
배민 마이크로서비스 여행기 정리

- 김영한 배민서비스개발팀
- 검색할 내용은 택스트로 입력함
배민 서비스 5년간의 역사
2015년

- 스토어드 프로시저 방식 사용
- 테이블 700개, 스토어드 프로시저 4000개, 거대한 모놀리틱 시스템

- 사례: 리뷰테이블에 어떤 문제가 생겨서 DB 전체의 문제가 발생
- 리뷰가 장애가 나도 다른 서비스(주문)에 문제가 없어야 한다.
2016년

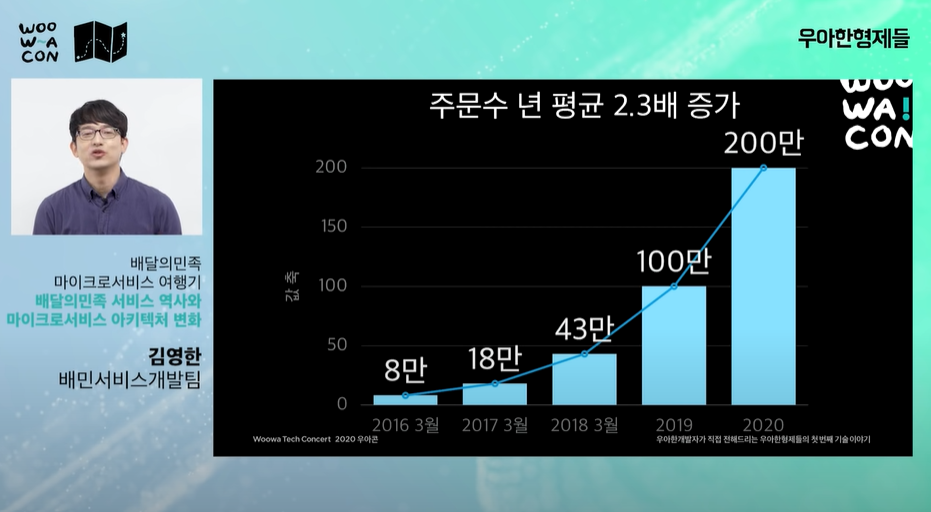
- 주문수(트래픽) 증가에 따른 기술적 도전에 직면.
- 도전 1: 언어를 자바로 변경
- 이유1. 자바가 대용량 트래픽에 대응 가능
- 이유2. 국내에 자바 개발자가 많아서
- 도전 2: 마이크로서비스
아마존의 마이크로서비스 변경 이유로 '선택이 아닌 생존의 문제'라고 하며 7년간 변경 - IDC에서 AWS 클라우드 인프라로 이전 시작
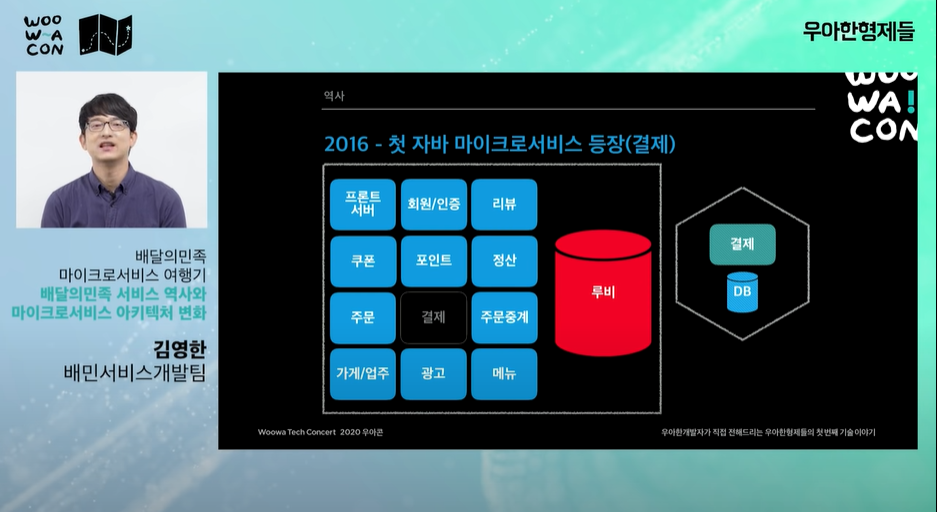
- 결제 서비스 분리
결제가 장애가 나도 '전화주문'으로 서비스 대응이 가능 - 마리아 DB를 사용, 결제서비스는 클라우드에 올릴 수 없다는 규제로 idc 사용
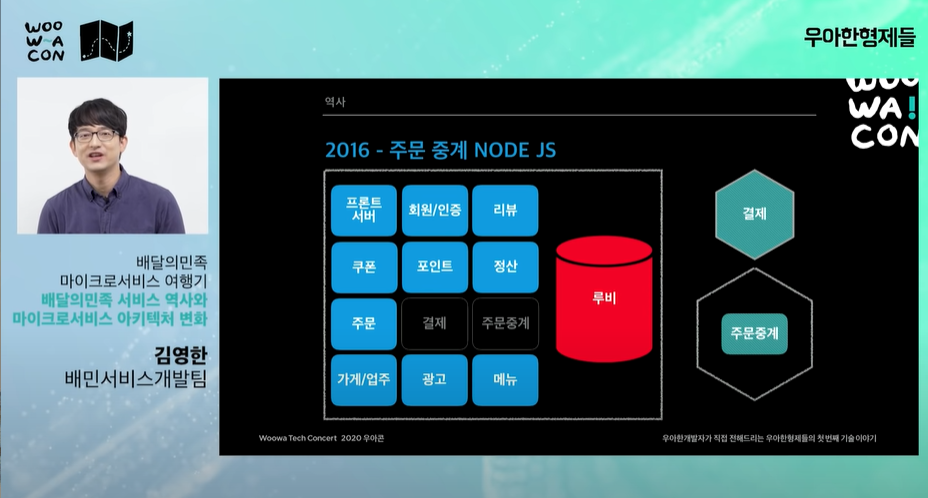
-
'주문 중계'란 사장이 app, pc 단말기등 다양한 루트로 주문을 접수받을 수 있다.
-
node.js로 중간에서 코딩해주는 게이트웨이 서비스 비즈니스에 맞는 기술을 사용.(지금은 java로 바꾼 상황)
-
치킨 디도스 사태

-
day1: 너무 많은 트래픽 유입으로 프론트서버가 죽어버리며 실패(주문으로 넘어가지도 않음)
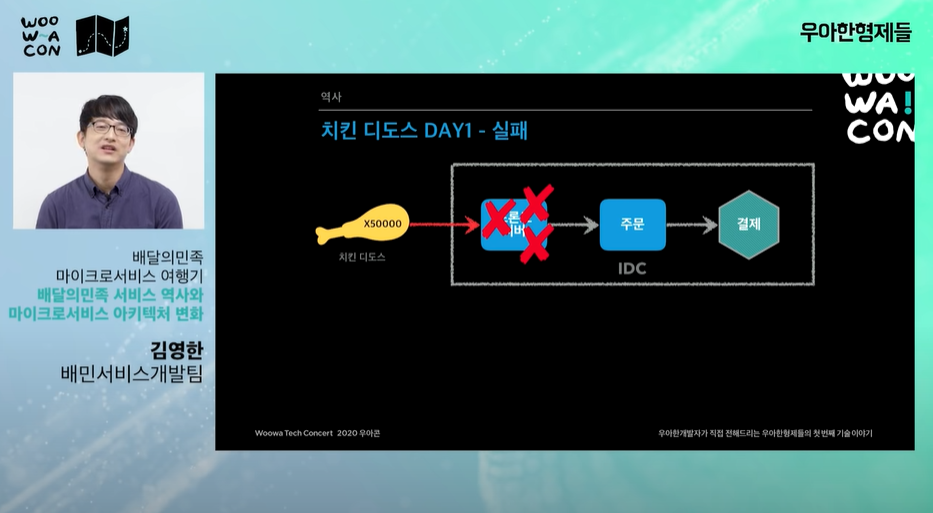
-
day2: AWS로 서버 이전 계획을 급하게 진행(한달치 계획을 하루만에 실행)
장비 100대 이상 증설해 트래픽 대비(어뷰징이 된다?)
문제는 주문 서버가 죽어버렸다.
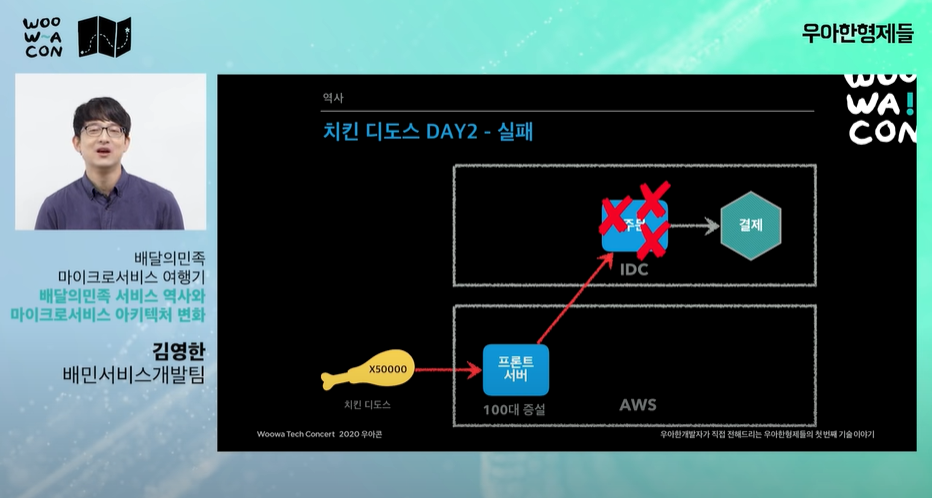
-
주문서버도 하루만에 AWS 이전, 장비 증설
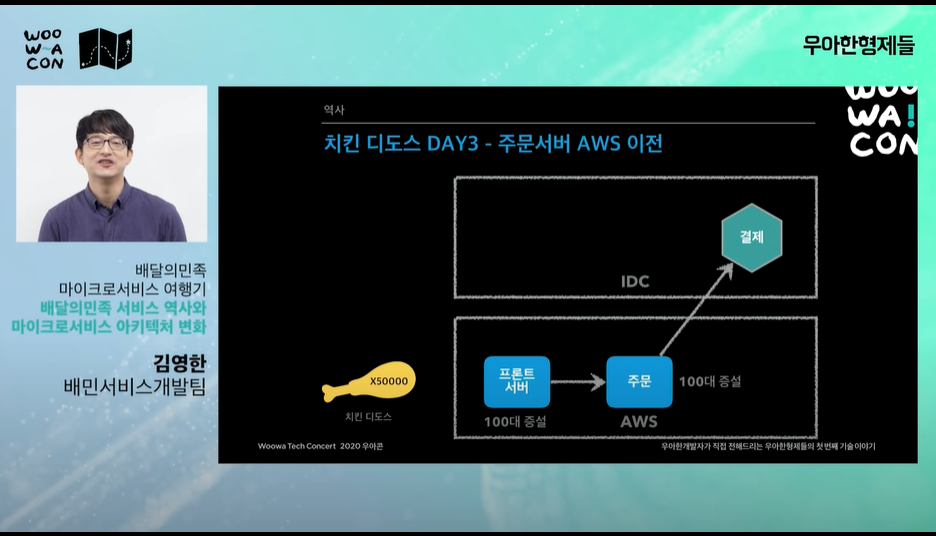
-
day3: 결제를 해주는 외부 pg사, 카드사에서 서비스가 죽어버린다.
외부화사 문제라 그쪽에서 장비 수급해서 해결함
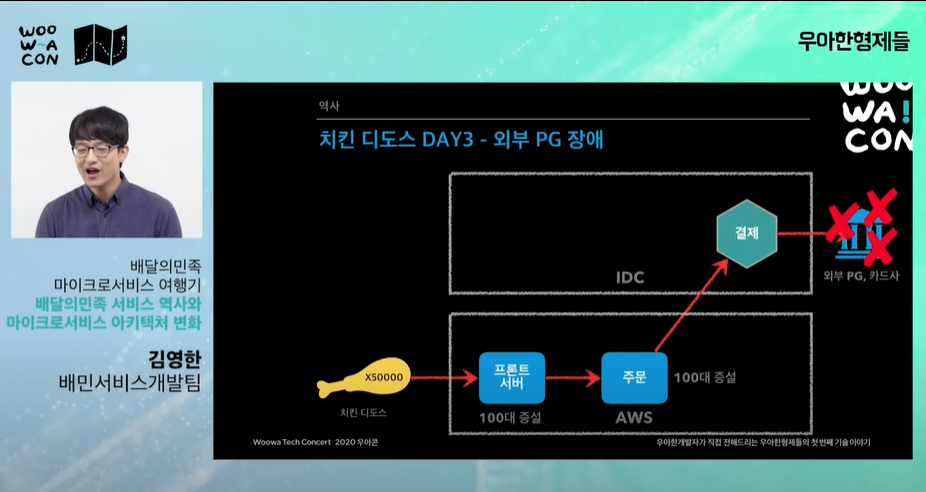
-
day4: 성공
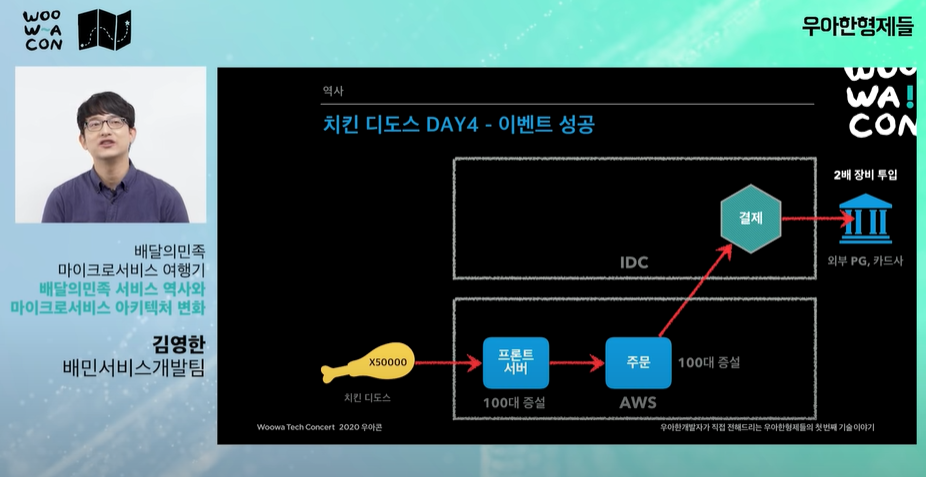
2017년

- 트래픽은 늘어나는데 레거시 시스템을 스케일할 구조가 안된다.
- 주말 오후만 되면 긴장해서 외식도 못함
- 이 당시 트라우마로 노트북을 들고 다니는 습관이 생김
- 장애가 나면 전국민의 역적이 된다. 사장님들 매출에 영향-> 다른 배달 서비스 트래픽이 증가하며 서버가 죽어버림-> 고객센터 전화 폭주-> 주문고객 분노 폭주
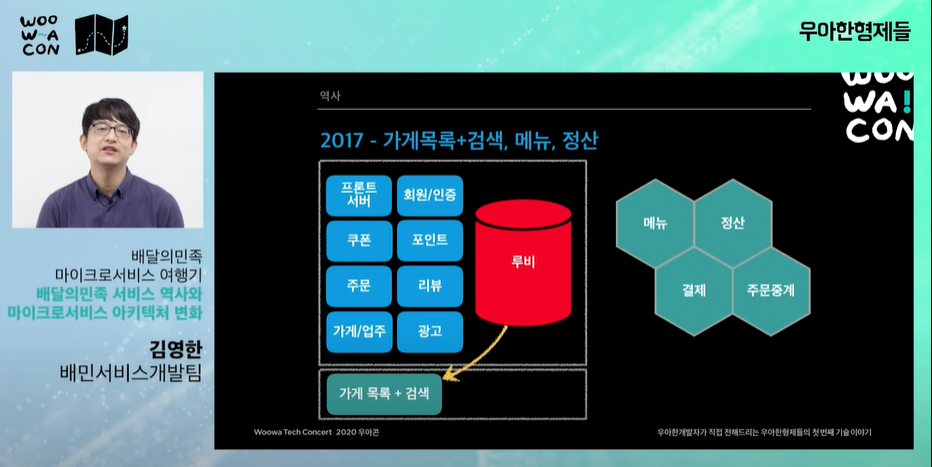
- 가계목록, 검색 db를 루비 db에서 분리하여 부하를 줄임
2018년

- 회사입장에선 돈 버는 과제 중시, 개발자 입장에선 안정성을 높이는 과제 중시
이를 전사적으로 공감대를 형성해 안정성을 1순위로 한다.
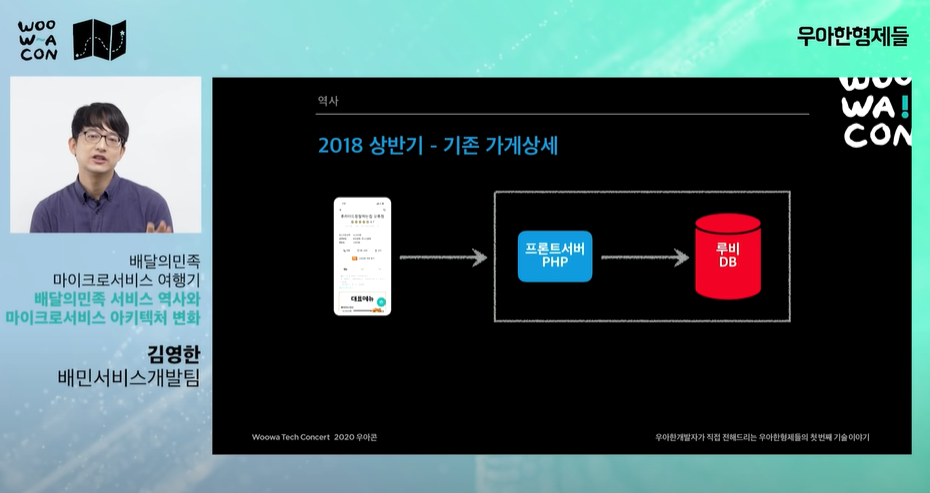
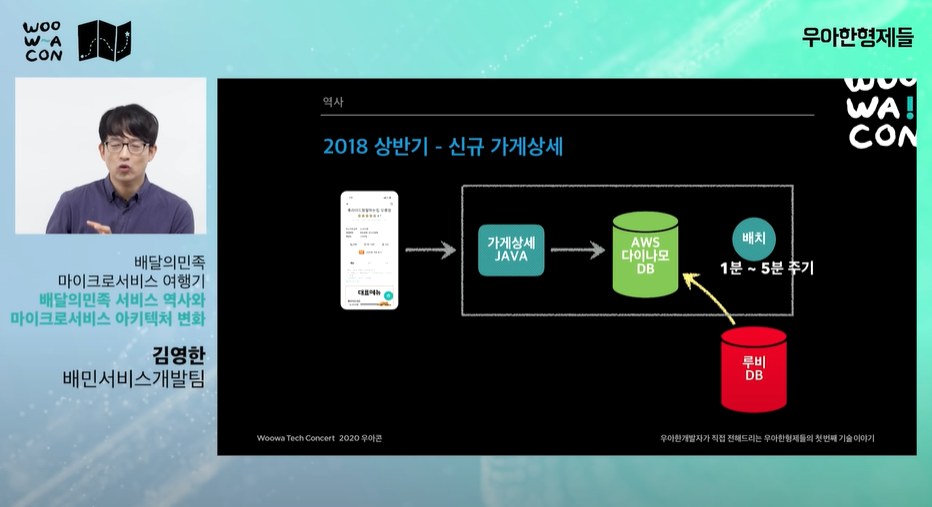
- 루비DB의 정보를 AWS 다이나모 DB(no SQL같은)로 1~5분 주기로 데이터(쿼리)를 올린다. 루비DB에 부하가 줄어든다.
- 루비DB는 일반차라고 하면 AWS 다이나모 DB는 스포츠카. 트래픽을 잘 견디나 사용기능이 적다.
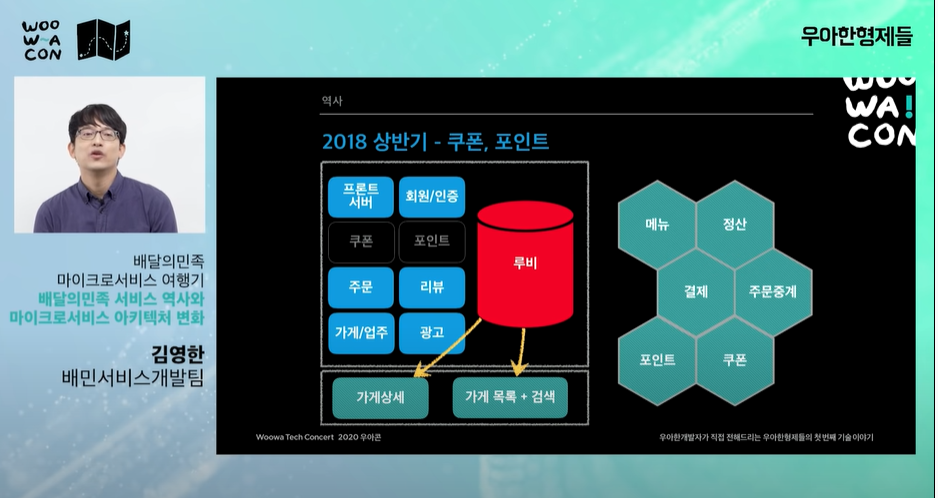
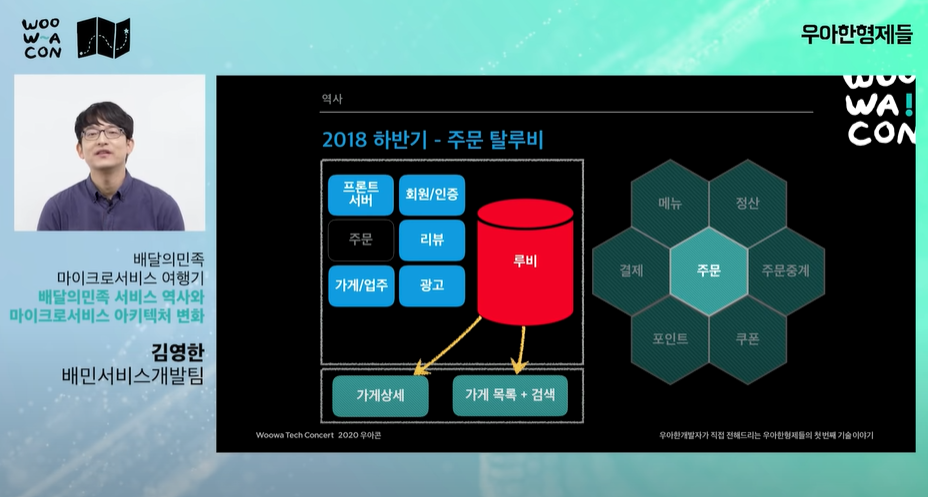
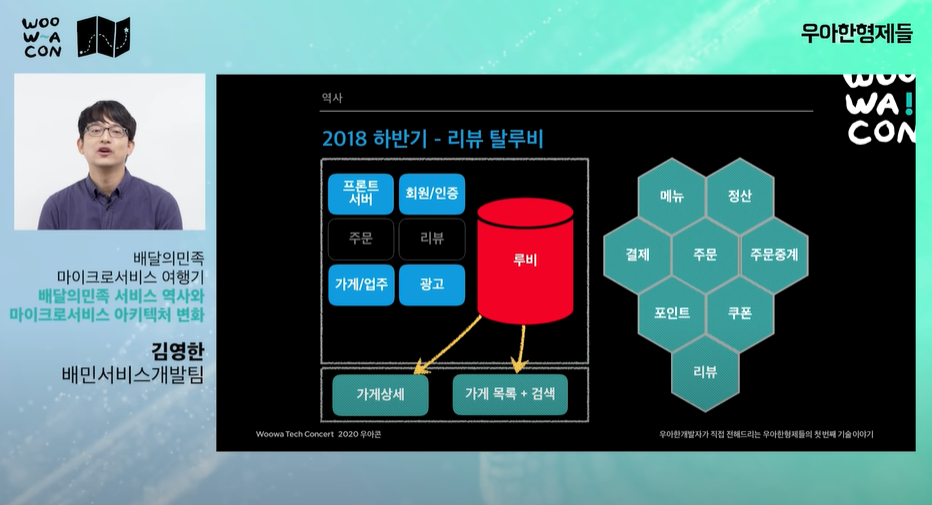
- 주문이 가운데 있다. 커머스 도메인에서 주문이 모든 시스템에 엮이기 때문에 제일 복잡하다.

- 스토어드 프로시저 유지보수 어려웠다. 체인지 프로시저 1,2,3 으로 많이 사용?
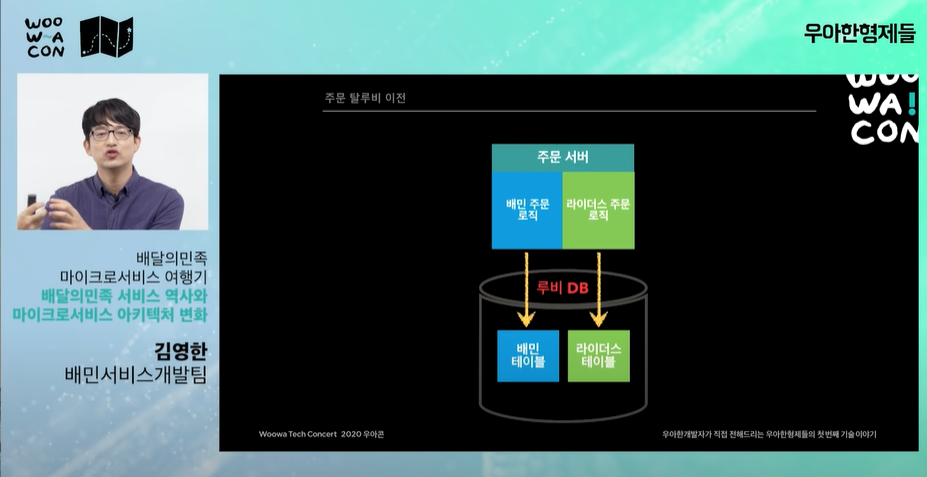
- 콘에이의 법칙: 시스템의 구조가 조직의 구조를 따라간다.
- 기존 주문과 비슷한 배민 라이더스 기능을 개발. 둘이 매우 비슷한 기능이나 같지는 않기 때문에 주문시스템을 통합하기가 어려웠다.
- 새로운 주문시스템을 설계해서 새로운 테이블을 만들었다.(도메인을 하나로 정리)
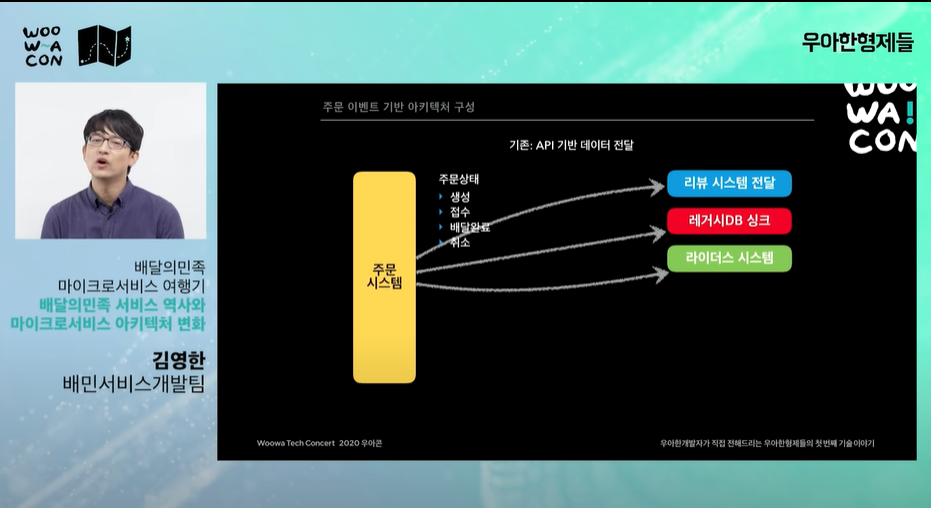
- 주문 시스템 과정에 수많은 라이프사이클, 외부api와 연결 발생
- ex) 주문완료 시 정보가 사장접속화면 -> 배민라이더스 -> 과거데이터와 싱크 -> 리뷰해주세요 앱푸시 안내문도 주문완료정보를 확인해야 할 수 있다. 이를 전부 api로 연동되어있다.
- 리뷰 시스템 장애 시 주문 시스템에도 장애가 생긴다. api가 끊기면 timeout이나 500 error 가 발생 가능
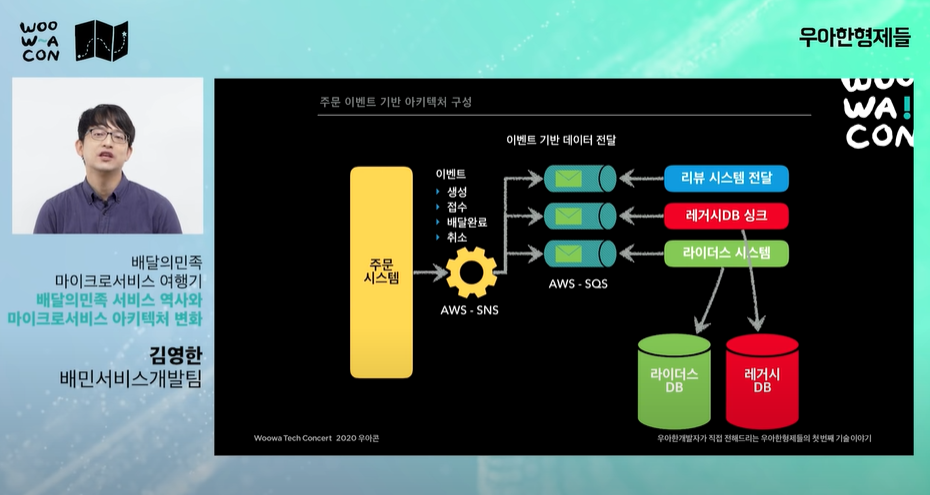
-
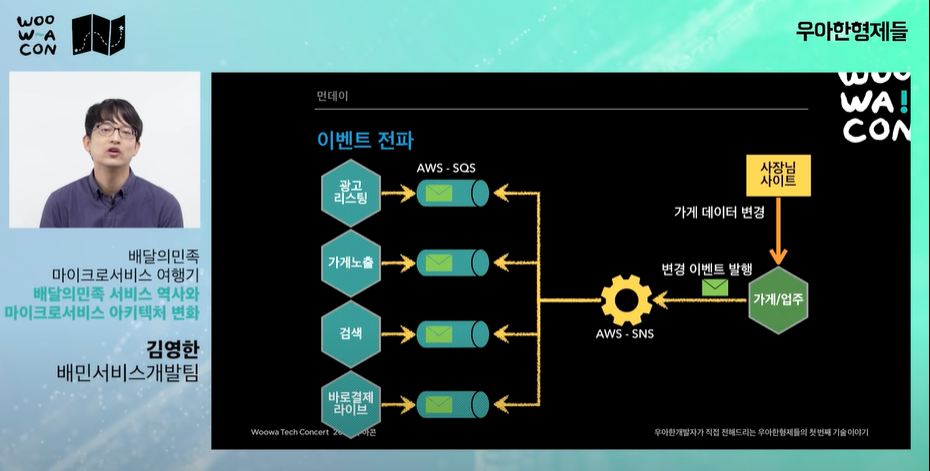
"이벤트 기반 데이터 전달" 이벤트 기반 시스템
-
주문을 명확한 이벤트 기반으로 주문의 라이프사이클을 정의한다. 이벤트 기반의 마이크로 서비스 아키텍처를 구성
-
"주문 시스템은 이벤트만 발행할 것이다. 다른 시스템에서 원하면 이벤트를 가져가서 succession(연속, 잇따름)해서 원하는 비즈니스 로직을 작성해" -> 주문시스템과 api를 완전히 분리.
-
주문시스템을 sns에 쏘면 이벤트 안에 데이터가 있다.("이벤트가 생성됬습니다. 접수됐습니다. 등") 이 데이터를 다른 api에서 이벤트를 받아서 처리한다.
-
리뷰시스템이 죽어도 주문 시스템에는 아무 문제가 없다. sns하나만 쏘고 끝난다.
리뷰시스템이 살아나면 이벤트가 날라가지 않고 aws, sqs에 쌓여있는 이벤트를 다시 보낼 수 있다. -
새로운 시스템에 주문 라이프 사이클이 필요한 경우 많은 이득을 보았다.
주문 시스템은 할 게 없다. 그냥 그 시스템에 필요한 sqs를 만들고 주문 sns에 연결하고 시스템에 꽂으면 된다. -
이때부터 에러가 크게 줄었다.
-
남은 레거시는 가계/업주, 광고 시스템
-
가계/업주랑 광고는 1대1 관계, 하나의 가계에 하나(한 장소)의 광고만 가능
가계 테이블 안에 광고 데이터가 들어가있다. 컬럼이 거의 100개가 되어 떼어내기 어려웠다. 전체 시스템에 영향을 주기 때문에 비즈니스를 올스탑해야 할 수 있다. -
완전한 마이크로 서비스를 위해 회사 임원들이 "프로젝트 먼데이"를 진행. 3,4개월 동안 시스템 기반을 안정화하고 개발팀이 이 프로젝트에만 집중하도록 지원한다.
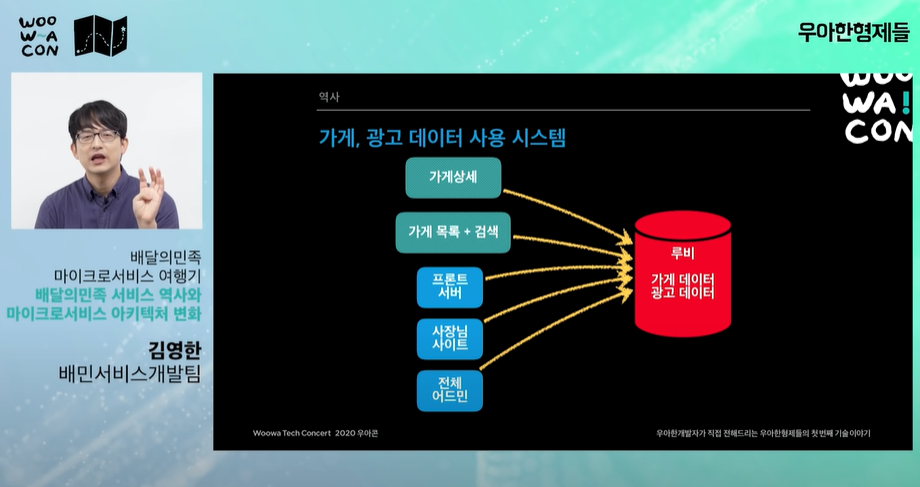
- 모든 시스템을 다 건드려야 했다. 이를 개선하기 위해
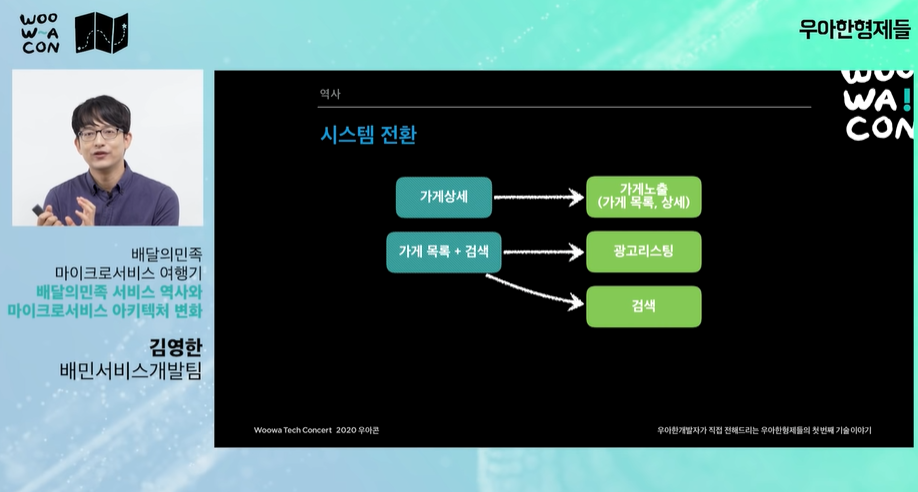
-
가계노출 시스템, "CQRS 모델링", "쿼리모델" 서비스 조회용 가계데이터를 가지고 있는 쿼리모델을 만들었다.
-
기존의 아키택처 상황과 문제
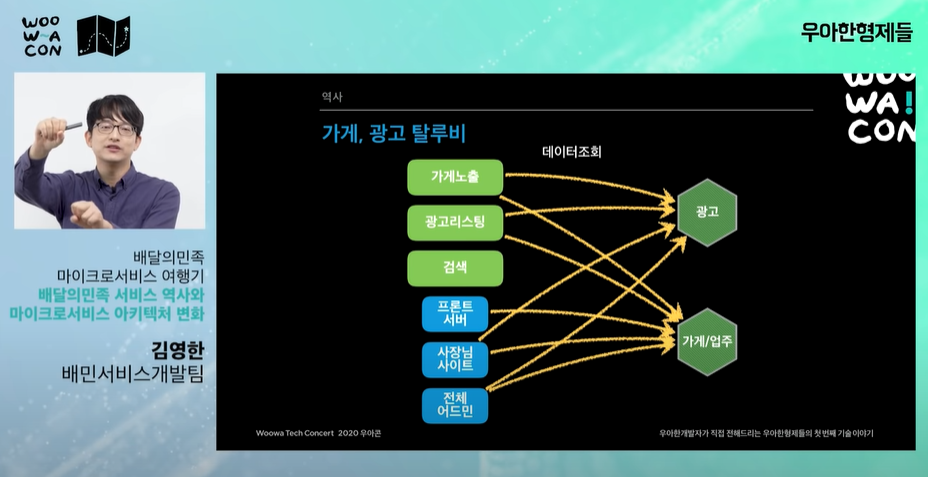
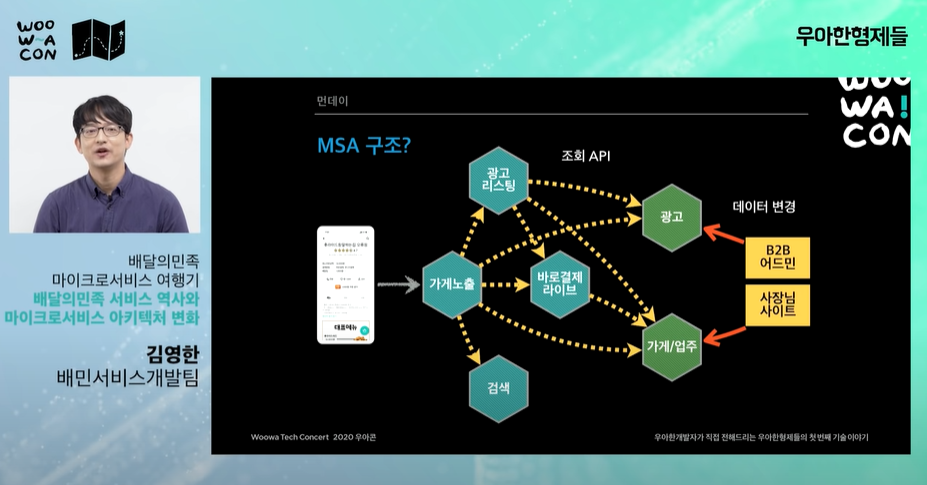
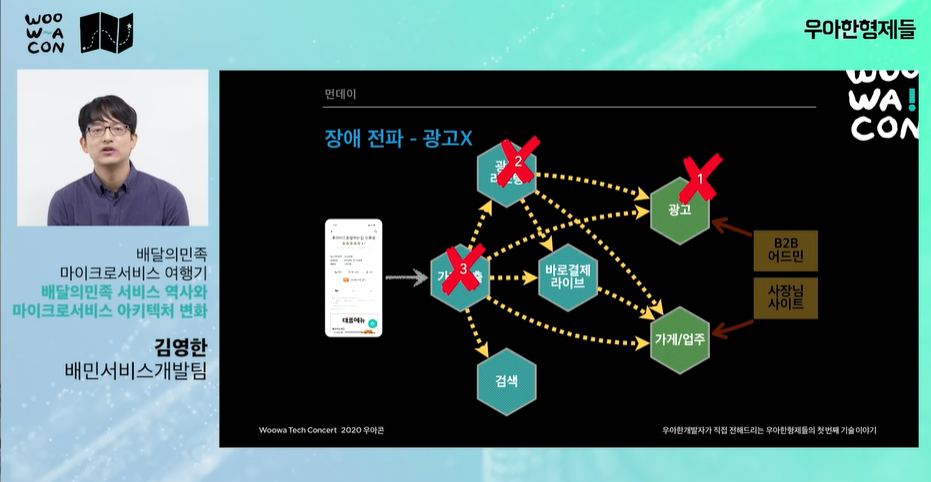
- 광고 시스템에 문제가 생기면 연쇄적으로 다른 시스템도 문제가 생김
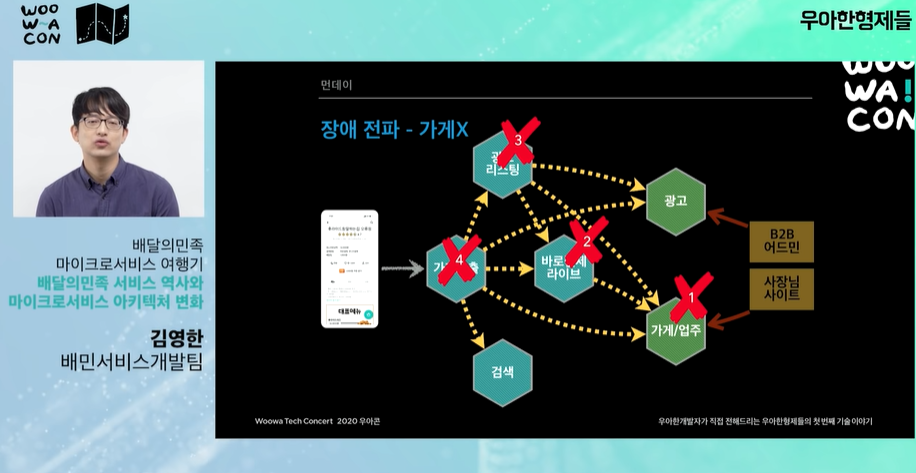
- 가계시스템도 같은 문제
-
이벤트 시 대량의 트래픽이 갑자기 몰려온다. 이 트래픽이 모든 api에 퍼진다.
광고나 가계/업주 시스템은 트래픽 해결보다 정확하고 안정적인 운영이 중요하다. -
먼데이 아키텍처 고려사항
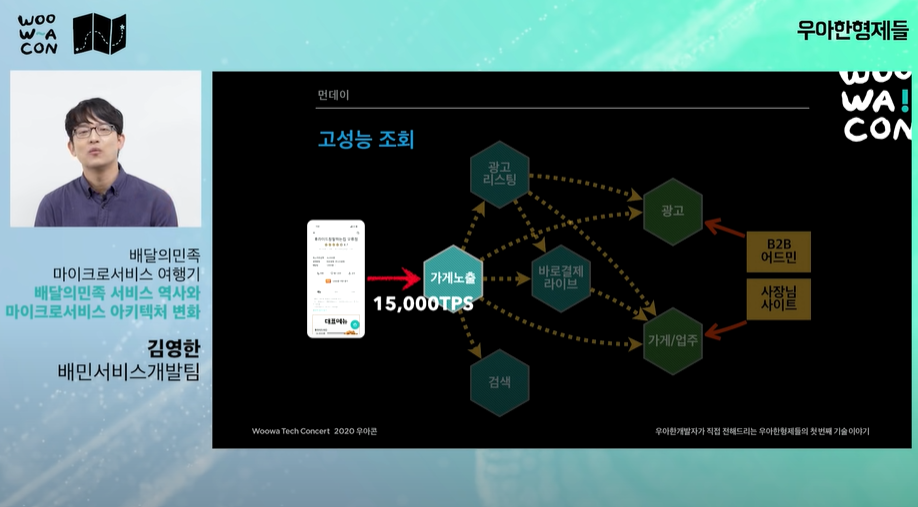
- 성능: 대용량 트래픽 대응 / 메인, 가계리스트, 상세 api는 초당 15000회 호출 / 모든 시스템이 대용량 트래픽을 감당하기는 어렵다.
- 장애 격리: 가계,광고 같은 내부 서비스나 DB에 장애가 발생해도 고객 서비스를 유지하고 주문도 가능해야했다.
- 데이터 동기화: 데이터가 분산되어 있음
-
해결 방안

-
Command and Query Responsibility Segregation(CQRS)
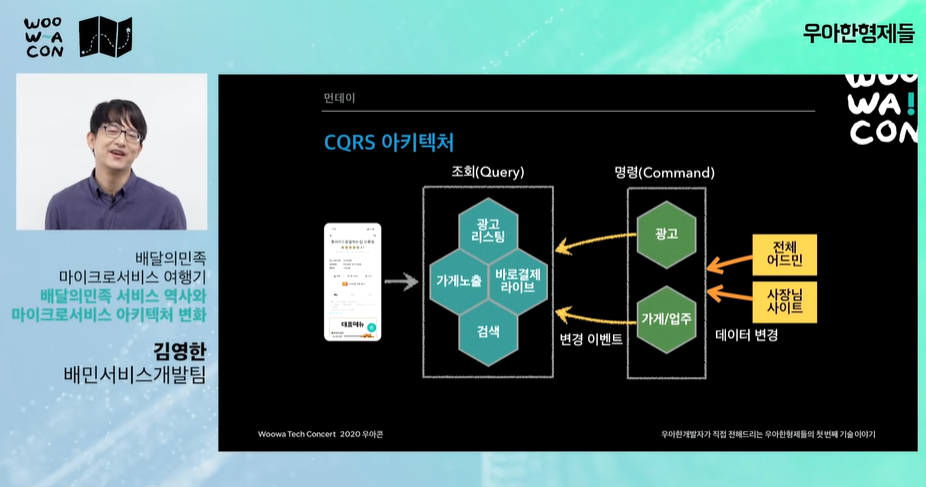
-

-
Eventually Consistency(최종적 일관성)
-
Zero-Payload 방식 사용
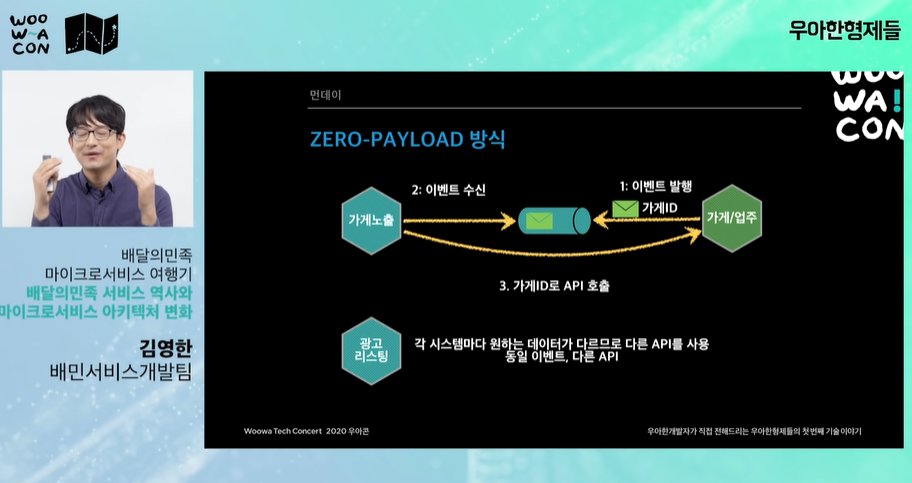
-
가계아이디만 보내면(실제로는 몇개 더 보낸다.) id를 수신하는 곳에서 데이터가 변경됨을 확인하고 두 시스템에서 협의한 api를 호출한다. api에 있는 데이터로 데이터를 채워넣는다.
-
변경된데이터만 보내는 경우 이벤트 순서를 고려해야 한다. 가계의 연락처를 a->b로 변경하는 경우 이벤트는 b-a로 올 수도 있다. 해결에 많은 고민이 드니 그냥 이벤트를 항상 최신순으로 보고 최신의 데이터를 조회하고 갱신하자고 결정.
-
전체데이터만 보내는 경우 테이블만 수십개라 현실적이지 못함
-
가계 최소정보(가계id)만 보내고 나머지는 api를 만들어서 각 시스템들이 최신에 받은 이벤트면 항상 그 api를 호출해서 각 시스템의 앞단을 갱신한다.

- 각 시스템은 모든 데이터를 보관해선 안되고 본인에게 꼭 필요한 데이터만 보관한다. 물리적 의존관계는 없지만 데이터를 가지고 있으면 논리적인 의존관계가 생긴다. 그래서 최소한의 데이터만 가지고 있자고 결정
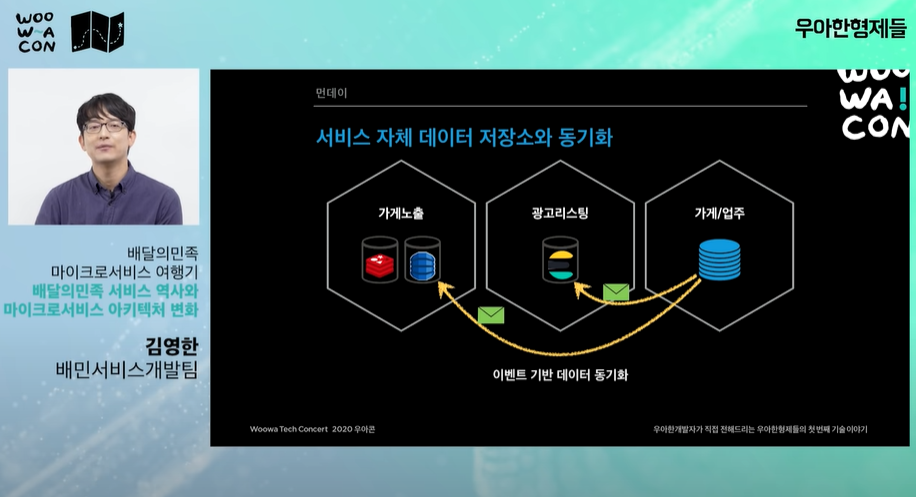
- 폴리글랏 데이터베이스 각 시스템들은 본인이 최대한 최적화할 수 있는 데이터베이스를 사용할 수 있다.
- 가계/업주는 "관계형 DB", 성능이 중요한 곳은 "레디스DB"나 "다이나모DB"를 쓴다. 검색이나 광고리스팅에서는 "일렉트릭서치"

- 광고, 가계/업주: "오로라DB" aws에서 제공하는 mysql 호환 db
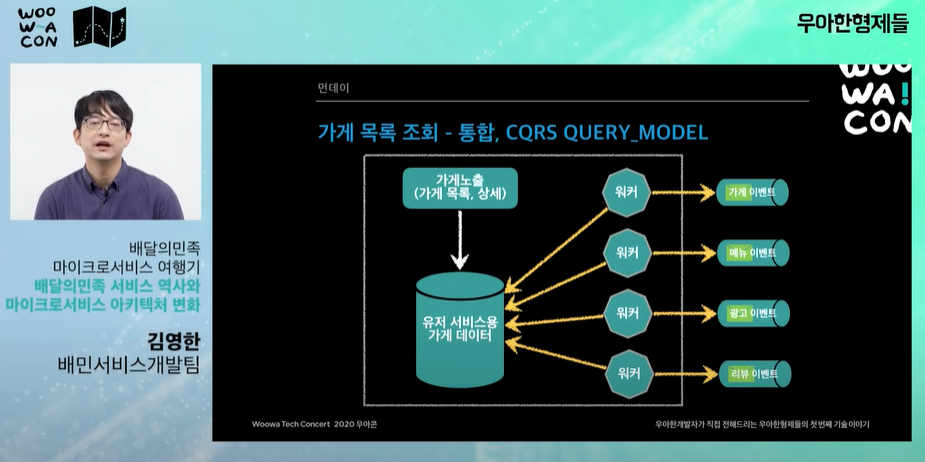
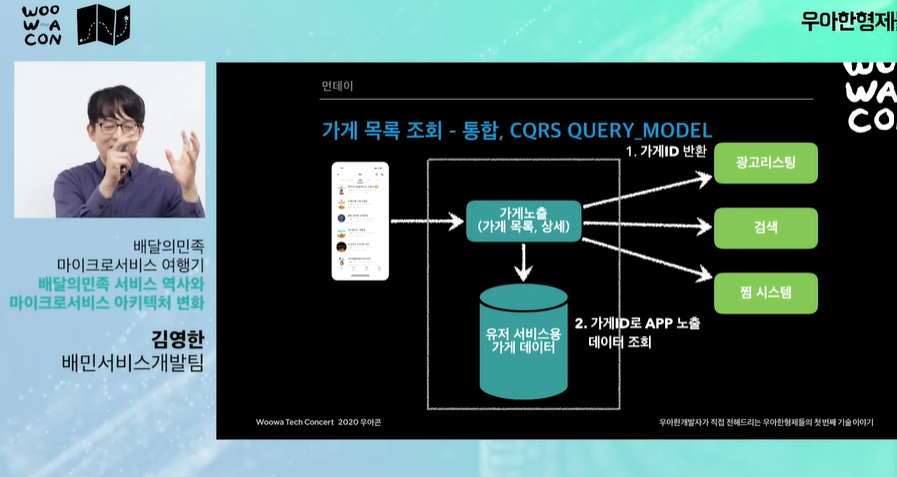
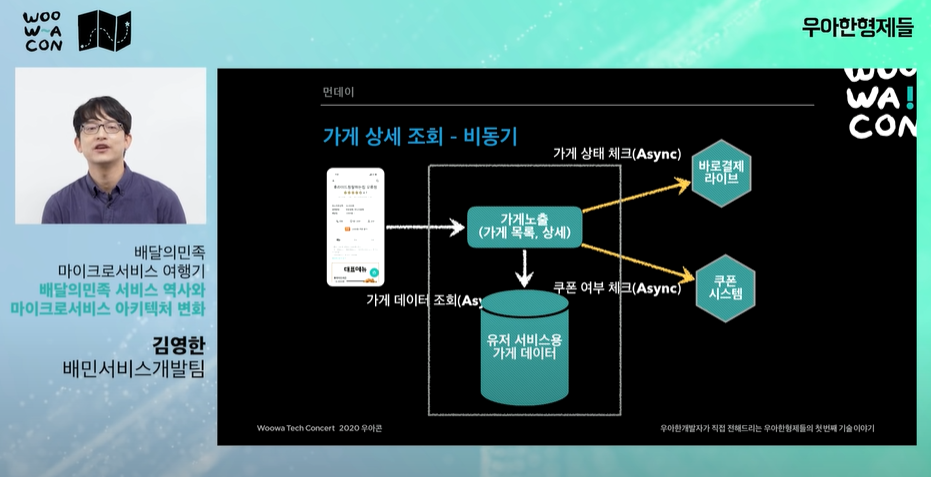
- 세가지 시스템을 비동기로 한 번에 조회
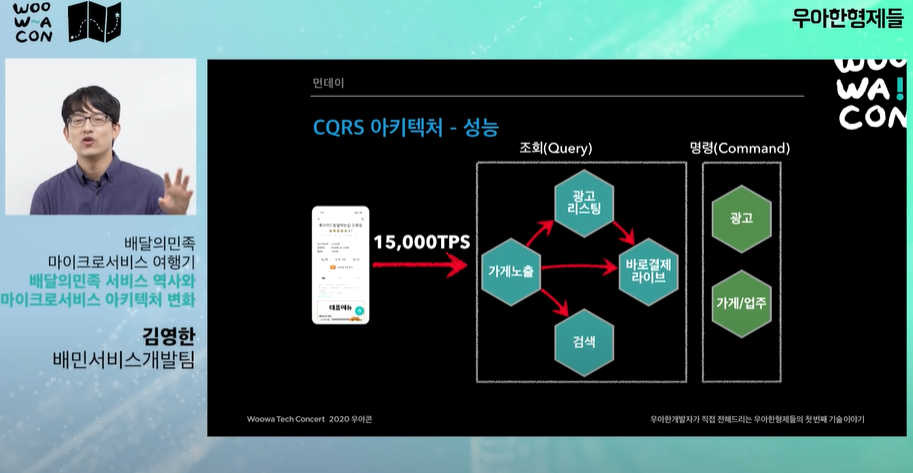
- 이제 CQRS 아키텍처로 변경한 이후 성능을 보면 트래픽이 들어오면 뒷단을 아예 호출하지 않고 조회용 쿼리와 관련된 시스템만 트래픽을 받는다. (명령 시스템은 안정성이 중시되는 db라 트래픽을 많이 받으면 문제가 생긴다.)
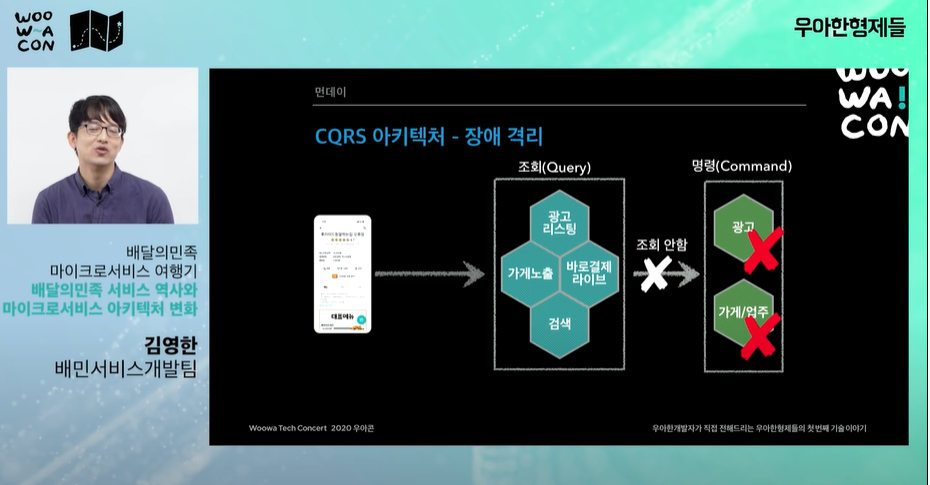
- 장애가 발생해도 주문시스템까지 진행 가능
- 각 시스템이 내부에 필요한 데이터 보관
- 내부 서비스(광고, 검색)의 모든 변경 내역이 이벤트로 전달
- 장애시 데이터 싱크가 늦어저도 고객 서비스 가능

- 만약 sqs sns에 장애가 발생할 경우
- 전체 import api 제공은 전체 데이터를 끌어올 수 있는 api를 사용
- 부분 import api 제공은 최근 5분간 변경된 데이터를 받는 api를 계속 돌려서 데이터 싱크르 맞춘다.

정리

- 현실적으로 모든 시스템을 이벤트 방식으로 연동할 수는 없다.
- ex) 사장님이 짜장면을 짬뽕으로 변경하면 메뉴가 변경되는 것이다.
이 경우Eventually Consistency는 싱크 차이가 있어서 완벽하게 맞출 수는 없다. - 그래서 주문 직전에 메뉴 시스템에서 api에서 유효성 검사를 한다.

-
2019년 12월 13일 DH는 딜리버리히어로를 인수한다고 발표, DH는 반독점법 제약으로 요기요를 매각하기로 결정했다. 배민의 탈루비 프로젝트가 성공해 MSA를 완성한 점이 DH의 배민 인수 절차에 큰 영향을 미쳤을 것이라 추측한다. 요기요는 MSA를 어디까지 완성했는지 알아볼 예정
-
시스템이 커지고 트래픽이 커지고 규모의 경제가 가능해지는 순간에 MSA가 필요하다.
-
단순하게 테이블 조인하면 될걸 데이터 싱크하고 맞추는 과정에 비용이 10배는 더 든다. 이를 상쇄하고도 남는 경우에 MSA로 넘어가는 것이 맞다고 김영한 개발자는 주장했다.
