
Reference
이 글은 다음을 참조하여 작성되었습니다. 감사합니다. 🙇🏻♂️
- @Transactional 옵션 명세
- 트랜잭션 공식
- GeeksForGeeks : transaction-management
- 스프링 공식 : transaction
- 스택오버플로의 누군가 : What will happen if I don't give @Transaction annotation on method?
- Don't use @Transactional in Tests
1. 트랜잭션의 원리는 뭔가요
Transactions in DBMS :
트랜잭션은 논리적 작업 집합을 수행하는 데 사용되는 일련의 작업이며
보통 데이터베이스의 데이터가 변경되었음을 의미한다.
DBMS의 주요 용도 중 하나는 시스템 오류로부터 사용자의 데이터를 보호하는 것이고
충돌 후 컴퓨터를 다시 시작할 때 모든 데이터가 일관된 상태로 복원되도록 함으로써 수행된다.
트랜잭션은 DBMS에서 사용자 프로그램의 실행 중 하나이다.
같은 프로그램을 여러 번 실행하면 여러 트랜잭션이 생성된다.
현금 거래 예시
일상에서 흔히 볼 수 있는 ATM 기기를 통하여
현금을 인출하기 위해 수행되는 거래의 예시를 통해 이해해보자.
ATM 거래 단계는 다음과 같다.
-
거래 시작
-
ATM 카드 삽입
-
거래 언어 선택
-
저축 계좌 옵션 선택
-
인출하고 싶은 금액 입력
-
비밀 PIN 번호 입력
-
처리 시간 대기
-
현금 회수
-
거래 완료
DBMS 관점에서 위 ATM 기기 거래를
다음과 같은 세 가지 작업 수행으로 요약할 수 있다는 것을 알 수 있다.
- 데이터 접근(Read/Access data (R))
- 데이터 조회/변경(Write/Change data (W))
- Commit
두 번째 예시.
각 계정 A= 500₩, B= 800₩이 있을 때,
A 계정에서 B 계정으로 50₩ 이체하는 상황.
이 데이터는 하드 디스크에서 RAM으로 가져온다.
R(A) -- 500 // Accessed from RAM.
A = A-50 // A에서 50₩ 공제
W(A)--450 // RAM에서 업데이트됨
R(B) -- 800 // RAM에서 접근
B=B+50 // 50₩이 B의 계정에 추가
W(B) --850 // RAM에서 업데이트됨
commit // RAM의 데이터가 하드 디스크로 다시 전송업데이트된 값
- 계정 A = 450₩
- 계정 B = 850₩
커밋 전의 모든 명령은 부분적으로 커밋된 상태이며 RAM에 저장된다.
-> 커밋을 읽으면 데이터가 완전히 받아들여지고 하드 디스크에 저장
커밋 전에 데이터가 실패하면 우리는 돌아가서 처음부터 시작해야 하며같은 상태에서 계속할 수 없다. 흔히 Roll Back이라고 알려져 있다.
Transaction Management의 유용성
Transaction 관리의 목적
DBMS는 데이터 접근을 동시에 관리하는데 사용된다.
그것은 사용자가 서로 간섭받지 않고 데이터베이스에서 여러 데이터에 접근할 수 있다는 것을 의미한다. 즉, Transaction 동시성을 관리하는 데 사용된다.
- 또한 ACID 특성을 만족시키는 데 사용된다.
- ACID(Atomicity, Consistency, Isolation, Durability) : 트랜잭션은 데이터베이스의 내용에 액세스하고 수정할 수 있는 단일 논리적 작업 단위이다. 트랜잭션은 읽기 및 쓰기 작업을 사용하여 데이터에 접근한다.
-
데이터베이스의 일관성을 유지하기 위해, 거래 전후에 특정 속성이 뒤따른다.
이것들은 ACID 속성이라고 불리며 read/write 충돌을 해결하는 데 사용된다. -
Recoverability, Serializability 및 Cascading을 구현하는 데 사용된다.
-
트랜잭션 관리는 동시성 제어 프로토콜과 데이터 잠금에도 사용된다.
Transaction States :
트랜잭션은 SQL 쿼리와 서버를 사용하여 구현할 수 있으며
아래 다이어그램에서 거래 상태가 어떻게 작동하는지 볼 수 있다고 한다.
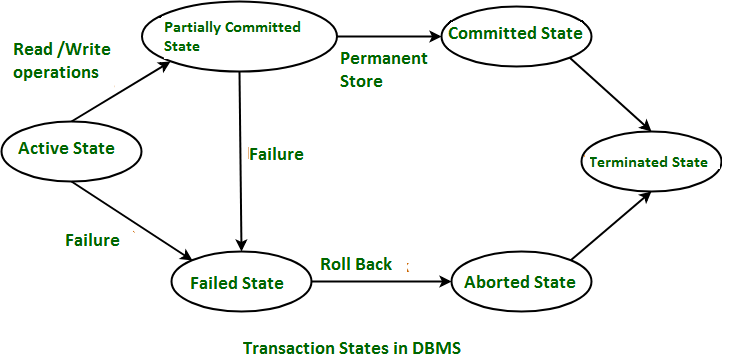
Transaction를 사용하는 것의 단점:
-
최종 사용자(end-users)가 트랜잭션 데이터베이스 내의 정보를 변경하는 것이 어려울 수 있다.
-
우리는 이전 상태에서 계속하기보다는 항상 롤백하고 처음부터 시작해야 한다.
2. JPA의 데이터 변경과 로직이 가급적 트랜잭션에서 처리되어야 한대요, 이유가 뭔가요?
16.1 Spring Framework 트랜잭션 관리 소개
포괄적인 트랜잭션 지원은 스프링 프레임워크를 사용하는 가장 강력한 이유 중 하나이다. 스프링 프레임워크는 다음과 같은 이점을 제공하는 트랜잭션 관리를 위한 일관된 추상화를 제공한다:
-
Java Transaction API(JTA), JDBC, Hibernate, Java Persistence API(JPA) 및 Java Data Objects(JDO)와 같은 다양한 트랜잭션 API에서 일관된 프로그래밍 모델.
-
선언적 거래 관리 지원
-
JTA와 같은 복잡한 트랜잭션 API보다 프로그래밍 방식의 트랜잭션 관리를 위한 더 간단한 API
-
스프링의 데이터 접근 추상화와의 우수한 통합
다음 섹션에서는 Spring Framework의 거래 가치 추가 및 기술에 대해 설명한다. (이 장에는 모범 사례, 애플리케이션 서버 통합 및 일반적인 문제에 대한 해결책에 대한 토론도 포함되어 있다.)
Spring Framework의 트랜잭션 지원 모델의 장점은 EJB 컨테이너 관리 트랜잭션(CMT) 대신 Spring Framework의 트랜잭션 추상화를 사용하거나 Hibernate와 같은 독점 API를 통해 로컬 트랜잭션을 유도하도록 선택하는 이유를 설명한다.
Spring Framework 트랜잭션 추상화를 이해하면 핵심 클래스를 설명하고 다양한 소스에서 DataSource 인스턴스를 구성하고 얻는 방법을 설명한다.
트랜잭션과 리소스를 동기화하면 애플리케이션 코드가 리소스가 올바르게 생성, 재사용 및 정리되도록 보장하는 방법을 설명한다.
선언적 거래 관리는 선언적 거래 관리에 대한 지원을 설명한다.
프로그래밍 방식 거래 관리는 프로그래밍 방식(즉, 명시적으로 코딩된) 트랜잭션 관리를 지원한다.
트랜잭션 바운드 이벤트는 트랜잭션 내에서 애플리케이션 이벤트를 사용하는 방법을 설명한다.
엄청 길다.. 천천히 읽어봐야겠다.
3. 트랜잭션을 사용하지 않으면 생기는 일
@Transactional 주석은 메서드에서 트랜잭션의 의미를 지정하는 메타데이터이다. 트랜잭션을 롤백하기 위해서 선언적 방식과 프로그래밍 방식 두가지를 사용할 수 있다. 메서드에 주석을 통해 트랜잭션을 선언해주는 형태를
선언적 접근 방식이라고 한다.
Spring transaction을 사용하면 다음과 같은 이점이 있다고 한다.
- 가벼운 구문을 선언할 수 있다.
- 코드가 단순해진다!
- 유연한 트랜잭션 전달
- 수동 트랜잭션 관리를 사용하면 트랜잭션 관리가 하드 코딩되어 있기 때문에 방법을 변경해야 하지만, 스프링과 함께, , transaction 전달이 원활하게 작동한다.
- 예외의 경우 자동 롤백
사용하지 않는 경우는?
@Transactional 코드 내에서 가져온 엔티티는 마지막에 자동으로 저장되므로 메서드를 명시적으로 호출하지 않더라도 아래 메소드의 테스트는 여전히 통과해야 한다.
코드의 여러 계층을 테스트하고 종종 느린 스프링 부트와 통합 테스트를 수행할 때, 테스트 실행 후 데이터가 정리되는 것을 보장되지 않는다.
-> 즉, 결정적 테스트 제품군을 보장되지 않으므로 @Transactional 주석을 사용하는 경향을 습관들일 필요가 있다!
물론 모든 테스트 방법에 주석을 트는 대신 @Transactional로 테스트 클래스에 주석을 달 수도 있다.
거짓 통과(테스트 중인 시스템(SUT)이 제대로 작동하지 않더라도 테스트가 통과하는 상황. 그러한 테스트는 거짓 음성 표시 또는 "거짓 통과"를 준다고 한다. )로 테스트 제품군을 망치는 것이 매우 쉽다는 사실을 경계해야 한다. 거짓 통과는 프로덕션 코드의 버그로 인해 실패해야 할 때 성공적으로 실행되는 테스트를 의미한다.
이것은 개발자들이 테스트 제품군에 대한 자신감이 줄어들고, 사람들은 무언가를 깨뜨릴 수 있기 때문에 변화를 두려워하기 시작할 것이라고 한다.
수동 테스트를 시작하지 않는 한 개발자가 알아차리지 못한 채 많은 버그가 생산되는 방향으로 갈 것이며, 이는 비생산적이다.
@Transactional을 제거한 후, 거짓 음성이 드러난다.
@Transactional은 트랜잭션 내에서 포함된 코드를 감싸는 것(wraps)으로 밝혀졌다고 한다. 이는 트랜잭션에 포함된 모든 코드에서 열린 데이터베이스 세션을 유지하며, 이는 컬렉션의 성공적인 지연 로딩에 필요함을 의미한다.
JPA/Hibernate에서 컬렉션을 처리하는 권장되는 방법은 컬렉션을 lazy 상태에서 수동으로 가져오고, 필요한 것만 가져오고, N-M 성능 문제를 피하는 것이라고 한다. 간단히 말해서,
fetch = FetchType.EAGER -> fetch = FetchType.LAZY로 전환해야 한다!
4. 추가 개념
- 클래스, 인터페이스, 메소드에 사용할 수 있으며, 메소드에 가장 가까운 애노테이션이 우선 순위가 높다 .
- 기본적으로 @Transactional(readOnly=true)는 아무런 @Transactional 설정을 하지 않은 메서드에 적용된다고 한다.
- timeout을 설정해줄 수 있음
- @Transactonal이 사용할 transactionManager을 설정해줄 수도 있는데 기본적으로 JpaTransactionManager을 사용하게 될 것임
- transactionManager 여러개 설정하지 않는 이상 건드릴 필요가 없는 설정
스프링 부트를 사용하면서 하나만 사용해야되는 경우엔 스프링 부트 자동설정한 빈 네임이 자동으로 설정된 transactionManager로 자동으로 설정됨 - transactionManager의 기본 값이 transactionManager
- transactionManager로 참조할 빈의 이름을 transactionManager 로 설정해주기 때문에 별다른 설정을 하지 않아도 됨
readOnly
해당 트랜잭션이 readOnly 인지 나타내는 flag 이 값을 주면서 Optimization 성능 최적화를 해줄 수 있는 여지가 생김
가급적이면 데이터를 변경하는 Operation이 없으면 readOnly를 true로 주는 것이 좋음
Rollback
- RuntimeException 이나 Error가 발생하면 해당 트랜잭션을 Rollback 시킴
- checked exception이 발생하면 Rollback 하지 않음
추가적으로 checked exception이 발생해도 Rollback이 되게 하려면 - rollbackFor , rollbackForClassName 에 설정해주면 됨
- RuntimeException 이 발생하면 Rollback을 안하려면
noRollbackFor, noRollbackForClassName 에 설정해주면 됨
Isolation
트랜잭션이 여러개가 동시에 데이터베이스에 접근했을 때 해당 트랜잭션들을 어떻게 처리할 것인지, 동시에 실행되게 할 것인지 하나 하나씩 차례대로 데이터에 접근하게 할 것인지
이런 제어에 대한 설정인데 어떠한 레벨로 주느냐에 따라 데이터에 동시에 접근했을때 발생할 수 있는 현상이 달라진다고 한다.
- non-repeatable reads(다시 조회했는데 똑같은 값이 안나오는 것), dirty reads(트랜잭션이 아직 쓰지 않은 데이터를 읽는 것),
phantom reads(값이 있었는데 없어지는 것)
그런 현상들이 발생할 여지가 있고 어떤건 다막을 수있는데 다 막을 수록 성능이 안좋아진다
DEFAULT
기본값은 데이터베이스의 기본값을 따름
- H2는 기본값: Read Committed
- PostgreSQL 기본값: Read Committed
- 보통 기본값이 Read Committed
READ_COMMITTED
- 트랜잭션에서 데이터를 쓰고 있어도 다른 트랜잭션에서 그 데이터를 안 읽어감.
- phantom reads(없는 데이터를 읽는 현상)는 발생할 수 있는데
dirty reads(트랜잭션이 아직 쓰지 않은 데이터를 읽는 것) 를 방지할 수 있음. - READ_UNCOMMITTED 다음으로 성능이 좋음
READ_UNCOMMITTED
성능이 가장 좋지만 Commit 안될 데이터까지 읽어갈 여지가 생김
- 한 트랜잭션에서 데이터를 넣고 있는데 데이터가 사라질지 안사라질지는 트랜잭션이 끝나봐야 아는건데, 다른 트랜잭션에서 사라질 데이터까지 읽어갈 여지가 생김
REPEATABLE_READ
- READ_COMMITTED 다음으로 성능이 좋음
- dirty reads, non-repeatable 를 방지함, phantom reads는 발생할 수 있음
SERIALIZABLE - dirty reads, non-repeatable, phantom reads 다 막지만 성능이 가장 안좋음
- 데이터베이스에 동시접근할 수 있는 트랜잭션이 하나 뿐임
Propagation
트랜잭션으로 시작한 메서드에서 다른 트랜잭션을 가진 메서드를 호출하면
첫번째 메서드의 트랜잭션을 이어갈 것인가 두번째 메서드는 새로운 트랜잭션을 만들어서 처리할 것인가.. 이런 것에 대한 설정
- MANDATORY, NESTED, NEVER, NOT_SUPPORTED, REQUIRED, REQUIRES_NEW, SUPPORTS의 옵션이 있음
NEVER
트랜잭션으로 처리하지 않음
JPA 구현체로 Hibernate를 사용할 때 트랜잭션을 readOnly를 사용하면 좋은 점
- Flush 모드: 언제 데이터베이스에 sync를 할 것인가 기본값은 적절한 타이밍에 되게 되어있음
- 보통 commit 할때 데이터를 read 해오기 전에 flush 하게 되어 있음
- Flush 모드를 NEVER로 설정(Flush를 안함)하여, Dirty checking을 하지 않도록 한다.
- 데이터 변경이 일어나지 않을 트랜잭션이기 때문에 Flush를 하지 않아서 데이터 베이스 동기화를 하지 않음.
- 데이터를 많이 가져오는 경우에 Dirty checking 를 꺼주면 성능이 향상됨
