
해당 시리즈는 [ 파이썬 알고리즘 인터뷰 ] 를 통해 학습한 내용을 정리한 글입니다.
빅오(big-O)는 알고리즘을 다루는 거의 모든 책에서 다루는 중요한 주제이다.
빅오는 입력값이 커질 때 알고리즘의 실행시간 (시간 복잡도) 과 함께 공간 요구사항 ( 공간 복잡도 )가 어떻게 증가하는지를 분류하는데 사용되며, 알고리즘의 효율성을 분석하는 데에도 매우 중요하게 활용된다.
알고리즘은 흔히 'Space-Time Tradeoff' 관계이다. 서로 반비례하는 관계이다.
빅오
빅오 (O,big-O)란 입력값이 무한대로 향할 때 함수의 상한을 설명하는 수학적 표기 방법이다.
** 충분히 큰 입력에서는 알고리즘의 효율성에 따라 수행 시간이 크게 차이가 날 수 있다.
빅오는 점근적 실행 시간을 표기하는 방법 중 하나다.
점근적 실행 시간은 달리 말하면 시간 복잡도라고 할 수 있다.
시간 복잡도는 어떤 알고리즘을 수행하는데 걸리는 시간을 설명하는 계산 복잡도를 의미한다.
시간 복잡도를 표기할 때는 입력값에 따른 알고리즘의 실행 시간의 추이만을 살피게 된다.
이 추이에 따른 빅오 표기법의 종류는 크게 다음과 같다.
1. O(1)
입력값이 아무리 커도 실행 시간은 일정하다. 최고의 알고리즘.
상수 시간을 갖는 알고리즘은 일평생 찾아도 찾기 힘들다.
O(1)에 실행되는 알고리즘으로 해시 테이블의 조회 및 삽입이 이에 해당한다.
2. O(log n)
여기서부터 실행 시간은 입력값에 영향을 받는다.
그러나 로그는 큰 입력값에도 크게 영향을 받지 않는 편으로 웬만한 n의 크기에 대해서도 매우 견고하다.
대표적으로 이진검색이 이에 해당한다.
3. O(n)
입력값과 실행 시간이 비례한다. 선형 시간 알고리즘이라고 한다.
정렬되지 않은 리스트에서 최댓값, 최솟값을 찾는 경우가 이에 해당한다.
이 값을 찾기 위해서는 모든 입력값을 한 번 이상은 살펴봐야 한다.
4. O(n log n)
병합 정렬을 비롯한 대부분의 효율 좋은 알고리즘이 이에 해당한다.
적어도 모든 수에 대해 한 번 이상은 비교해야 하는 비교 기반 정렬 알고리즘은
아무리 좋아도 O (n log n)보다 빠를 수 없다.
물론 입력값이 최선인 경우, 비교를 건너뛰어 O(n)이 될 수 있다.
5. O(n^2)
버블정렬 같은 비효율적인 정렬 알고리즘이 이에 해당한다.
6. O(2^n)
피보나치 수를 재귀로 계산하는 알고리즘이 이에 해당한다.
7. O(n!)
각 도시를 방문하고 돌아오는 가장 짧은 경로를 찾는 문제를 브루트 포스로 풀이할 때가 이에 해당한다.
가장 느린 알고리즘으로 입력값이 조금만 커져도 웬만한 다항 시간 내에는 계산이 어렵다.
상한과 최악
빅오(O)는 상한을 의미한다. 이외에도 하한을 나타내는 빅오메가, 평균을 의미하는 빅세타가 있다.
여기서 중요한 점은 상한을 최악의 경우와 혼동하는 것 이다.
빅오 표기법은 정확하게 쓰기엔 너무 길고 복잡한 함수를 '적당히 정확하게' 표현하는 방법일 뿐, 최악의 경우/평균적인 경우의 시간 복잡도와는 아무런 관계가 없는 개념이다!
빅오 표기는 복잡한 함수 f(n)이 있을 경우, 이 함수의 실행 상한과 하한을 의미한다.
즉 가장 빨리 실행될 때(하한), 가장 늦게 실행될 때(상한)을 뜻하며
이 중 가장 늦게 실행될 때를 빅오(O), 가장 빨리 실행될 때를 빅오메가로 지칭한다.
n이 작을 때, 즉 n0 이하일 때의 값이 작은 경우는 무시하며, 빅오 표기법은 n이 매우 클 때의 전체적인 큰 그림에 집중한다.
빅오 표기법은 주어진 (최선/최악/평균) 경우의 수행 시간의 상한을 나타낸다.
분할 상환 분석
시간 또는 메모리를 분석하는 알고리즘의 복잡도를 계산할 때, 알고리즘의 전체를 보지 않고, 최악의 경우만을 살펴보는 것은 지나치게 비관적이라는 이유로 등장하게 된 것이 분할 상환 분석 방법이다.
대표적인 예로 '동적 배열'을 들 수 있다.
최악의 경우를 여러 번에 걸쳐 골고루 나눠주는 형태로 알고리즘의 시간 복잡도를 계산해준다.
그러면 기존의 더블링이 일어난다는 이유로 O(n)이었던 삽입 시간 복잡도가 O(1)로 바뀐다.
자료형
리스트와 딕셔너리는 가장 많이 사용할 2가지 자료형이다.
숫자
- 파이썬에서는 숫자 정수형으로 int만을 제공한다.
- bool은 엄밀히 따지면 논리 자료형인데 파이썬에서는 내부적으로 1(true)와 0(false)로 처리되는 int의 서브 클래스다.
int 는 object의 하위 클래스이기도 하기 때문에 결국 다음과 같은 구조를 띤다.
object > int > bool
매핑
매핑은 키와 자료형으로 구성된 복합 자료형이다. 파이썬엔 딕셔너리만 내장되어 있다.
집합
파이썬의 집합 자료형인 set은 중복된 값을 갖지 않는 자료형이다.
set은 입력 순서가 유지되지 않으며, 중복된 값이 있을 경우 하나의 값만 유지한다.
파이썬에서 빈 집합은 다음과 같은 형태로 선언한다.
>>> a = set()빈 집합이 아닌 값이 포함된 집합을 선언할 때는 a = {1,2,3} 형태로 한다. 집합은 딕셔너리와 동일하게 중괄호를 사용하므로 유의해야 한다.
시퀀스
시퀀스는 어떤 특정 대상의 순서 있는 나열을 의미한다.
예를 들어 str은 문자의 순서있는 나열로 문자열을 이루는 자료형이고,
list는 다양한 값들을 배열 형태의 순서 있는 나열로 구성하는 자료형이다.
파이썬에서는 list 시퀀스타입이 사실상 배열의 역할을 수행한다.
시퀀스는 불변, 가변으로 구분된다.
불변에는 str, tuple, bytes가 해당된다.
반면 list는 가변이다.
원시 타입
원시 타입은 메모리에 정확하게 타입 크기만큼의 공간을 할당하고, 그 공간을 오로지 값으로 채워넣는다.
C가 그러하다. Java도 원시타입과 클래스 객체를 지원한다.
하드웨어에 가까운 원시타입은 좀 더 빠른 속도로 실행할 수 있다.
파이썬은 애초에 편리한 기능 제공에 우선순위를 둔 언어인만큼 느린 속도와 더 많은 메모리를 차지하더라도 훨씬 더 다양한 기능을 제공할 수 있는 객체에 더 관심을 두었다.
객체
파이썬은 모든 것이 객체이다.
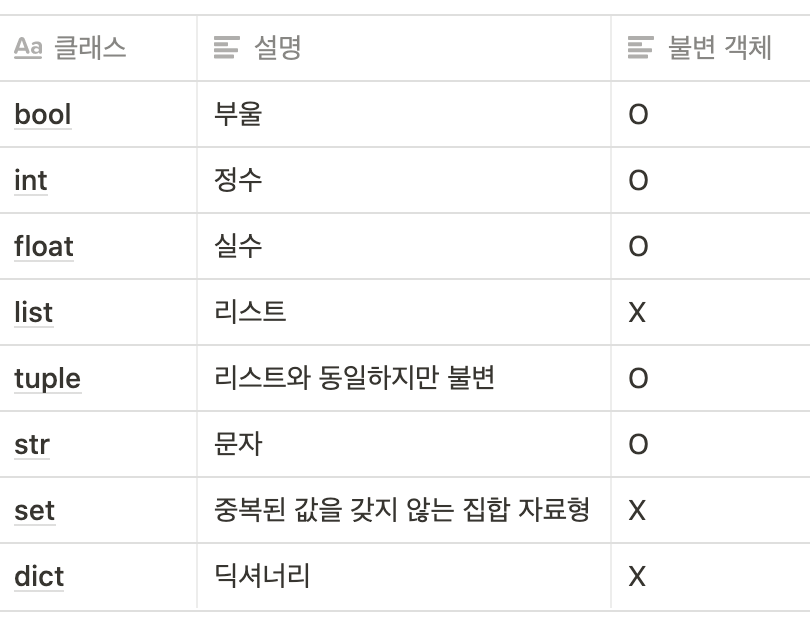
-
불변 객체
-
문자와 숫자는 불변 객체라는 차이만 있다.
-
값을 담고 있는 변수는 사실 참조일 뿐이고, 실제로 값을 갖고 있는 int와 str은 불변 객체다.
-
한번 값을 담아두면 더 이상 값을 변경할 수 없다.
-
상수처럼 read-only 용도로 사용하거나 값이 변하지 않기 때문에 dict의 키나 set의 값으로도 사용할 수 있다. list는 언제든 값이 변할 수 있기 때문에 사용할 수 없다.
-
-
가변 객체
- 다른 변수가 참조하고 있을 때 그 변수의 값 또한 변경 가능하다.
is와 ==
is는 id() 값을 비교하는 함수이다.
None은 null로서 ==로는 비교가 불가능하다.
==는 값을 비교하는 연산자이다.
