.png)
윤성우의 열혈 자료구조를 읽고 복습한 내용입니다.
빅-오 표기법(Big-O Notation)
데이터의 수 n과 그에 따른 시간 복잡도 함수 T(n)을 정확하고 오차 없이 구하는 것은 대부분의 경우 쉽지 않다. 이 문제를 빅-오를 통해 해결할 수 있다.
빅-오라는 것은 함수 T(n)에서 가장 영향력이 큰 부분이 어딘가를 따지는 것인데, 이때 사용되는 표기법에 대문자 O가 사용되기 때문에 빅-오라고 한다. 빅-오에 대한 설명을 위해서 다음 시간 복잡도 함수를 살펴보자.
앞서 시간 복잡도 함수 T(n)을 구하는 이유에 대해 수차례 설명하였으니, 이와 같이 근사치 식을 구성해도 문제가 되지 않음에 동의할 것이다. 그렇다면, 한차례 더 간략하게 해도 무리가 없을까?
다음 표를 통해서 에서 이 차지하는 비율을 확인해보자.
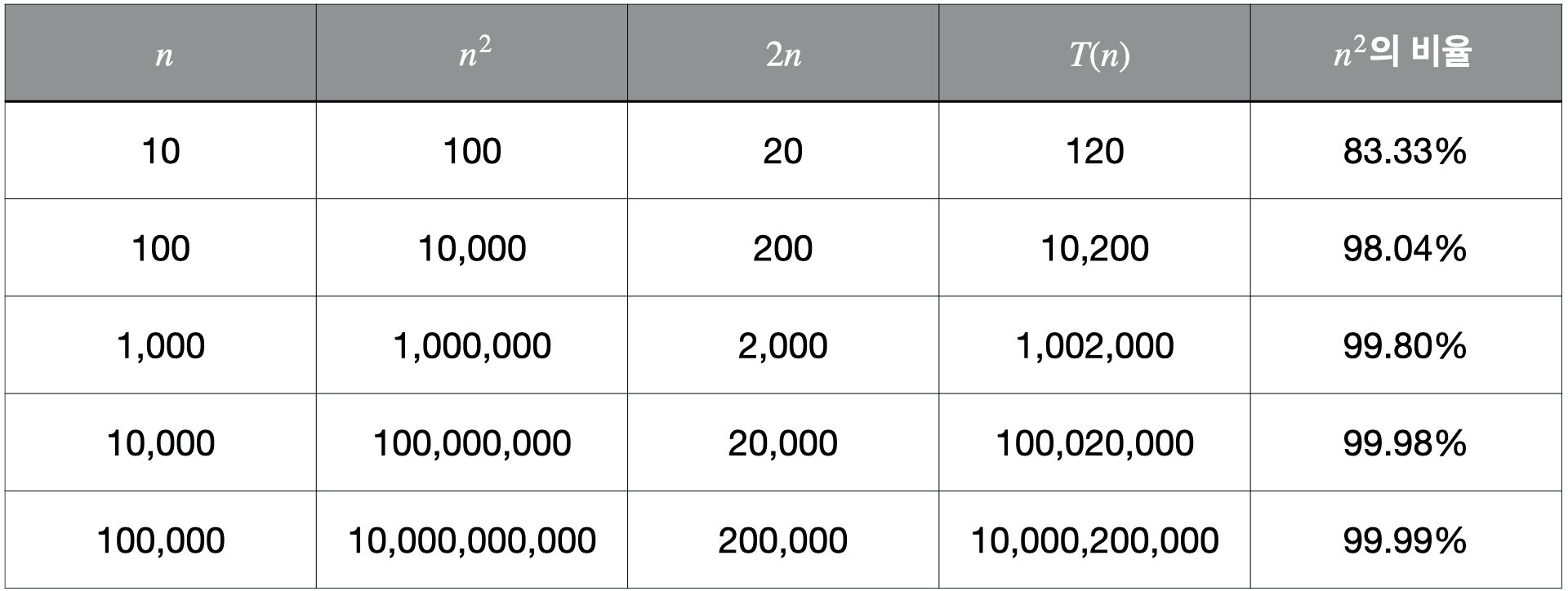
표에서 보이듯이 이 차지하는 비율은 절대적이다. n이 조금만 증가해도 이내 이 차지하는 비율은 99%를 넘어선다. 그렇기 때문에 간략화 할 수 있는 것이다.
이를 빅-오 표기법으로 표현하면 다음과 같으며,
"빅-오 오브 (Big-O of )" 라고 읽는다.
정리하면 함수 의 빅오는 이며, 이는 의 증가 및 감소에 따른 의 변화 정도가 의 형태를 띰을 의미한다.
단순하게 빅-오 구하기
수식을 보고서 빅-오를 구하는 방법을 알아보자.
"T(n)이 다항식으로 표현이 된 경우, 최고차항의 차수가 빅-오가 된다."
이를 일반화하면 다음과 같다.
즉, 다항식으로 표현된 시간 복잡도 함수 에서 실제로 큰 의미를 갖는 것은 '최고차항의 차수'라는 얘기다. 왜 '최고차항의 계수'는 중요하지 않을까?
빅-오는 '데이터 수의 증가에 따른 연산횟수의 증가 형태(패턴)'을 나타내는 표기법으로, 늘어나는 방식이 중요한 것이지 그 각각의 값이 중요한 것이 아니기 때문이다.
대표적인 빅-오
이렇게 '데이터 수의 증가'에 따른 '연산횟수의 증가 형태를 표현한 것'이 빅-오이다 보니, 대표적인 빅-오 표기가 다음과 같이 존재하니 이를 알아둘 필요가 있다.
상수형 빅-오
데이터 수에 상관없이 연산횟수가 고정인 유형의 알고리즘을 의미한다. 예를 들어, 연산의 횟수가 데이터 수에 상관없이 3회 진행되는 알고리즘일지라도 O(3)이 아닌 O(1)이라 한다.
로그형 빅-오
데이터 수의 증가율에 비해서 연산횟수의 증가율이 훨씬 낮은 알고리즘을 의미한다. 따라서 매우 바람직한 유형이다. 참고로 로그의 밑에 따라 차이가 나긴 하지만, 그 차이는 알고리즘의 성능관점에서 매우 미미하기 때문에 대부분의 경우에 있어서 무시된다.
선형 빅-오
데이터의 수와 연산횟수가 비례하는 알고리즘을 의미한다.
선형로그형 빅-오
데이터의 수가 두 배로 늘어날 때, 연산횟수는 두 배 조금 넘게 증가하는 알고리즘을 의미한다. n과 logn을 곱한 형태라서 난해해 보이지만, 알고리즘 중에는 이에 해당하는 알고리즘이 적지 않다.
데이터 수의 제곱에 해당하는 연산횟수를 요구하는 알고리즘을 의미한다. 따라서 데이터의 양이 많은 경우에는 적용하기 부적절하다. 이는 이중으로 중첩된 반복문 내에서 알고리즘에 관련된 연산이 진행되는 경우 발생한다. 달리 말하면 중첩된 반복문의 사용은 알고리즘 디자인에서 그리 바람직하지 못하다고 할 수 있다.
데이터 수의 세 제곱에 해당하는 연산횟수를 요구하는 알고리즘을 의미한다. 이는 삼중으로 중첩된 반복문 내에서 알고리즘에 관련된 연산이 진행되는 경우에 발생한다. 이 역시 적용하기에 무리가 있는 알고리즘이다.
지수형 빅-오
이는 '지수적 증가'라는 매우 무서운 연산횟수의 증가를 보이기 때문에, 사용하기에 매우 무리가 있는 알고리즘이다.
지금까지 설명한 빅-오 표기들의 성능(수행시간, 연산횟수)의 대소를 정리하면 다음과 같다.
순차 탐색 알고리즘과 이진 탐색 알고리즘의 비교
순차 탐색 알고리즘 함수와 빅-오 표기는 다음과 같다.
이진 탐색 알고리즘 T(n) 함수와 빅-오 표기는 다음과 같다.
두 알고리즘의 비교연산횟수를 수치적으로 비교해 보자.
- 최악의 경우를 대상으로 비교하는 것이 목적이므로 탐색의 실패를 유도한다.
- 탐색의 실패가 결정되기까지 몇 번의 비교연산이 진행되는지를 센다.
- 데이터의 수는 500, 5000, 50000일 때를 기준으로 각각 실험을 진행한다.
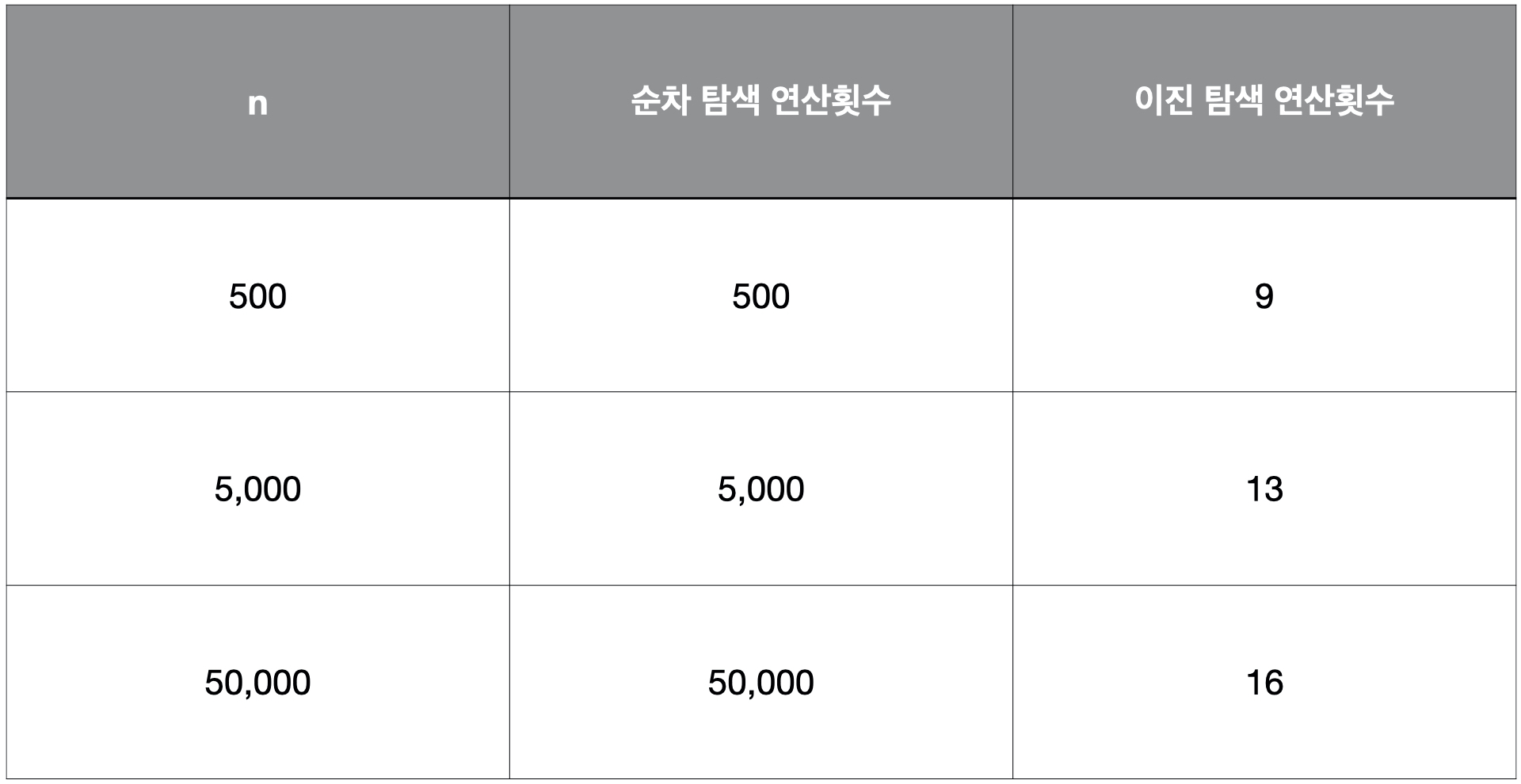
위의 표에 정리된 결과는 선형 빅-오의 알고리즘과 로그형 빅-오의 알고리즘의 연산횟수에 얼마나 큰 차이가 있는지 보여준다.
.jpg)