정렬할 배열을 힙으로 만들기
일단 정렬을 하려면 힙을 만들어야 한다.

정렬할 1차원 데이터 10개가 있다.
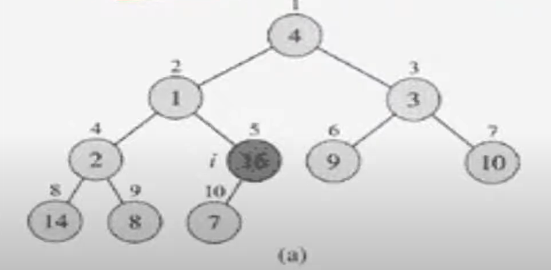
complete binary tree 로 변경한다.
이런식으로 정렬한다.
1차원배열을 complete binary tree로 생각한다.
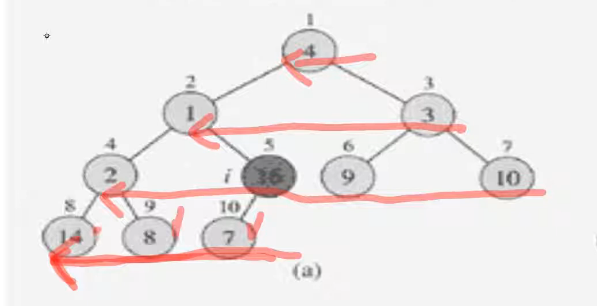
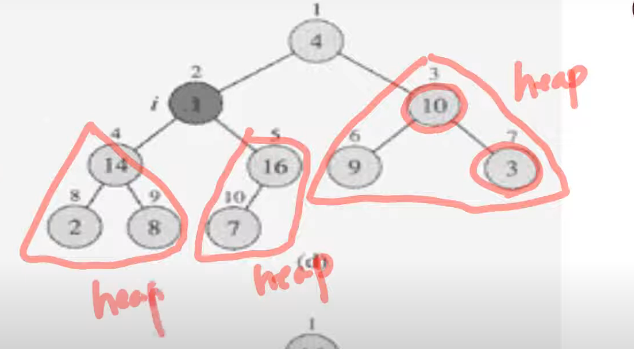
처음으로 leaf노드가 아닌 것 부터 시작한다. 16이 저장된 노드
levelnode들의 역순으로 노드들을 고려했을 때 leafnode가 아닌 첫번째 node이다.
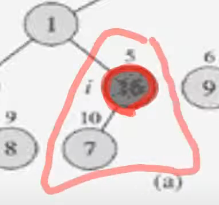
자식이 하나인 7이 저장된 노드는 단독으로 본다면 heap으로 볼 수 있다. 16은 오른쪽 자식이 없으니, 서브트리에 대해서 heapify연산을 할 조건이 충족 된다.
16이 저장되어있는 노드로 heapify연산을 한다. ===> 변동사항없음.
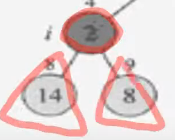
14는 2보다 크다. ===> 위 아래가 바뀐다
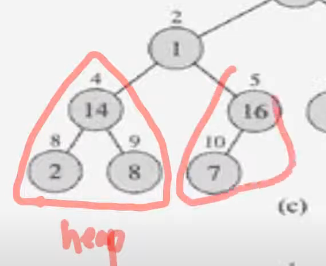
둘다 heap이 충족된다.
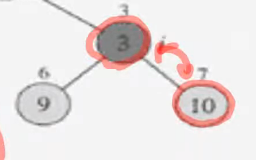
3은 10보다 작으니 ===> 위 아래가 바뀐다.
3개가 heap 의 요소가 충족
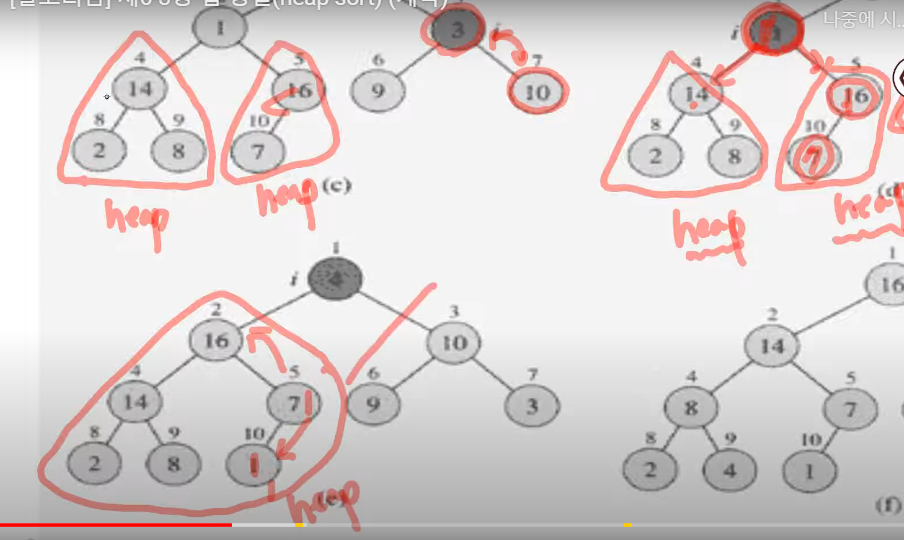
16과 1이 바뀌고 1과 7이 바뀐다. ===> heap 충족

실제 프로그램 안에서는 배열안에서 정렬되어 있다.!

length[A] 정렬할 데이터의 개수
heap-size[A] 힙의 저장된 노드의 개수는 정렬할 노드의 개수와 같으니 length[A]와 같다.
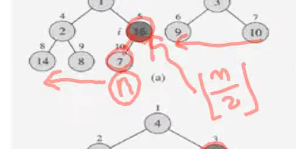
맨마지만 노드의 인덱스가 n 의 부모노드 n/2
for i <- length[A]/2 downto I
do MAX-Heapify(A,i)
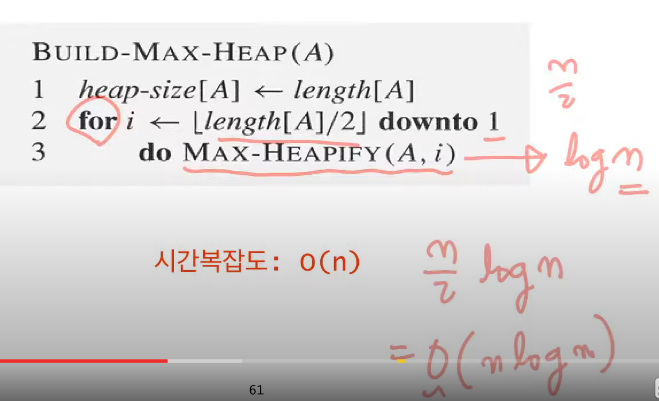
n은 node의 갯수
실질적으로 러프한 계산이다.
heapify node갯수가 n개라는것에 대한 계산이다.
heapsort
- 주어진 데이터로 힙을 만든다.
- 힙에서 최대값 (루트)을 가장 마지막 값과 바꾼다.
- 힙의 크기가 1 줄어든 것으로 간주하다. 즉, 가장 마지막 값은 힙의 일부가 아닌 것으로 간주한다.
- 루트노트에 대해서 heapify(1) 한다.
- 2~4번을 반복한다.
maxheap은 부모는 자식보다 크다. 라는 것을 만족해야 한다.
전체에서 최댓값은 root에 있어야한다.
1. 힙을 만들고
2. 힙을 만드는 시간 복잡도가 힙정렬 시간 복잡도는
n log n이다.
HEAPSORT(a)
1. BUID-MAX-HEAP(A) : O(n)
2. for i <- heap_size downto 2 do :n-1 times
3. exchange A[1] <-> A[i] :O(1)
4. heap_size <- heap_Size -1 :O(1)
5. Max-HeapFiy(A,1) :O(log2n)
Total time : O(nlog2n)
