?
- logstash_pop.conf 작성
input{
file{
path => "/root/LABs/population.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns =>
["Country",
"1980", "1981", "1982", "1983", "1984", "1985", "1986", "1987", "1988", "1989", "1990", "1991", "1992", "1993", "1994", "1995", "1996", "1997", "1998", "1999", "2000", "2001", "2002", "2003", "2004", "2005", "2006", "2007", "2008", "2009", "2010"]
}
mutate {convert => ["1980", "float"]}
mutate {convert => ["1981", "float"]}
mutate {convert => ["1982", "float"]}
mutate {convert => ["1983", "float"]}
mutate {convert => ["1984", "float"]}
mutate {convert => ["1985", "float"]}
mutate {convert => ["1986", "float"]}
mutate {convert => ["1987", "float"]}
mutate {convert => ["1988", "float"]}
mutate {convert => ["1989", "float"]}
mutate {convert => ["1990", "float"]}
mutate {convert => ["1991", "float"]}
mutate {convert => ["1992", "float"]}
mutate {convert => ["1993", "float"]}
mutate {convert => ["1994", "float"]}
mutate {convert => ["1995", "float"]}
mutate {convert => ["1996", "float"]}
mutate {convert => ["1997", "float"]}
mutate {convert => ["1998", "float"]}
mutate {convert => ["1999", "float"]}
mutate {convert => ["2000", "float"]}
mutate {convert => ["2001", "float"]}
mutate {convert => ["2002", "float"]}
mutate {convert => ["2003", "float"]}
mutate {convert => ["2004", "float"]}
mutate {convert => ["2005", "float"]}
mutate {convert => ["2006", "float"]}
mutate {convert => ["2007", "float"]}
mutate {convert => ["2008", "float"]}
mutate {convert => ["2009", "float"]}
mutate {convert => ["2010", "float"]}
}
output {
elasticsearch {
hosts => "192.168.56.101:9200"
index => "population"
}
stdout {}
}- logstash 실행
/usr/share/logstash/bin/logstash -f ./logstash_pop.conf
...
"2009" => 0.76615,
"Country" => "Reunion",
"2001" => 0.73257,
"1989" => 0.59,
"@version" => "1",
"1990" => 0.6,
"1992" => 0.62,
"1994" => 0.64,
"2008" => 0.76615,
"1988" => 0.57,
"message" => "Reunion,0.51,0.51,0.52,0.53,0.54,0.55,0.56,0.57,0.57,0.59,0.6,0.607,0.62,0.63,0.64,0.65,0.66,0.67,0.68,0.7,0.72,0.73257,0.74387,0.75517,0.76615,0.76615,0.76615,0.76615,0.76615,0.76615,0.76615",
"path" => "/root/LABs/population.csv",
"1980" => 0.51
}
{
"1997" => 6.75108,
"1981" => 5.8288,
"1987" => 6.93908,
"1986" => 6.71493,
"2005" => 8.75245,
"2006" => 9.03018,
"1991" => 6.46448,
"1999" => 7.17102,
"message" => "Somalia,5.79356,5.8288,5.8345,6.01035,6.21774,6.45854,6.71493,6.93908,6.91829,6.76633,6.69204,6.46448,6.11621,6.10102,6.26444,6.40072,6.57426,6.75108,6.9652,7.17102,7.38572,7.62677,7.89678,8.17424,8.45947,8.75245,9.03018,9.29161,9.55867,9.83202,10.11245",
"path" => "/root/LABs/population.csv",
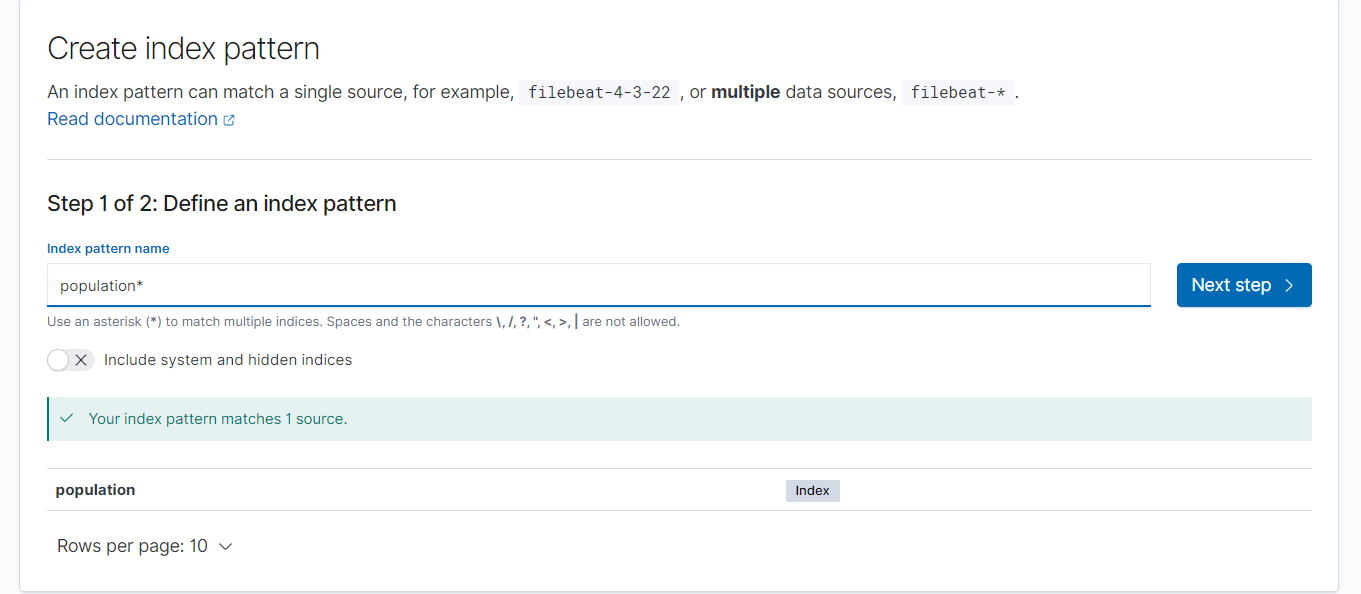
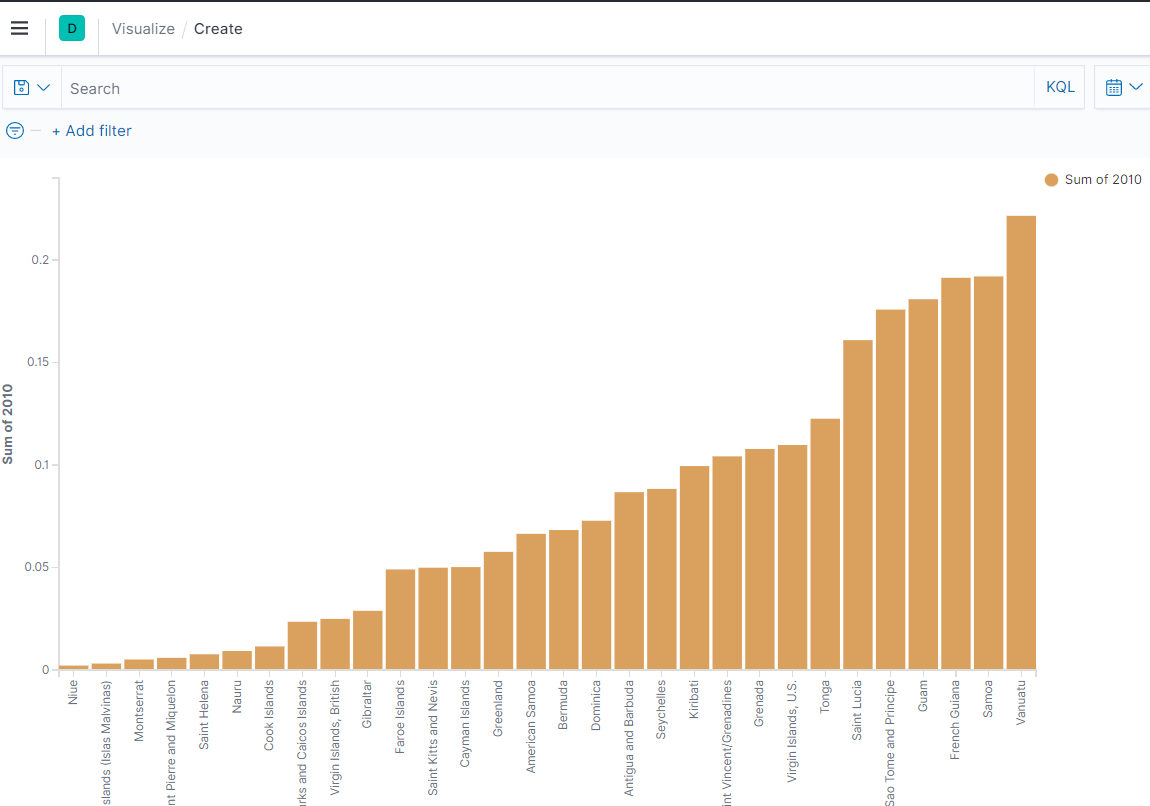
- 키바나에서 인덱스 추가
💻 opensearch 자습서
https://docs.aws.amazon.com/ko_kr/opensearch-service/latest/developerguide/search-example.html
샘플 데이터 인덱싱
도메인에 대한 OpenSearch Dashboards URL으로 이동합니다. OpenSearch Service 콘솔의 도메인 대시보드에서 URL을 찾을 수 있습니다.
이름 암호로 로그인
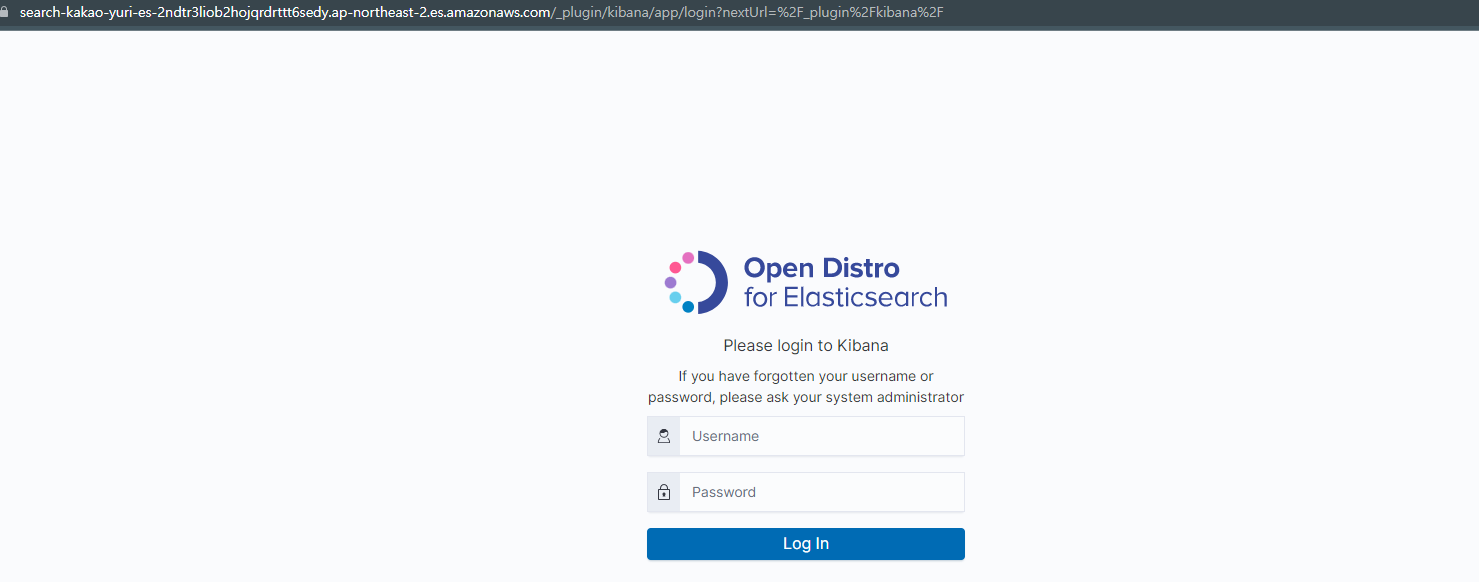
로그인 성공 후 화면
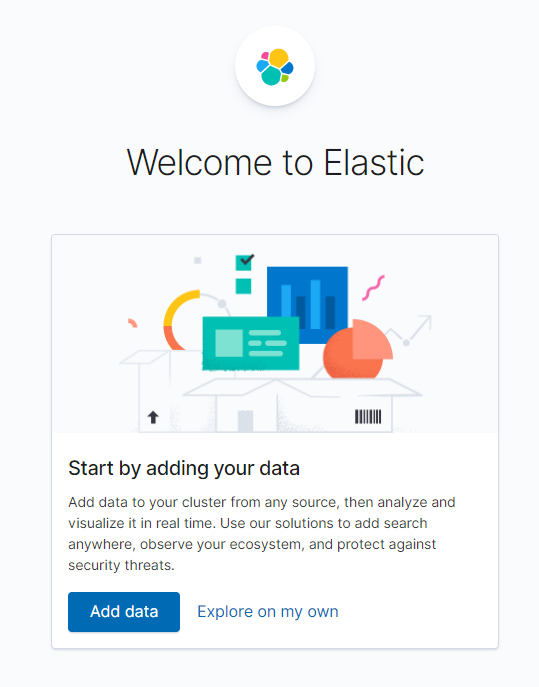
왼쪽 탐색 패널 > Dev Tools 접속
자습서 페이지의 sample-movies.zip 다운로드 후 압축 해제하고 vscode 등의 에디터를 이용하여 bulk 파일 내용을 복사한다.
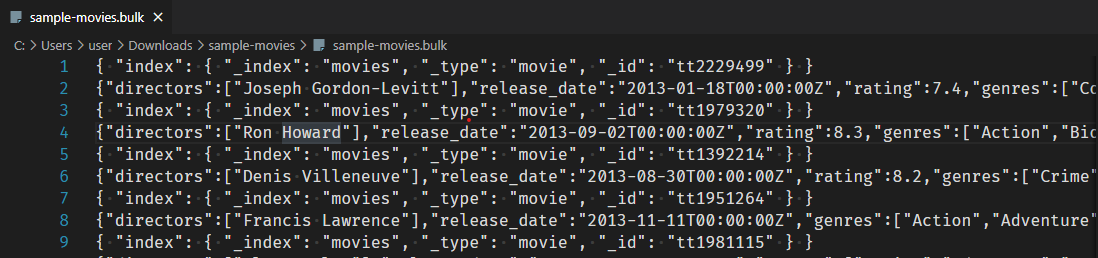
_bulk API 사용하여 5,000개의 문서를 movies 인덱스에 추가한다.
POST https://search-kakao-yuri-es-2ndtr3liob2hojqrdrttt6sedy.ap-northeast-2.es.amazonaws.com/_bulk
[bulk 파일 내용 붙여넣기]curl -XPOST -u kakao-admin:Pass123# https://search-kakao-yuri-es-2ndtr3liob2hojqrdrttt6sedy.ap-northeast-2.es.amazonaws.com/_bulk -H Content-Type:application/json --data-binary @bulk.json인덱스 생성 완료오
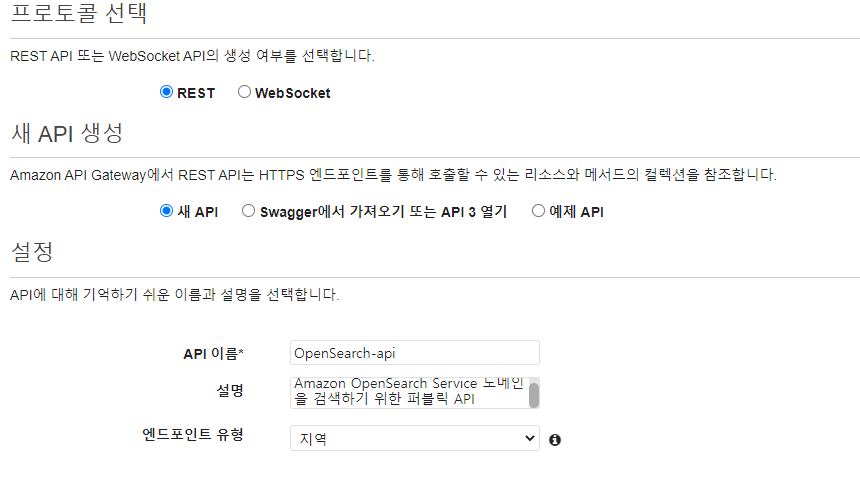
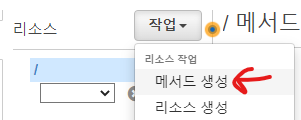
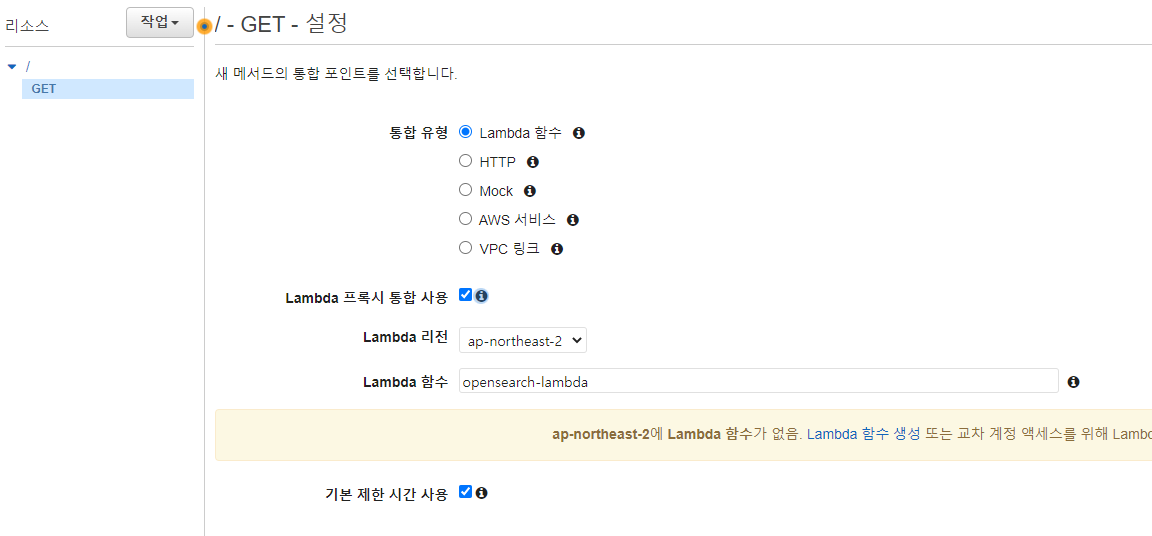
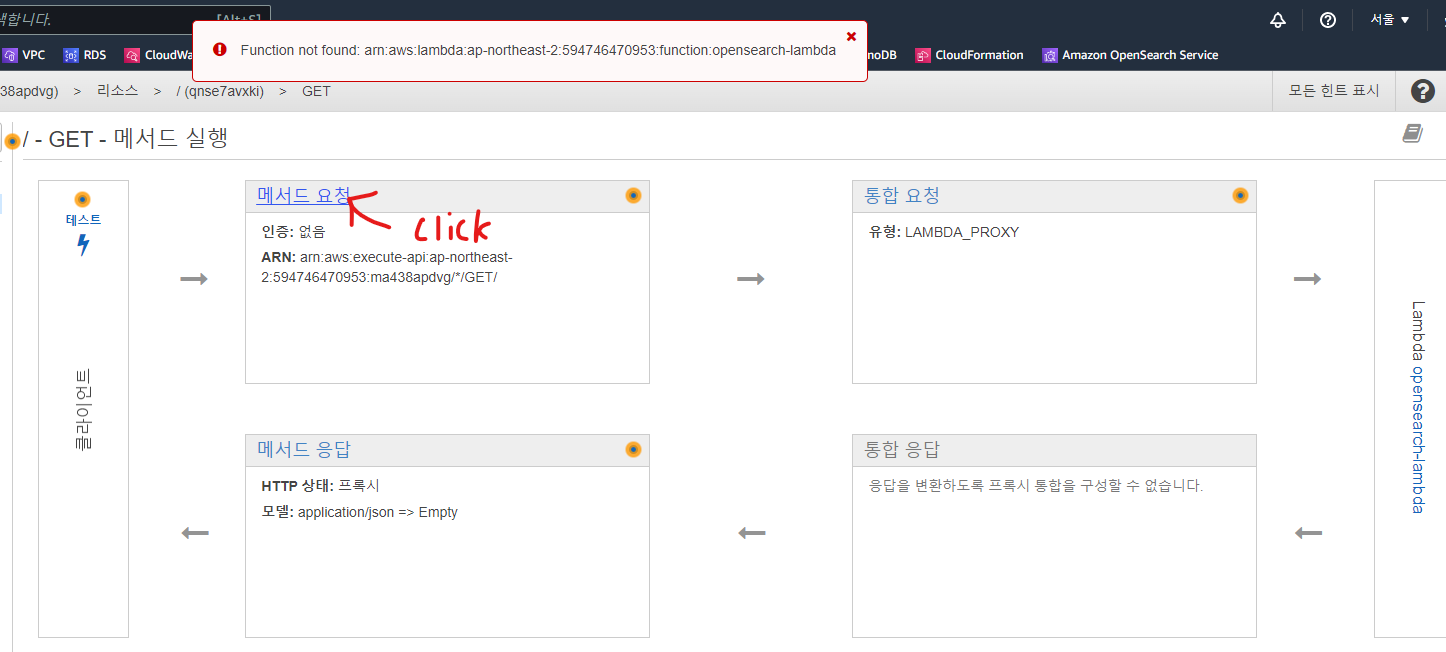
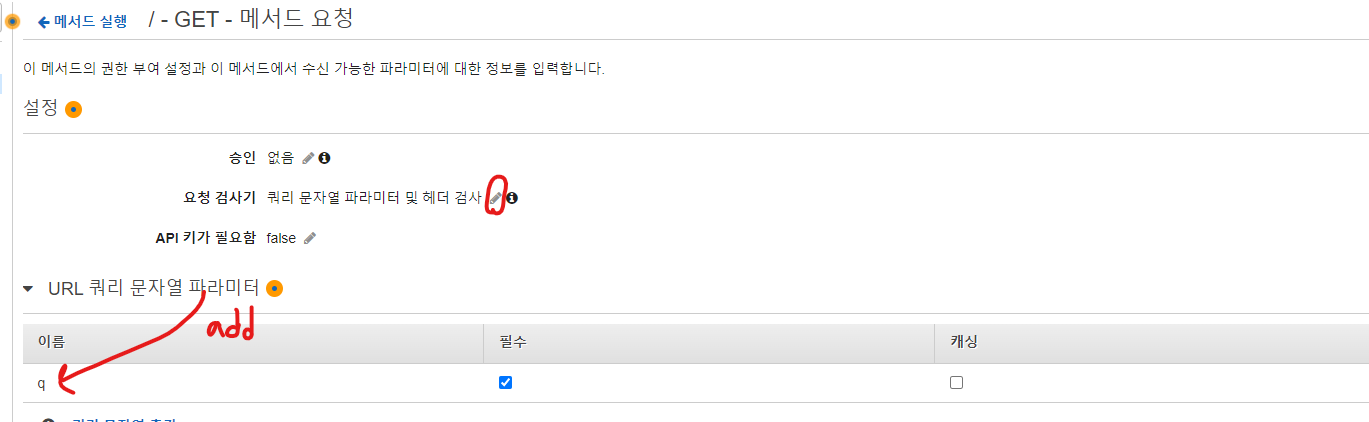
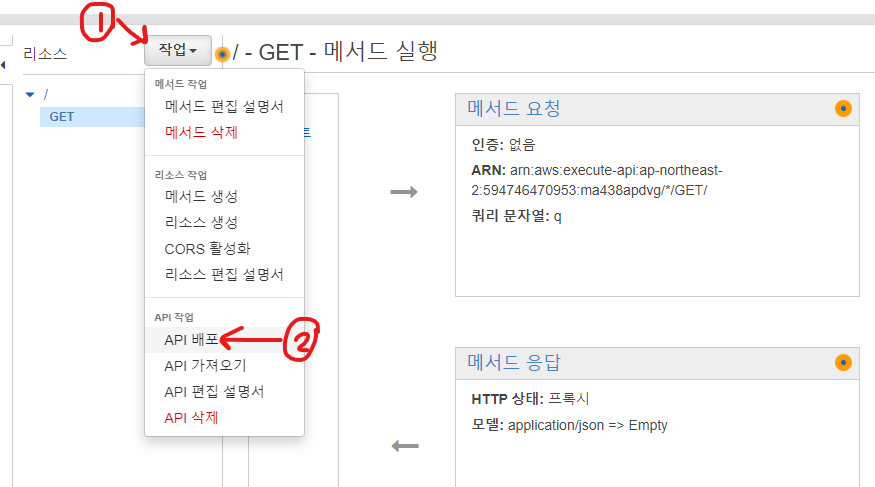
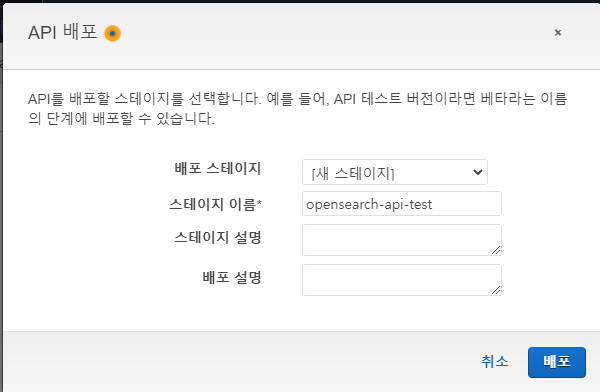
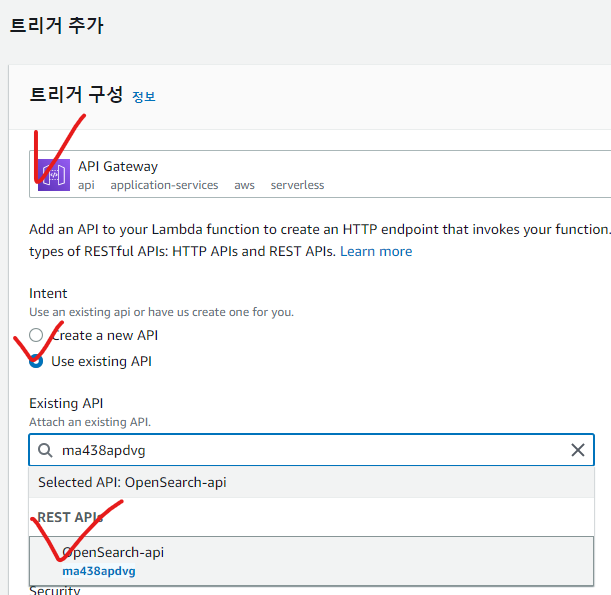
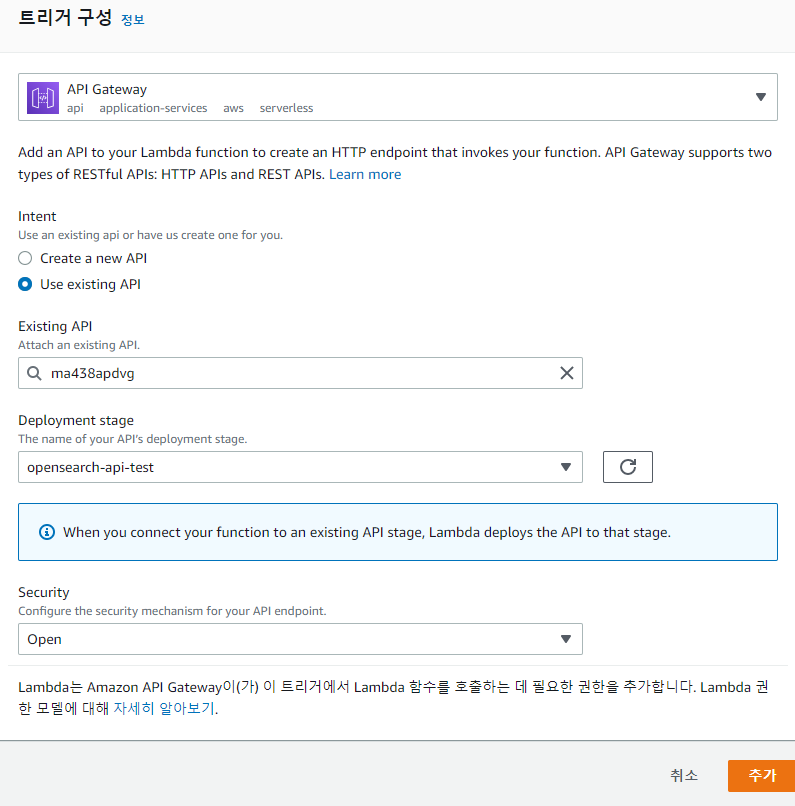
API Gateway에서 API 생성

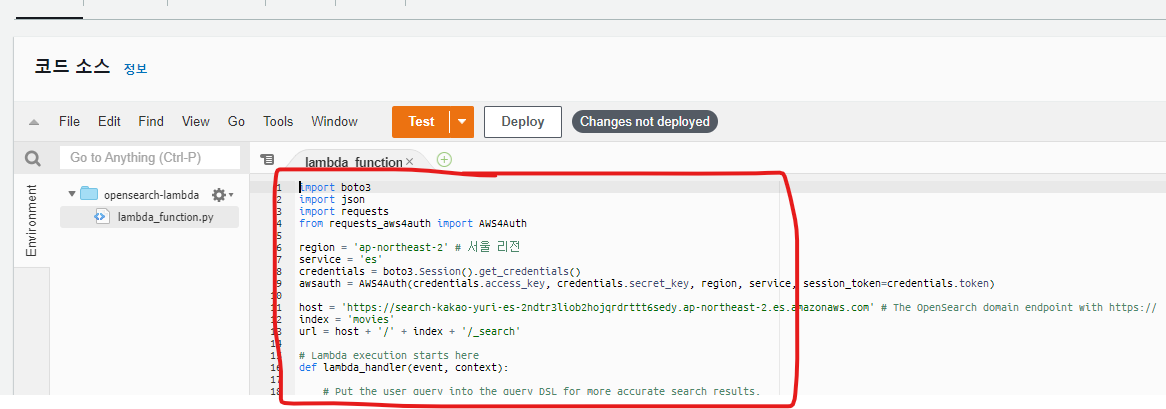
import boto3
import json
import requests
from requests_aws4auth import AWS4Auth
region = 'ap-northeast-2' # 서울 리전
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
host = 'https://search-kakao-yuri-es-2ndtr3liob2hojqrdrttt6sedy.ap-northeast-2.es.amazonaws.com' # The OpenSearch domain endpoint with https://
index = 'movies'
url = host + '/' + index + '/_search'
# Lambda execution starts here
def lambda_handler(event, context):
# Put the user query into the query DSL for more accurate search results.
# Note that certain fields are boosted (^).
query = {
"size": 25,
"query": {
"multi_match": {
"query": event['queryStringParameters']['q'],
"fields": ["title^4", "plot^2", "actors", "directors"]
}
}
}
# Elasticsearch 6.x requires an explicit Content-Type header
headers = { "Content-Type": "application/json" }
# Make the signed HTTP request
r = requests.get(url, auth=awsauth, headers=headers, data=json.dumps(query))
# Create the response and add some extra content to support CORS
response = {
"statusCode": 200,
"headers": {
"Access-Control-Allow-Origin": '*'
},
"isBase64Encoded": False
}
# Add the search results to the response
response['body'] = r.text
return response

💡 에러 {"statusCode":413,"error":"Request Entity Too Large","message":"Payload content length greater than maximum allowed: 1048576"}
-> kibana.config 를 바꿔줘야한다는데, aws가 관리하고있으니
C:\Users\user\Downloads\sample-movies>curl -XPOST -u kakao-admin:Pass123# https://search-kakao-yuri-es-2ndtr3liob2hojqrdrttt6sedy.ap-northeast-2.es.amazonaws.com/_bulk -H Content-Type:application/json --data-binary @bulk.json
{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"The bulk request must be terminated by a newline [\n]"}],"type":"illegal_argument_exception","reason":"The bulk request must be terminated by a newline [\n]"},"status":400}
-> json파일 최하단에 엔터 추가

메모장
💻 💡 📔 ⭐ ✍ 🤔 💭 📗 📘 🥺📕 📔
