1. 그래프 (Graph)
- 하나의 정점으로부터 시작하여 차례대로 모든 정점들을 한 번씩 방문하는 것
그래프 구현 - 인접 행렬 (Adjacency Materix)
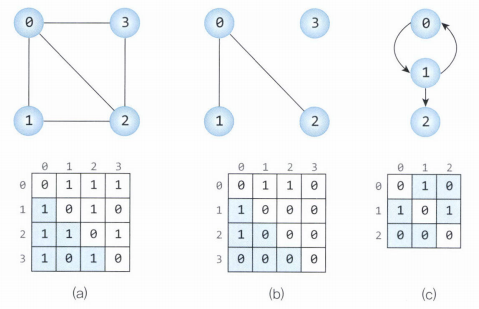
그래프의 정점을 2차원 배열로 만든 것이다.
정점의 개수가 n이라면 n*n 형태의 2차원 배열이 인접 행렬로 사용된다.
인접 행렬에서 행과 열은 정점을 의미하며, 각각의 원소들은 정점 간의 간선을 나타낸다.
무방향 그래프는 (a), (b)에서 볼 수 있듯이 인접 행렬이 대칭적 구조를 가진다.
(두 개의 정점에서 간선이 동시에 연결되어 있기 때문)
가중치 그래프의 경우 행렬에서 0과 1이 아니라 각 간선의 가중치 값이 저장된다.
(이 경우 가중치가 0인 것과 간선이 없는 것이 구별돼야 함)
그래프 구현 - 인접 리스트 (Adjacency List)
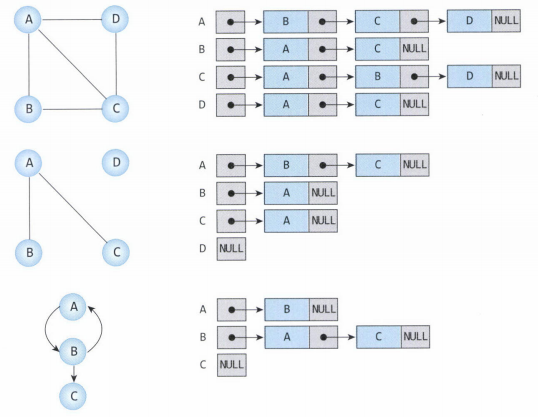
그래프의 각 정점에 인접한 정점들을 연결리스트(Linked List)로 표현하는 방법이다.
즉 정점의 개수만큼 인접리스트가 존재하며, 각각의 인접리스트에는 인접한 정점 정보가 저장되는 것이다.
그래프는 각 인접리스트에 대한 헤드포인터를 배열로 갖는다.
무방향 그래프의 경우 간선이 추가되면 각각의 정점의 인접리스트에 반대편 정점의 노드를 추가해야 한다.
인접 행렬 vs 인접 리스트
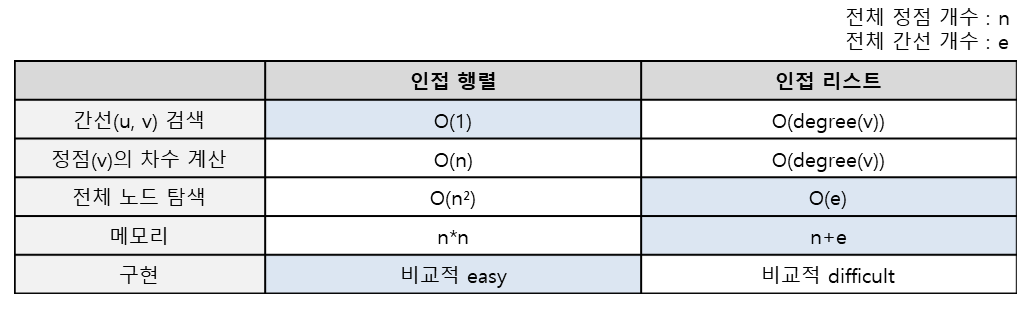
마치 어떻게 활용될지에 따라 ArrayList와 LinkedList를 고민하는 것처럼, 이 또한 상황에 따라 알맞은 방법을 선택해야 한다.
만약 10억 개의 노드가 있고 각 노드가 2개씩의 간선만 있는 상황이다. 인접행렬로 구현한 그래프에서는 한 정점의 차수를 구할 때 10억번의 연산을 수행할 것이다. 반면, 인접리스트로 구현한 그래프에서는 2번의 연산만 수행하면 된다.
정점의 개수에 비해 간선의 개수가 매우 적은 희소 그래프(sparse graph)에서는 인접리스트가 유리할 수 있고, 모든 정점간에 간선이 존재하는 완전 그래프(Complete Graph)에서는 인접행렬이 유리할 수 있다.
그래프에서 주로 어떤 연산이 수행되는지도 매우 중요하게 고려되어야 할 것이다.
답은 없다. 상황에 따라 최선의 방법을 선택하는 것이 프로그래머의 덕목이다.
2. DFS (깊이 우선 탐색)
루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법
-
미로를 탐색할 때 한 방향으로 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게 되면 다시 가장 가까운 갈림길로 돌아와서 이곳으로부터 다른 방향으로 다시 탐색을 진행하는 방법과 유사하다.
-
즉, 넓게 탐색하기 전에 깊게 탐색하는 것이다.
-
사용하는 경우 : 모든 노드를 방문하고자 하는 경우에 이 방법을 선택한다.
-
깊이 우선 탐색(DFS)이 너비 우선 탐색(BFS)보다 좀 더 간단하다.
-
단순 검색 속도 자체는 너비 우선 탐색(BFS)에 비해서 느리다.
DFS의 특징
- 자기 자신을 호출하는 순환 알고리즘의 형태를 가지고 있다.
- 이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야 한다는 것이다.
DFS의 과정
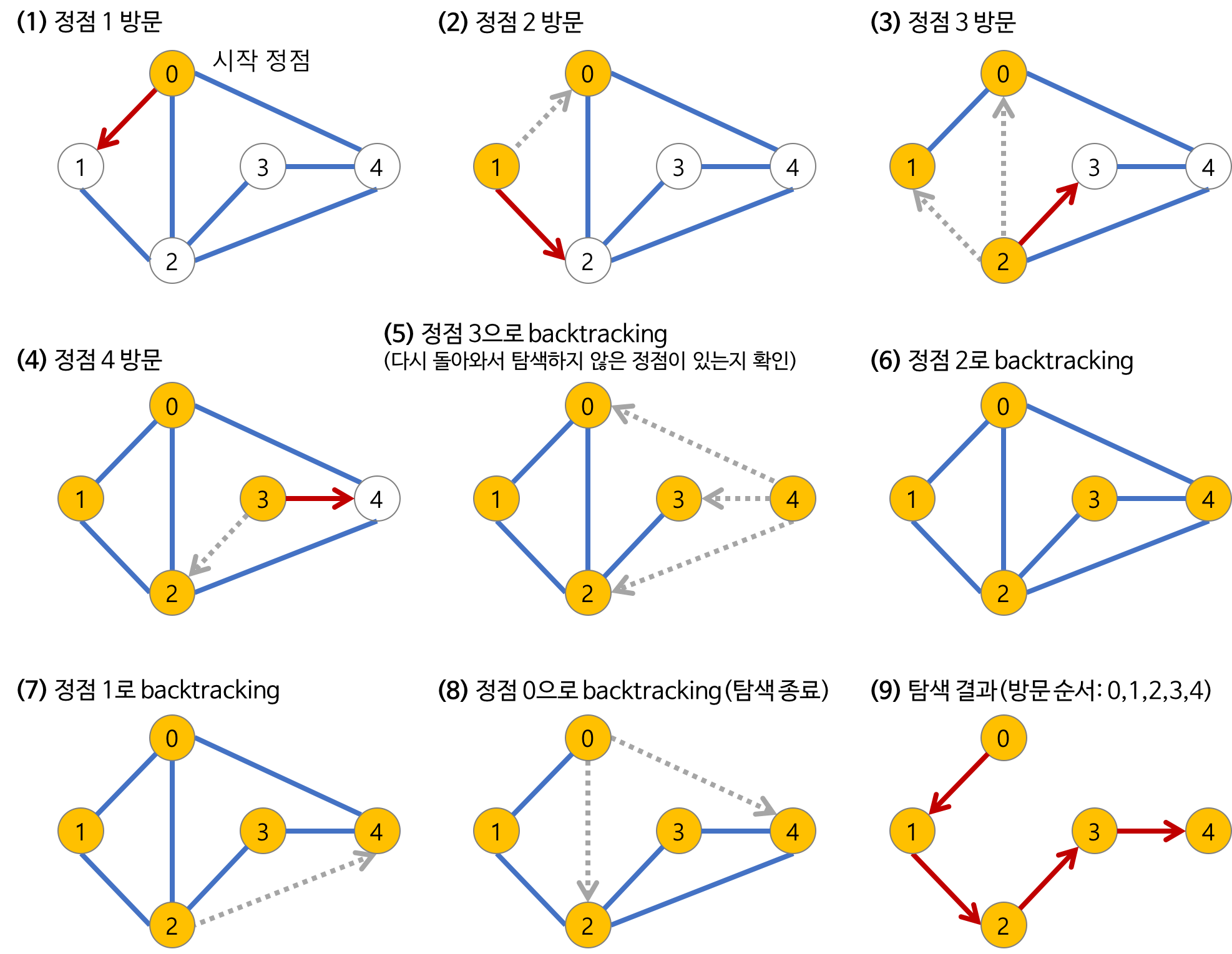
DFS의 시간 복잡도
- 인접 리스트로 표현된 그래프 : O(N+E)
- 인접 행렬로 표현된 그래프 : O(N^2)
즉, 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph) 의 경우 인접 행렬보다 인접 리스트를 사용하는 것이 유리하다.
3. BFS (깊이 우선 탐색)
루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법
- 시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법이다.
- 즉, 깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 것이다.
- 사용하는 경우: 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다.
- 너비 우선 탐색(BFS)이 깊이 우선 탐색(DFS)보다 좀 더 복잡하다.
BFS의 특징
- 직관적이지 않은 면이 있다.
- BFS는 재귀적으로 동작하지 않는다.
- 이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사 해야 한다는 것이다.
- BFS는 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐를 사용한다.
BFS의 과정
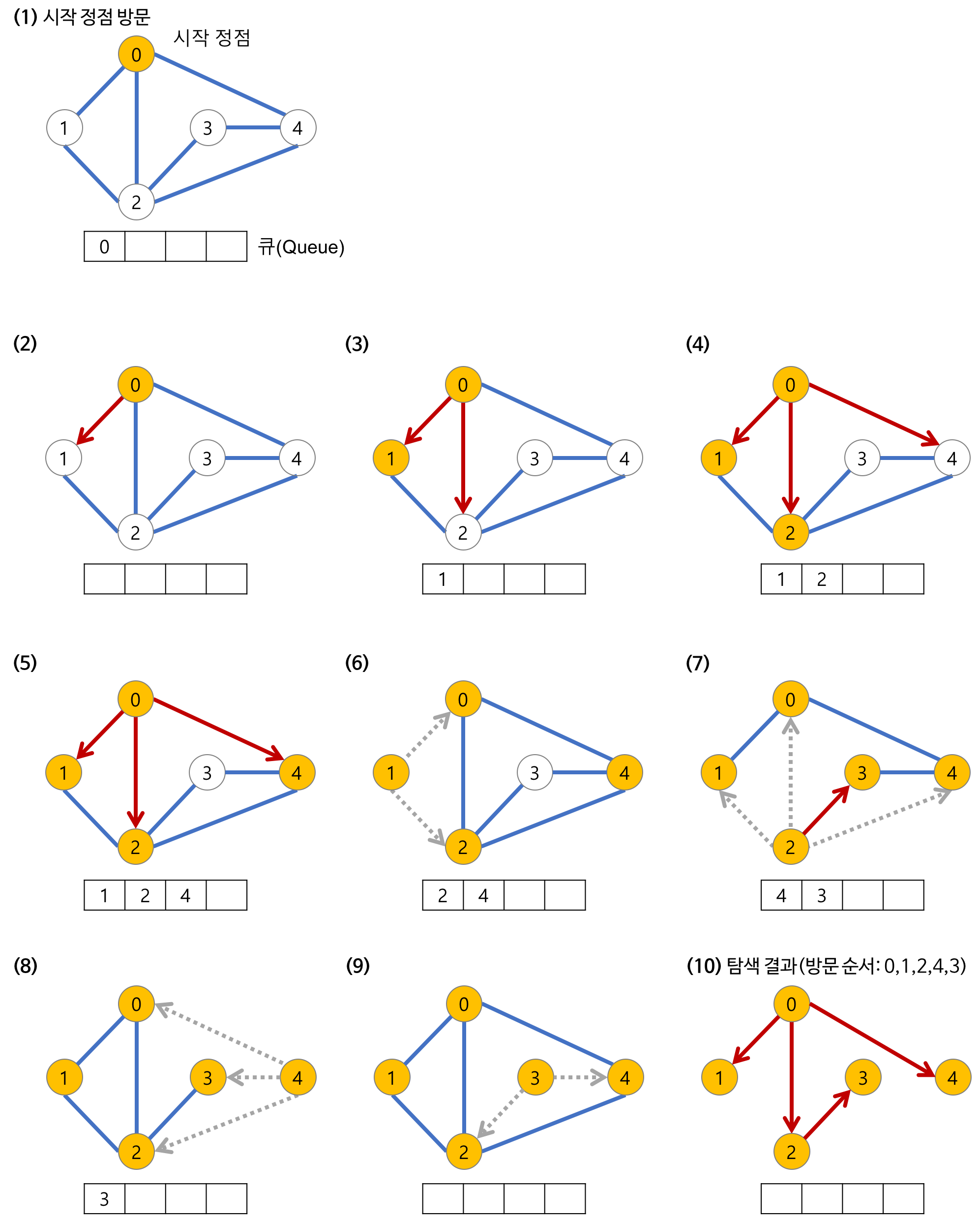
BFS의 시간 복잡도
- 인접 리스트로 표현된 그래프 : O(N+E)
- 인접 행렬로 표현된 그래프 : O(N^2)
DFS와 마찬가지로 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph) 의 경우 인접 행렬보다 인접 리스트를 사용하는 것이 유리하다.
4. Binary search (이진 탐색)
이진 탐색은 정렬된 리스트에서 검색 범위를 줄여 나가면서 검색 값을 찾는 알고리즘이다.
이진 탐색은 정렬된 리스트에서만 사용할 수 있다는 단점이 있지만, 검색이 반복될 때마다 검색 범위가 절반으로 줄기 때문에 속도가 빠르다는 장점이 있다.
이진 탐색의 시간 복잡도

5. DFS/BFS 실전 문제
연결 요소의 개수 (백준 11724) - DFS 풀이
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.StringTokenizer;
public class P11724_연결요소의개수 {
static boolean[] visited;
static ArrayList<Integer>[] al;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
visited = new boolean[N + 1];
al = new ArrayList[N + 1];
for (int i = 1; i <= N; i++) al[i] = new ArrayList<Integer>();
for (int i = 0; i < M; i++) {
st = new StringTokenizer(br.readLine());
int s = Integer.parseInt(st.nextToken());
int e = Integer.parseInt(st.nextToken());
al[s].add(e);
al[e].add(s);
}
int count = 0;
for (int i = 1; i <= N; i++) {
if (!visited[i]) {
count++;
DFS(i);
}
}
System.out.println(count);
}
public static void DFS(int i) {
if (visited[i]) return;
visited[i] = true;
for (int num : al[i]) {
if (!visited[num]) DFS(num);
}
}
}
미로 탐색 (백준 2178) - BFS 풀이
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.LinkedList;
import java.util.Queue;
import java.util.StringTokenizer;
public class P2178_미로탐색 {
static int[] dx = {0, 1, 0, -1};
static int[] dy = {1, 0, -1, 0};
static boolean[][] visited;
static int[][] A;
static int N, M;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken());
M = Integer.parseInt(st.nextToken());
A = new int[N][M];
visited = new boolean[N][M];
for (int i = 0; i < N; i++) {
st = new StringTokenizer(br.readLine());
String line = st.nextToken();
for (int j = 0; j < M; j++) A[i][j] = Integer.parseInt(line.substring(j, j + 1));
}
BFS(0, 0);
System.out.println(A[N - 1][M - 1]);
}
public static void BFS(int i, int j) {
Queue<int[]> queue = new LinkedList<>();
queue.offer(new int[]{i, j});
while (!queue.isEmpty()) {
int now[] = queue.poll();
visited[i][j] = true;
for (int k = 0; k < 4; k++) {
int x = now[0] + dx[k];
int y = now[1] + dy[k];
if (x >= 0 && y >= 0 && x < N && y < M) {
if (A[x][y] != 0 && !visited[x][y]) {
visited[x][y] = true;
A[x][y] = A[now[0]][now[1]] + 1;
queue.add(new int[]{x, y});
}
}
}
}
}
}
수 찾기 (백준 1920) - 병합 정렬 / 이진 탐색 풀이
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.StringTokenizer;
public class P1920_수찾기 {
static ArrayList<Integer> data;
static ArrayList<Integer> search;
static ArrayList<Integer> sorted = new ArrayList<>();
static int N, M;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken());
data = new ArrayList<>();
st = new StringTokenizer(br.readLine());
for (int i = 0; i < N; i++) data.add(Integer.parseInt(st.nextToken()));
mergeSort(data, 0, N - 1);
st = new StringTokenizer(br.readLine());
M = Integer.parseInt(st.nextToken());
search = new ArrayList<>();
st = new StringTokenizer(br.readLine());
for (int i = 0; i < M; i++) search.add(Integer.parseInt(st.nextToken()));
for (int i = 0; i < M; i++) BSearch(data, search.get(i));
}
public static void BSearch(ArrayList<Integer> arr, int target) {
int low = 0;
int high = arr.size() - 1;
int mid;
while (low <= high) {
mid = (low + high) / 2;
if (arr.get(mid) == target) {
System.out.println("1");
return;
} else if (arr.get(mid) > target)
high = mid - 1;
else
low = mid + 1;
}
System.out.println("0");
return;
}
public static void merge(ArrayList<Integer> arr, int m, int middle, int n) {
int i = m;
int j = middle + 1;
int k = 0;
while (i <= middle && j <= n) {
if (arr.get(i) <= arr.get(j)) {
sorted.add(arr.get(i));
i++;
} else {
sorted.add(arr.get(j));
j++;
}
}
if (i > middle) {
for (int t = j; t <= n; t++) sorted.add(arr.get(t));
} else {
for (int t = i; t <= middle; t++) sorted.add(arr.get(t));
}
for (int t = m; t <= n; t++) {
arr.set(t, sorted.get(k));
k++;
}
sorted.clear();
}
public static void mergeSort(ArrayList<Integer> arr, int m, int n) {
if (m < n) {
int middle = (m + n) / 2;
mergeSort(arr, m, middle);
mergeSort(arr, middle + 1, n);
merge(arr, m, middle, n);
}
}
}