 최소 공통 조상이므로 탐색을 종료한다.
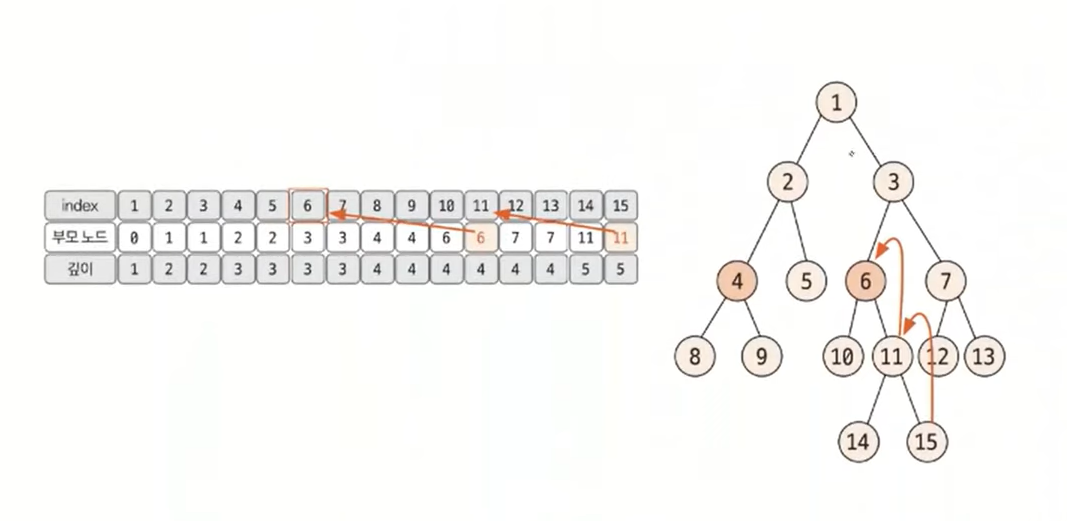
깊이가 같은 상태에서는 동시에 부모 노드로 올라가면서 두 노드가 같은 노드가 될 때까지 반복한다. 이때 처음 만나는 노드가 최소 공통 조상이 된다. 이러한 원리로 다음 트리에서 4번, 15번 노드의 최소 공통 부모는 1이 된다.
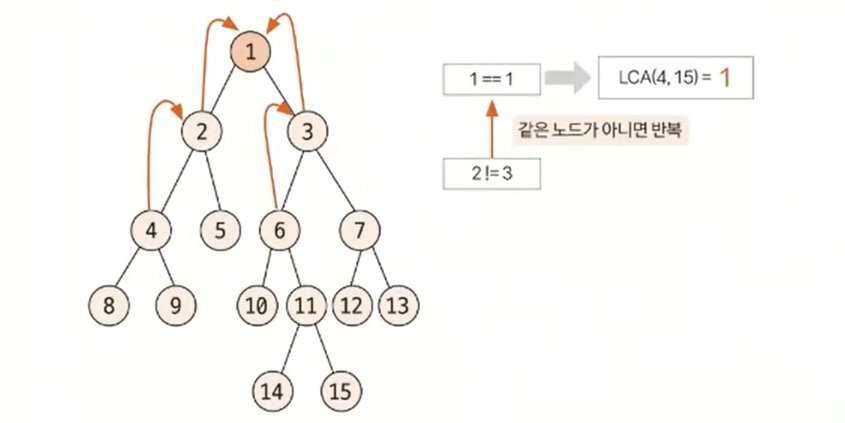
위와 같은 방식을 이용하면 최소 공통 조상을 구할 수 있지만, 트리의 높이가 커질 경우 시간 제약 문제에 직면할 수 있다. 이러한 문제를 해결하기 위해 새롭게 제안된 방식인 '최소 공통 조상 빠르게 구하기'가 있다. '최소 공통 조상 빠르게 구하기'는 일반적인 최소 공통 조상 구하기 알고리즘을 야간 변형한 형태이다.
5. 빠른 최소 공통 조상 (LCA)
빠른 최소 공통 조상의 핵심은 서로의 깊이를 맞춰 주거나 같아지는 노도를 찾을 때 기존에 한 단계식 올려 주는 방식에서 2^K씩 올라가 비교하는 방식이다. 따라서 기존에 자신의 부모 노드만 저장해 놓던 방식에서 2^K번째 위치의 부모 노드까지 저장해 둬야 한다.
1. 부모 노드 저장 배열을 만든다.
부모 노드 배열의 정의
P[K][N] = N번 노드의 2^K번쨰 부모의 노드 번호
부모 노드 배열의 점화식
P[K][N] = P[K-1]P[K-1][N]]
점화식에서 N의 2^K번째 부모 노드는 N의 2^K-1번째 부모 노드의 2^K-1번쨰 부모 노드라는 의미이다. 즉, K=4라고 가정하면 N의 16번째 부모 노드는 N의 여덟 번째 부모 노드의 여덟 번째 부모 노드라는 의미이다.
배열에서 K는 '트리의 깊이 > 2^K를 만족하는 최댓값이다. 다음 트리에서 최대 깊이는 5이기 때문에 K=2가 된다. 즉, 이 트리의 모든 노드는 2^3번째 부모 노드를 지닌 경우가 없다.
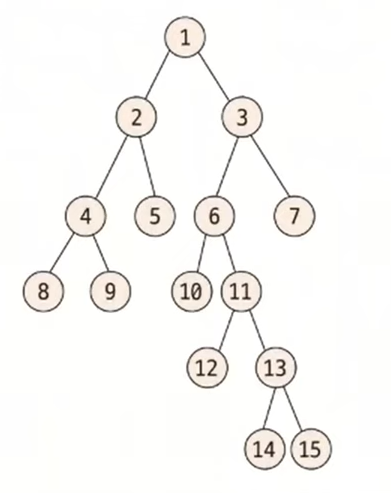
부모 노드 배열의 점화식을 이용해 배열의 값을 채워 본다.

초기화된 배열을 바탕으로 K를 1개씩 증가시키면서 나머지 배열을 채운다.
예시는 밑에와 같다.

2. 선택된 두 노드의 깊이를 맞춘다.
P배열을 이용해 기존에 한 단계씩 맞췄던 깊이를 2^K단위로 넘어가면서 맞춘다. 예를 노드 2와 노드 15의 깊이를 맞춰본다. 노드 2의 깊이는 2, 노드 15의 깊이는 6으로 두 노드의 깊이 차이는 4이다. 깊이를 맞추기 위해 더 깊이 있는 노드 15의 4번째 부모 노드를 P배열을 이용해 찾는다. 4=2^2이므로 K=2이고, P[2][15]=3이므로 노드 3으로 이동하면 노드 2와 높이를 맞추게 된다.
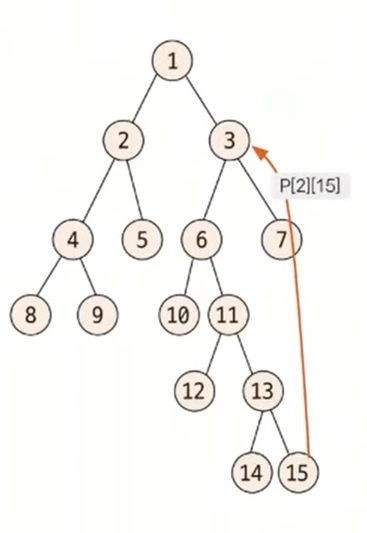
만약 높이 차이가 20이라고 가정하면 2^K<=20을 만족하면서 K가 최대가 되는 만큼 이동하면서 높이 차이가 0이 될 때까지 반복한다. 즉, 높이 차이가 20일 경우에는 16 -> 4와 같이 두 번 이동하면 된다.
3. 최소 공통 조상을 찾는다.
공통 조상을 찾는 작업 역시 한 단계씩이 아닌 2^K단위로 점프하면서 맞춘다. K값을 1씩 감소하면서 P배열을 이요해 최초로 두 노드의 부모가 달라지는 값을 찾는다.
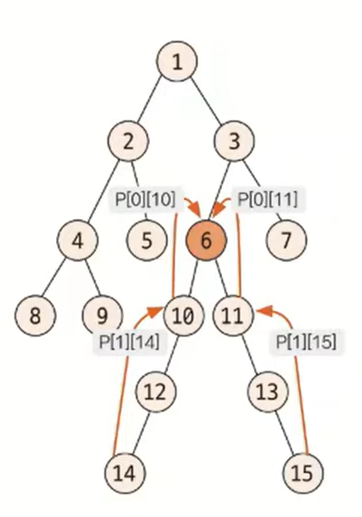

최초로 달라지는 K에 대한 두 노드의 부모 노드를 찾아 이동한다. 즉, 노드 10, 노드 11로 이동한다. 이를 K가 0이 될 때까지 반복한다. 반복문이 종료된 후 이동한 2개의 노드가 같은 노드라면 해당 노드가, 다른 노드라면 바로 위의 부모 노드가 최소 공통 조상이 된다.
여기에서는 노드 10, 11이 다른 노드이기 때문에 바로 위 노드를 뜻하는 P[0][10] 또는 P[0][11], 즉 노드 6이 최소 공통 조상이 된다.

6. 실전 문제
트리의 부모 찾기 (백준 11725) - 트리
import java.io.*;
import java.util.ArrayList;
import java.util.StringTokenizer;
public class P11725_트리부모찾기 {
static ArrayList<Integer>[] A;
static boolean[] visit;
static int[] parent;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st;
int N = Integer.parseInt(br.readLine());
A = new ArrayList[N + 1];
visit = new boolean[N + 1];
parent = new int[N + 1];
for (int i = 1; i <= N; i++) {
A[i] = new ArrayList<>();
parent[i] = i;
}
for (int i = 0; i < N - 1; i++) {
st = new StringTokenizer(br.readLine());
int u = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
A[u].add(v);
A[v].add(u);
}
DFS(1);
for (int i = 2; i <= N; i++) {
bw.write(parent[i] + " \n");
}
bw.close();
}
public static void DFS(int a) {
visit[a] = true;
for (int i : A[a]) {
if (!visit[i]) {
parent[i] = a;
DFS(i);
}
}
}
}
완전 이진 트리 (백준 9934) - 이진 트리
import java.io.*;
import java.util.ArrayList;
import java.util.StringTokenizer;
public class P9934_완전이진트리 {
static ArrayList<Integer>[] al;
static int[] value;
static int K;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st;
K = Integer.parseInt(br.readLine());
int size = (int) Math.pow(2, K) - 1;
al = new ArrayList[K + 1];
value = new int[size + 1];
for (int i = 1; i <= K; i++) al[i] = new ArrayList<>();
st = new StringTokenizer(br.readLine());
for (int i = 1; i < value.length; i++) value[i] = Integer.parseInt(st.nextToken());
search(1, 1, size);
for (int i = 1; i <= K; i++) {
for (int j = 0; j < al[i].size(); j++) {
bw.write(al[i].get(j) + " ");
}
bw.write("\n");
}
bw.close();
}
static void search(int depth, int start, int end) {
int mid = (start + end) / 2;
al[depth].add(value[mid]);
if (depth == K) return;
search(depth + 1, start, mid - 1);
search(depth + 1, mid + 1, end);
}
}
구간 합 구하기 (백준 2042) - 세그먼트 트리 = 인덱스 트리
import java.io.*;
import java.util.StringTokenizer;
public class P2042_구간합구하기 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
int K = Integer.parseInt(st.nextToken());
// 배열 사이즈 구하기
int k = 0;
int num = 1;
while (num < N) {
num *= 2;
k++;
}
int size = (int) Math.pow(2, k + 1);
long[] tree = new long[size];
// 리프 트리 데이터 받기
for (int i = 0; i < N; i++) {
Long a = Long.parseLong(br.readLine());
tree[(int) Math.pow(2, k) + i] = a;
}
// 전체 데이터 넣기
for (int i = tree.length - 1; i > 0; i--) {
int a = i / 2;
tree[a] += tree[i];
}
// a = 1. 2 인 경우 나누기
for (int i = 0; i < M + K; i++) {
st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
long c = Long.parseLong(st.nextToken());
long sum = 0;
if (a == 1) {
b += (int) Math.pow(2, k) - 1;
long gap = c - tree[b];
while (b > 0) {
tree[b] += gap;
b /= 2;
}
} else { // a가 2인 경우
b += (int) Math.pow(2, k) - 1;
c += (long) Math.pow(2, k) - 1;
int start = b;
long end = c;
while (start <= end) {
if (start % 2 == 1) sum += tree[start];
if (end % 2 == 0) sum += tree[(int) end];
start = (start + 1) / 2;
end = (end - 1) / 2;
}
bw.write(sum + "\n");
}
}
bw.close();
}
}
LCA (백준 11437) - 일반적인 최소 공통 조상
import java.io.*;
import java.util.ArrayList;
import java.util.StringTokenizer;
public class P11437_LCA {
static int[] parent;
static int[] depth;
static ArrayList<Integer>[] tree;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st;
// 노드의 개수 받기
int N = Integer.parseInt(br.readLine());
parent = new int[N + 1];
depth = new int[N + 1];
tree = new ArrayList[N + 1];
// 트리 배열 만들고 연결되어 있는 정점 받기
for (int i = 1; i <= N; i++) tree[i] = new ArrayList<>();
for (int i = 1; i < N; i++) {
st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
tree[a].add(b);
tree[b].add(a);
}
//DFS를 이용해서 depth, parent 데이터 설정
DFS(1, 1, 0);
int M = Integer.parseInt(br.readLine());
for (int i = 0; i < M; i++) {
st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
bw.write(LCA(a, b) + "\n");
}
bw.flush();
bw.close();
br.close();
}
static void DFS(int cur, int d, int p) {
depth[cur] = d;
parent[cur] = p;
for (int a : tree[cur]) {
if (a == p) continue;
DFS(a, d + 1, cur);
}
}
static int LCA(int a, int b) {
int ah = depth[a];
int bh = depth[b];
while (ah > bh) {
a = parent[a];
ah--;
}
while (bh > ah) {
b = parent[b];
bh--;
}
while (true) {
if (a == b)
return a;
a = parent[a];
b = parent[b];
}
}
}
LCA2 (백준 11438) - 빠른 최소 공통 조상
import java.io.*;
import java.util.ArrayList;
import java.util.StringTokenizer;
public class P11438_LCA2 {
static int N, M, K;
static ArrayList<Integer>[] tree;
static int[][] parent;
static int[] depth;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st;
N = Integer.parseInt(br.readLine());
// 2^K의 K찾기
K = -1;
for (int i = 1; i <= N; i *= 2) K++;
// LCA 관련 변수 초기화
parent = new int[K + 1][N + 1];
depth = new int[N + 1];
// tree 변수 초기화
tree = new ArrayList[N + 1];
for (int i = 1; i <= N; i++) tree[i] = new ArrayList<>();
for (int i = 1; i < N; i++) {
st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
tree[a].add(b);
tree[b].add(a);
}
// depth 확인
DFS(1, 1, 0);
// 2^K까지 parent 채우기
fillParent();
// LCA 진행
M = Integer.parseInt(br.readLine());
for (int i = 0; i < M; i++) {
st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
bw.write(LCA(a, b) + "\n");
}
bw.flush();
bw.close();
br.close();
}
static void DFS(int cur, int d, int p) {
depth[cur] = d;
parent[0][cur] = p;
for (int i : tree[cur]) {
if (i == p) continue;
DFS(i, d + 1, cur);
}
}
static void fillParent() {
for (int i = 1; i <= K; i++) {
for (int j = 1; j <= N; j++) {
parent[i][j] = parent[i - 1][parent[i - 1][j]];
}
}
}
static int LCA(int a, int b) {
if (depth[a] < depth[b]) {
int tmp = a;
a = b;
b = tmp;
}
// depth 맞추기
for (int i = K; i >= 0; i--) {
if (Math.pow(2, i) <= depth[a] - depth[b]) {
a = parent[i][a];
}
}
// depth를 맞췄는데 같다면 바로 종료
if (a == b) return a;
for (int i = K; i >= 0; i--) {
if (parent[i][a] != parent[i][b]) {
a = parent[i][a];
b = parent[i][b];
}
}
return parent[0][a];
}
}