(이전 글과 이어집니다. 읽고 오셔야 맥락이 이해가 갑니다)
분할압축 하듯이
QR 코드 하나에 넣기 너무 큰 데이터는 여러 QR 코드로 나눌 수 있다는 생각이 들었다.
마치 파피루스같은 긴 종이에 글을 적듯이, Qr Code를 이어붙이면 긴 내용도 담을 수 있는 셈이다.
 파피루스는 이렇게 생겼다.
파피루스는 이렇게 생겼다.
![]() (이 파피루스가 아니다.)
(이 파피루스가 아니다.)
그래서 분할압축한 QrCode를 QR Papyrus라고 부르기로 했다.
그런데 큰 파일을 1.2kb단위(qr code 하나의 크기)로 나누기만 하면 될까?
물론 아니다.
하나의 큰 "원본 파일"을 여러 개의 Qr Code들의 "셋트"로 나눈다면, 총 몇개의 qr code 셋트로 분할 되었는지, 그리고 각 코드가 몇 번째인지(인덱스) 등을 담아야 한다.
그것 말고도 담을게 많으니 하나하나 고민해보자.
편의를 위해 용어를 정리하면, "원본 파일"은 분할할 파일을, 그 과정에서 만들어진 qr code 전체를 "셋트", 그 안에 속한 qr code 하나하나는 "유닛"이라 부르겠다. 그리고 이 모든 프로토콜을 Qr Papyrus라고 부르겠다.
1) 심볼: 우선, 인식하는 "유닛"이 일반 QR code인지, 아니면 분할압축된 것인지 확인할 수 있어야 한다. 그러니 QR code의 첫 3바이트를 "QRP"라는 글자로 채우자.
(여기서 QRP는 QR Papyrus의 약자로 정한 심볼이다.)
2) 버젼: 지금은 QR Papyrus의 첫 번째 버젼의 규칙을 정하고 있으니, 버젼을 나타내는 숫자 1도 추가해야 겠다
3) 자료형: 이제 자료형이 파일인지 아니면 문자열인지 (그냥 두 종류로만 했다), 그리고 압축했는지, 암호화했는지 등등을 나타내는 1byte크기의 값을 추가한다.
4) 셋트의 크기: 그 다음 1바이트는 셋트에 속한 qr code의 개수가 모두 몇 개인지를 나타낸다. 255개까지는 나타낼 수 있으니 큰 무리는 없을 것이다. (1.2kb * 255면 거의 300kb)
5) 무결성: 원본 파일의 해쉬값을 2byte 추가한다. 이게 없다면 서로 다른 셋트가 섞여버리면 다시는 정렬할 수 없다. 가령 강아지 사진과 고양이 사진을 각각 분할압축한 60개의 qr code가 섞여버렸다면, hash값으로 어떤 qr code들이 한 셋트에 속하는지 구분하는 셈이다.
6) 인덱스: 마지막으로, 해당 Qr code가 전체 셋트 안에서 몇 번째 코드인지 가리키는 1byte 크기의 숫자 하나를 추가한다.
여기까지를 "유닛"의 "헤더"라고 하고, 남은 부분은 "바디"라고 부르며 실제 분할된 파일(혹은 문자열)을 최대한 집어넣는다.
파일이라면 파일명과 확장자도 추가한다.
글로 써놓으니 어려울텐데, 코드 주석은 아래처럼 작성했다.
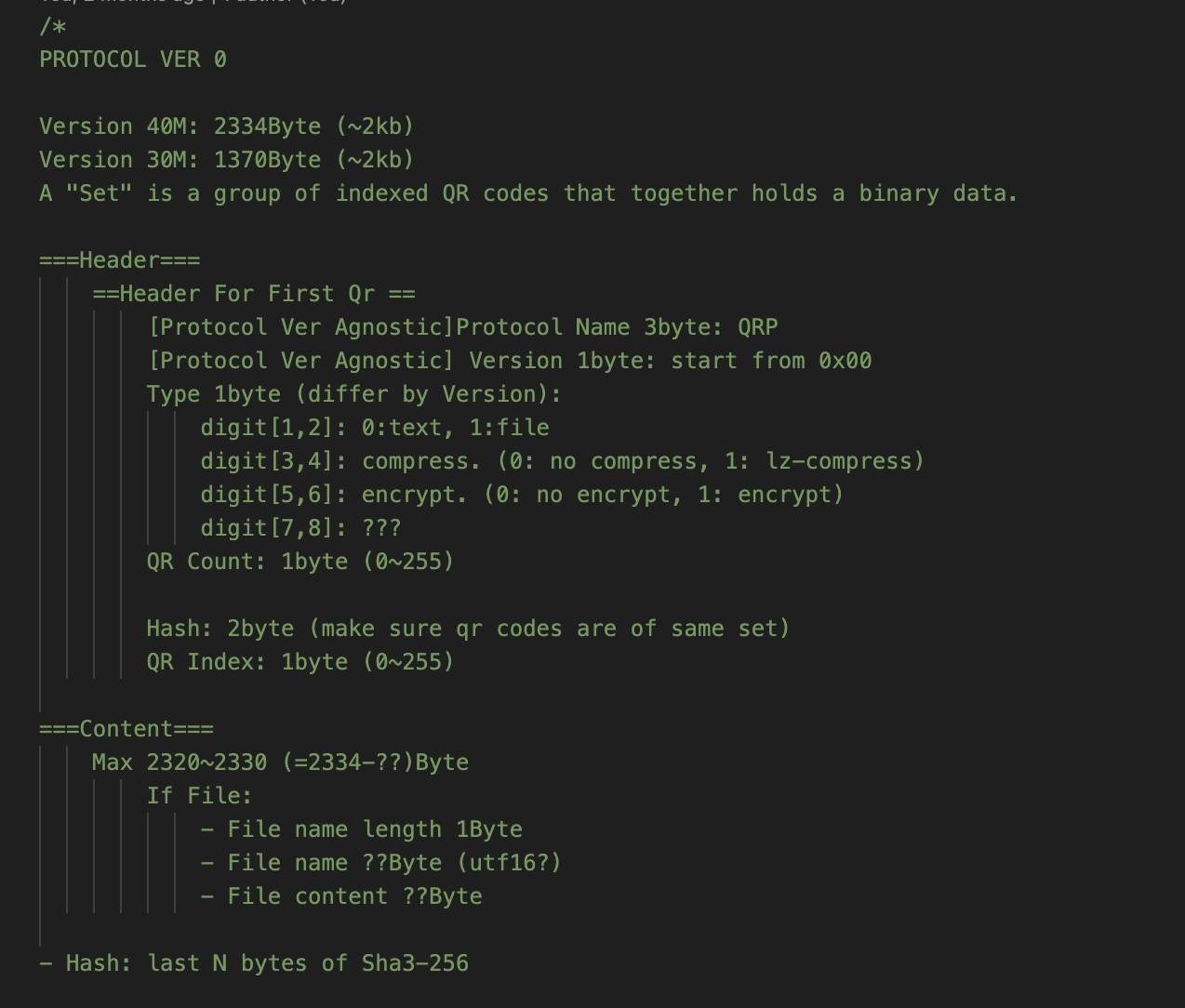
이제 설계는 다 했으니 본격적으로 코드를 짜볼 시간이다.
그 과정은 다음 글에서...
