

스토리지 개요
스토리지(Storage)란 데이터를 보관하는 장소로, 우리가 사용하는 모든 저장 장치를 스토리지라고 할 수 있다. 데이터 보관 방식과 데이터 사용 용도에 따라 여러 형태가 있다. 예를 들어 이동성 및 휴대성을 고려해서 간단한 데이터를 보관할 때 사용하는 USB(Universal Serial Bus), 대용량의 데이터를 보관하거나 백업할 때 사용하는 외장하드(SSD, HDD)가 있다.
IT가 발전하면서 스토리지도 변화했으며, 클라우드 환경에서 사용되는 스토리지 역시 그 목적에 따라 다양하게 변화했다.
스토리지 서비스 및 주요 기능
AWS에서 제공하는 스토리지 서비스 종류에는 블록(block) 스토리지, 파일(file) 스토리지, 객체(object) 스토리지가 있는데, 각 목적에 따라 사용하는 것이 좋다.
블록 스토리지
블록 스토리지는 단일 스토리지 볼륨을 '블록'이라는 개별 단위로 분할해서 저장한다. 각 블록은 저장된 위치에 고유한 주소가 있기 때문에 서버에서 파일을 요청하면 블록들을 재구성하여 하나의 데이터로 서버에 전달한다. 클라우드 환경에서 블록 스토리지의 각 블록은 가상 머신 인스턴스에 위치하며, 마치 일반 컴퓨터에 하드디스크를 추가하여 C 드라이브, D 드라이브처럼 논리적으로 구분해서 사용하는 것과 같다. 일반적으로 블록 스토리지는 SAN(Storage Area Network) 또는 가상 머신의 디스크로 사용된다.
파일 스토리지
파일 스토리지는 파일 수준 또는 파일 기반 스토리지라고 하며, 디렉터리 구조로 파일을 저장한다. 각 파일은 폴더에 종속되고 폴더 역시 다른 폴더에 종속되어 계층 구조를 이룬다. 따라서 파일을 찾으려면 어느 위치에 있는지 알아야 한다. 파일 스토리지는 개인용 컴퓨터와 서버에서 일상적인 작업을 공유하여 사용할 수 있지만, 파일이 늘어나면 분류하거나 정리(file system indexing)하는 데 시간이 점점 더 소요된다는 단점이 있다. 일반적으로 파일 스토리지는 NAS(Network Attached Storage)에 사용된다.
객체 스토리지
객체 스토리지는 각 데이터 조각을 가져와서 객체로 지정하고, 개별 단위로 저장한다. 파일 스토리지와 다르게 모든 객체는 중첩된 계층 구조 없이 단일한 평면적인 주소 공간에 저장된다. 이 평면 주소 공간에는 데이터 및 관련 메타데이터(metadata)로 구성된 객체에 고유 식별자가 있다. OS나 파일 시스템에 의존하지 않으면서 데이터를 저장하고 객체에 쉽게 접근할 수 있다. 객체 스토리지 시스템에서는 객체의 키(이름)만 알고 있으면 쉽고 빠르게 대상을 검색할 수 있다. 객체 스토리지 접근에는 HTTP 프로토콜 기반의 REST(Representational State Transfer) API(Application Programming Interface)를 사용한다.
객체 스토리지는 저장할 수 있는 데이터의 수와 파일 크기에 제한이 없으며 데이터 저장의 총용량 역시 무제한에 가깝다고 할 수 있다.
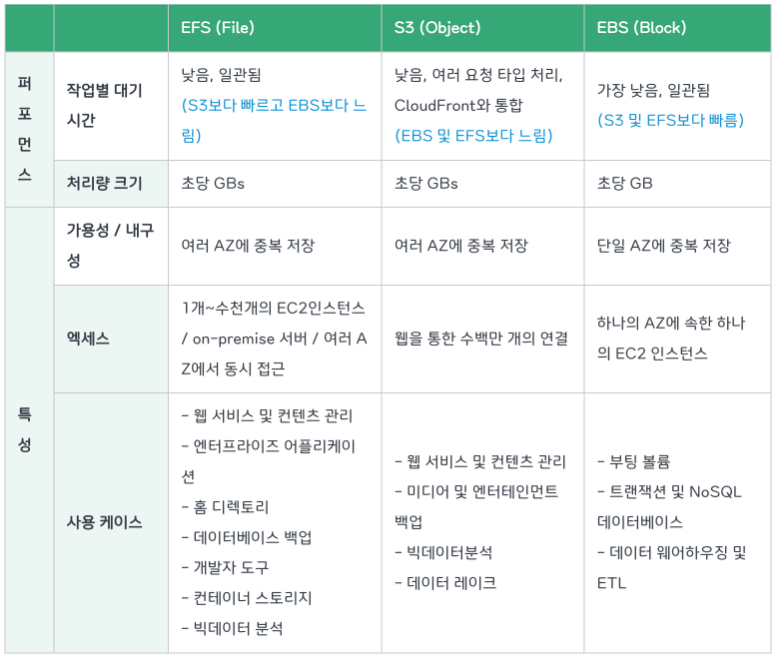
스토리지 선택 기준
클라우드 스토리지는 어디에서나 접근할 수 있는 편의성, 대량의 데이터를 수용할 수 있는 확장성을 갖추고 있다. 따라서 스토리지를 도입할 때는 클라우드 스토리지의 종류별 특징을 충분히 이해하고 목적과 상황에 맞게 선택해야 한다.
[스토리지를 선택할 때 고려 사항]
- 내구성: 데이터 손실 가능성
- 가용성: 서비스 지속 시간
- 보안: 저장 및 전송 중 데이터 보안
- 비용: 스토리지 단위 가격
- 확장성: 스토리지 크기 및 사용자 수 변경
- 성능: 스토리지 크기 및 사용자 수 변경
- 통합: 다른 서비스와 호환성
Amazon EBS
EBS란
Amazon EBS(Elastic Block Store)는 EC2 인스턴스에 사용할 수 있는 블록 스토리지 볼륨을 제공하는 서비스이다. 블록 스토리지 특성을 이용한 저장 방식이므로 데이터를 일정한 크기의 블록으로 나누어 분산 저장하는데, 볼륨 위에 파일 시스템을 생성하거나 하드디스크 드라이브 같은 블록 디바이스를 사용하는 것처럼 볼륨을 쓸 수 있다. 쉽게 운영 체제에 외장 하드디스크를 연결해서 데이터를 저장한다고 생각하면 됩니다. 또한 인스턴스에 연결된 EBS 볼륨의 구성을 동적으로 변경할 수 있다. 이처럼 EBS는 데이터베이스처럼 데이터 출입이 많은 서비스에 적합하다.
EBS 스토리지는 AWS 관리 콘솔에서 필요한 용량과 성능에 맞추어 볼륨을 생성한 후 EC2 인스턴스에 연결하고 파일 시스템을 포맷한 후 사용한다. 이때 파일 시스템 포맷은 운영 체제에 따라 다르게 사용된다. 리눅스는 xfs 또는 ext4 유형이 주로 사용되며, 윈도우는 NTFS 포맷이 주로 사용된다. 포맷이 완료되면 해당 볼륨을 서버에서 마운트한 후 데이터를 해당 디렉터리에 저장해서 사용한다.
EBS는 고속 네트워크로 연결되어 있으며, 데이터 수명 시간이 독립되어 있다. 독립된 데이터 수명 시간이란 '서로 연결된 인스턴스와 볼륨을 사용하나 해당 인스턴스를 삭제해도 볼륨은 계속 사용할 수 있고 그 볼륨에 저장된 데이터도 다른 인스턴스와 연결하여 이어서 사용할 수 있다'는 의미이다. 결론적으로 인스턴스와 EBS 볼륨은 서로 종속 관게에 있지 않으며, 인스턴스는 다수의 볼륨을 연결하여 사용할 수 있다. 하지만 하나의 EBS 볼륨은 한 번에 하나의 인스턴스에만 연결할 수 있고, 해당 인스턴스에서 지원하는 형태의 시스템으로 포맷해야만 사용할 수 있다.
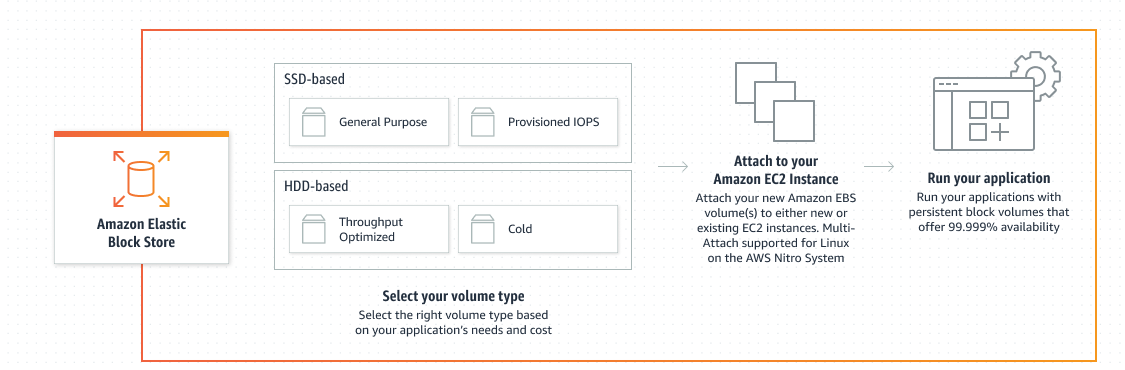
EBS 특징
- 데이터 가용성: 단일 하드웨어 구성 요소의 장애 때문에 데이터가 손실되지 않도록 해당 가용 영역 내에서 자동으로 데이터를 복제한다.
- 데이터 지속성: EBS 볼륨은 인스턴스 수명과 관계없이 유지되는 비관계형 인스턴스 스토리지이다.
- 데이터 안정성: Amazon EBS 암호화(encryption) 기능으로 암호화된 EBS 볼륨을 생성할 수 있으며, 암호화 표준 알고리즘(AES-256)을 사용한다.
- 데이터 백업: 모든 EBS 볼륨의 스냅샷(백업)을 생성하고, 다중 가용 영역에 중복 저장이 가능한 Amazon S3(Simple Storage Service)에 볼륨 내 데이터 사본을 백업할 수 있다.
- 데이터 확장성: 서비스를 중단할 필요 없이 볼륨 유형, 볼륨 크기, IOPS(Input/Output operations Per Second) 용량을 수정할 수 있다.
EBS 볼륨 유형
EBS 볼륨에는 크게 SSD와 HDD 유형이 있다. SSD는 메모리형 디스크를 사용하며, HDD는 플래터(platter) 디스크를 사용한다. 데이터를 빠르게 읽고 처리하는 능력이 좋은 SSD는 주로 서버의 운영 체제가 설치되는 OS 영역이나 일반 데이터베이스 보관용 스토리지 유형으로 사용된다. HDD는 속도와 상관없이 데이터 저장 용량이 많아 필요할 때 사용하므로 데이터 분석에 주로 활용된다.
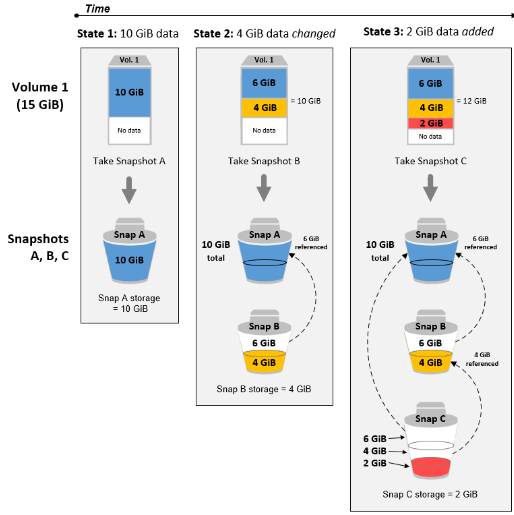
EBS 스냅샷
EBS 스토리지의 대표적인 특징인 EBS 스냅샷 기능은 말 그대로 특정 시점에 포인트를 찍어서 그 시점으로 되돌아갈 수 있는 지점을 만드는 기능이다. 증분식 백업 방식을 이용하여 마지막 스냅샷 이후 변경되는 데이터 블록만 기록하고 복제하므로 저장 비용과 시간도 효과적으로 절감할 수 있다.
또한 매번 원본과 크기가 같지 않아도 변경된 부분만 증분되어 백업되기 때문에 특정 데이터를 삭제해도 어느 한 부분의 스냅샷만 가지고 있다면 복구할 수 있다. 스냅샷은 기본적으로 Amazon S3라는 스토리지 공간에 저장되어 여러 가용 영역에 자동으로 복제된다.
EFS란
Amazon EFS(Elastic File System)는 클라우드 환경과 온프레미스 환경에서 사용할 수 있는 완전 관리형 네트워크 파일 시스템이다. 완전 관리형이란 클라우드에서 하드웨어 프로비저닝 유지 관리, 소프트웨어 구성, 모니터링, 복잡한 성능 조절 등 모든 것을 관리하기 때문에 사용자 입장에서는 별다른 관리가 필요 없다는 의미이다. 처음 파일 시스템을 생성한 후 서버에 연결하면 사용한 만큼 자동으로 스토리지 크기가 확장되고, 사용한 만큼만 비용을 지불하면 되기 때문에 사실상 용량 제한 없이 사용할 수 있다.
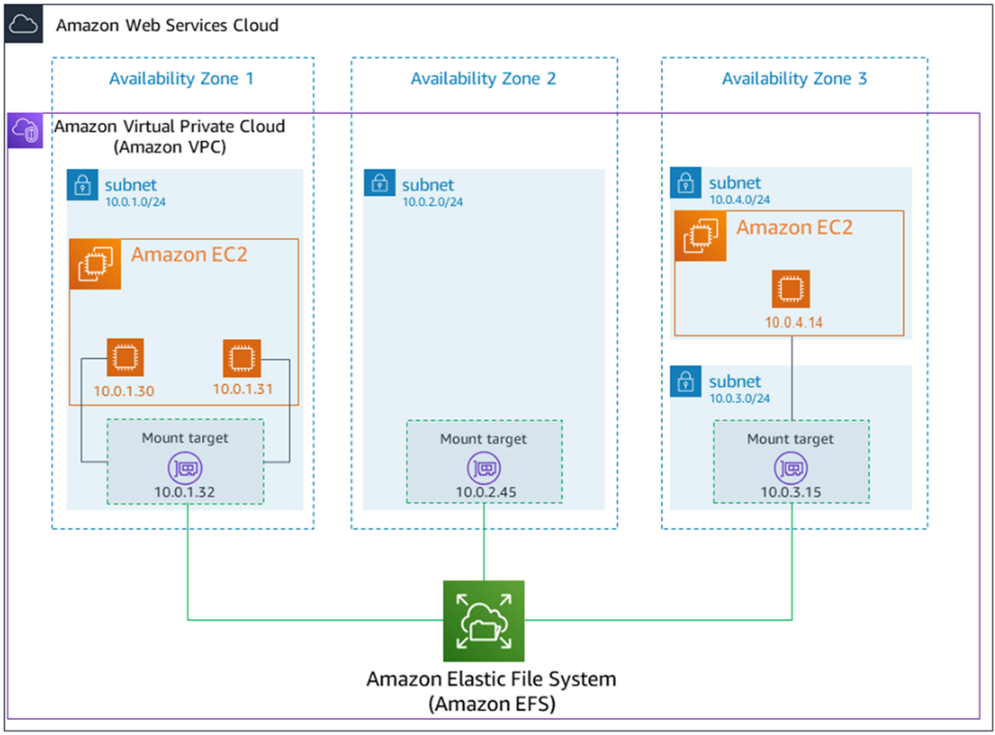
EFS 특징
EFS는 고성능 네트워크 파일 시스템으로, 여러 대의 컴퓨터가 네트워크상의 동일한 데이터에 접근해야 할 때 사용한다. NFS 표준 프로토콜 기반의 연결을 지원하고 있어 기존 다양한 애플리케이션과 유연하게 통합할 수 있고, 여러 컴퓨팅 인스턴스에서 동시에 사용할 수 있다. 또한 기존 NAS처럼 사용자 홈 디렉터리를 공유하여 애플리케이션을 개발하고, 테스트 환경의 다양한 웹 서비스와 콘텐츠 관리, 분석이나 미디어 업무에도 활용할 수 있다.
EFS 볼륨은 IOPS가 높고 용량이 매우 크기 때문에 처리량이 많고 대기 시간이 짧다. 또한 파일 시스템의 사용 증가에 따라 자동으로 용량 및 성능이 조정되는 탄력성을 제공하여 네트워크 스토리지의 용량 및 성능 부족을 걱정할 필요가 없다.
EFS는 EBS처럼 가용 영역 단위의 서비스가 아니라 가용 영역 전반에 걸쳐 사용할 수 있는 스토리지이므로, 가용 영역 장애를 고려한 디자인이 가능해서 전통적인 NAS보다 뛰어난 가용성을 가진다.
Amazon S3
S3 소개
Amazon S3는 AWS 서비스 중에서 EC2 서비스와 더불어 가장 오래되고, 기본이 되는 객체 스토리지 서비스이다. S3에 저장되는 데이터를 객체라고 하며, 이 객체 저장소를 버킷(bucket)이라고 한다. 그리고 객체에 대한 입출력은 HTTP 프로토콜로 하며, REST API를 이용하여 명령이 전달된다.
이 스토리지의 가장 큰 특징은 높은 내구성인데, 99.999%의 내구성으로 디자인되어 있어 데이터 손실을 최소화하도록 규정되어 있다. 또한 데이터 저장 공간이 거의 무제한에 가까워 특별한 용량 제한 없이 데이터를 저장할 수 있다. 필요한 경우 다양한 스토리지 계층으로 데이터를 분류하여 데이터 저장 비용을 절감할 수도 있다.
S3의 객체는 기본적으로 웹 접속이 가능하기 때문에 간단한 정적 웹 콘텐츠를 S3에 올려 웹 서버의 도움 없이 바로 웹 서비스가 가능하다. 그리고 S3는 보안 규정 준수 및 감시 기능을 제공하고 있어 데이터가 안전하게 저장되고 인증된 사용자만 접근할 수 있도록 구성한다. 필요한 경우 접근 권한 정책을 이용하여 해당 객체의 접근을 제어할 수 있다.

S3 구성 요소
- 버킷: 데이터 스토리지를 위한 S3의 기본 컨테이너이다. 객체는 반드시 버킷에 저장되어야 하며, 하나의 리전에서 생성된 후에는 버킷 이름과 리전을 변경할 수 없다.
- 객체: S3에 저장되는 기본 매체로, 객체 데이터와 객체 메타데이터로 구성되어 있다. 메타데이터는 객체를 설명하는 이름-값에 대한 하나의 쌍으로 존재한다. 객체를 저장할 때 사용자 정의 메타데이터를 지정할 수 있으며, 객체는 키(이름) 및 버전 ID를 이용하여 버킷내에서 고유하게 식별된다.
- 키: 버킷 내에서 객체의 고유한 식별자이다. 버킷 내 모든 객체는 고유한 하나의 키를 갖게 되며, S3는 '버킷 + 키 + 버전'과 객체 사이의 기본 데이터 맵으로 생각할 수 있다.
- S3 데이터 일관성: S3 버킷에 있는 객체에 대해 여러 서버로 데이터를 복제하여 고가용성 및 내구성을 구현하고 데이터 일관성 모델을 제공한다.
S3 특징
Amazon S3는 객체에 대해 빠르고 내구성과 가용성이 높은 키 기반의 접근성을 제공하여 데이터의 저장 및 검색에 특화된 객체 스토리지이다.
S3는 하나의 리전 내 최소 세 개 이상의 물리적으로 분리된 가용 영역에 데이터를 복제해서 저장하므로 높은 내구성과 고가용성을 제공하며, 서버의 OS 도움 없이 객체별 접근이 가능하므로 데이터 저장 및 활용에 용이하다.
또한 Amazon S3는 동일 버킷 내 여러 개의 객체 변형을 보유하여 데이터 복구에 특화된 객체 스토리지이다. S3에 버전 관리 기능을 이용하면 버킷에 저장된 모든 버전의 객체를 보존하거나 검색 및 복원할 수 있으며, 의도하지 않은 사용자 작업 및 애플리케이션 장애에서 쉽게 복구될 수 있다.
S3 스토리지 클래스
S3는 여러 사용 사례에 맞게 설계된 다양한 스토리지 클래스를 제공한다. 여기에는 자주 접근하는 데이터를 저장하는 S3 standard와 알 수 없거나 변화하는 접근 패턴이 있는 데이터를 저장하는 S3 intelligent-tiering, 데이터 수명은 길지만 자주 접근하지 않는 데이터를 저장하는 S3 standard-IA 및 S3 one zone-IA, 데이터 수명이 제한되어 추후 삭제 예정인 데이터 및 백업을 위한 S3 glacier 등이 있다. 데이터 수명 주기에 따라 데이터를 관리할 수도 있다.
[AWS S3 스토리지 클래스의 종류 및 특징]
- standard: 가장 일반적인 스토리지 클래스이며, 데이터를 검색할 때 요금 및 최소 사용량에 제한 없이 사용한 만큼 비용을 지불하면 된다.
- intelligent-tiering: 객체 접근 정보가 고정되어 있지 않을 때 자동으로 빈번한 접근 그룹과 간헐적 접근 그룹에 나누어서 저장한다.
- infrequent access: 객체가 자주 사용되지는 않지만 조회가 필요할 때 사용되는 데이터를 저장하는 클래스이다. 두 개의 하위 클래스로 나뉜다.
- standard-infrequent access: 최소 세 개 이상의 가용 영역에 데이터가 저장되기 때문에 내구성이 높은 클래스이다.
- one zone-infrequent access: 이름처럼 하나의 가용 영역에만 데이터가 저장되기 때문에 상대적으로 내구성이 낮고, 데이터가 삭제되어도 다시 생산할 수 있는 데이터를 위한 클래스이다.
- S3 glacier: 데이터 아카이브와 장기간 백업을 고려하여 만든 스토리지 클래스이다. 아카이빙 데이터는 오랫동안 데이터가 저장되어 있는 것을 의미하며, 이런 아카이빙 데이터에 접근하려면 많은 시간이 소요될 수 있다. 또한 데이터를 다른 클래스로 옮기려면 기가바이트당 비용이 발생하므로 주로 보관이 목적일 때 사용한다.
- S3 glacier deep archive: 재사용이 거의 없는 데이터를 보관할 때 사용하는 클래스이다. 일정 기간이 지나면 삭제할 데이터를 주로 보관하며, 조회하는 데 수 시간에서 수일이 소요될 수 있다. 그 대신 데이터 보관 비용이 가장 저렴하므로 데이터 목적에 따라 매우 유용한 저장소가 될 수 있다.
S3 보안
S3 버킷 접근은 일반적으로 버킷을 생성할 때 사용한 버킷 이름을 포함하여 생성된 유일한 식별자를 기반으로 언제, 어디에서든 접근이 가능하다. 그런 점에서 보안은 가장 중요한 부분이다. 그렇기 때문에 AWS의 자격 증명 서비스인 IAM(Identity and Access Management)과 밀접하게 연관되어 있고, IAM으로 접속 사용자나 데이터 접근을 관리할 수 있다. 특정 S3 버킷 접근에 대해 허용과 거부가 발생한다면 IAM에서 접근 권한을 통제하기 때문에 일어나는 상황이라고 이해하면 된다.
IAM으로 사용자 및 정책별 접근 권한을 제어할 수 있지만, 접근 권한이 있는 사용자가 개별 객체에 접근할 수 있게 하는 S3만의 버킷 정책으로 S3 버킷 내 모든 객체에 대한 권한을 조정할 수도 있다.
또한 쿼리를 요청할 때 쿼리 문자열을 인증하여 사용자 인증 정보도 함께 보낼 수 있는데, 해당 객체에 접근할 때 이 인증 정보로 일시적 허용 여부 권한을 이용할 수 있다. 대표적인 예가 임시 권한을 부여해서 접근하는 presign 기능이다.
다만 S3 객체는 기본적으로 외부 사용자가 접근할 수 없도록 설정되어 있다. 객체 소유자와 루트 사용자만 해당 객체에 접근할 수 있으며, 외부에서 접근하려면 별도의 정책을 이용하여 직접 설정해야 한다.

