이번에는 가장 강력한 고립화 레벨인 Serializable 레벨을 보겠다.
마찬가지로 동일한 출발점에서 시작한다.

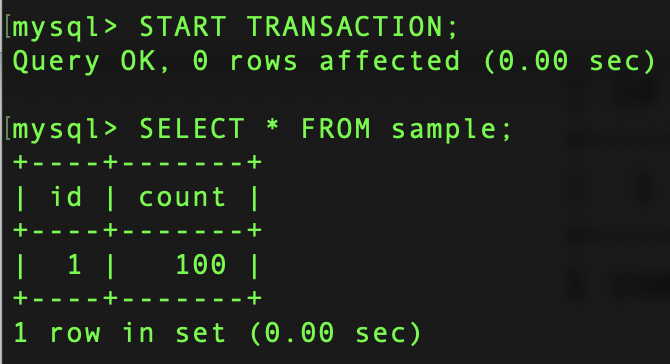
잠깐 count 값을 100에서 200으로 수정해보자.
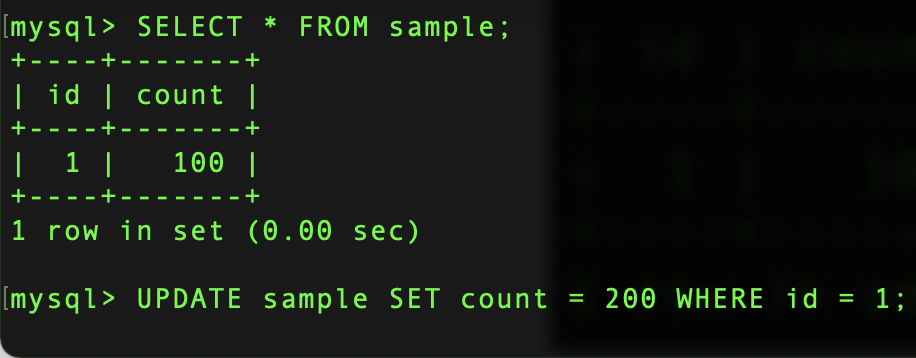
어? 그런데 Hang이 걸린다. 멈췄다는 뜻.. 왜 그런 걸까? 그건 바로 T1에서 실행한
SELECT * FROM sample;때문이다. SERIALIZABLE 레벨은 가장 강력한 고립화 레벨로 REPEATABLE READ 레벨과 비슷하지만 한 가지 특성이 더 있다. 그건 바로 모든 SELECT 문을 SELECT ... FOR SHARE 문으로 바꾸어 실행한다는 점이다. 그리고 SELECT ... FOR SHARE는 Locking READS 중의 하나인데 이것은 읽혀지는 row들에 shared lock을 걸고 SELECT를 하는데 이렇게 되면 다른 트랜잭션에서 해당 row들에 exclusive lock를 걸지 못하게 되기 때문에 해당 row에 관한 UPDATE, DELETE 등의 작업을 하지 못하게 된다.
그래서 방금 이미 T1에서 실행했던 SELECT가 SELECT ... FOR SHARE로 바뀌어 실행되어서 전체 row에 대한 shared lock이 걸린 상태였고, 이런 상태에서 T1이 UPDATE 작업을 위해 row에 대한 exclusive lock(추정) 을 걸려고 해서 실패한 것이다.
조금 시간이 지나면 곧

Lock wait timeout exceeded : ~ 라는 문구가 출력되고, 락을 획득하기 위해 기다리다가 포기했음을 알 수 있다.
새로운 row를 추가하기 위해 INSERT 문을 실행해도 역시 마찬가지로 실행되지 않는다.

그런데 여기서 신기한 현상을 보여주자면 이렇게 hang이 걸린 상태에서 T1에서 COMMIT을 해주면,
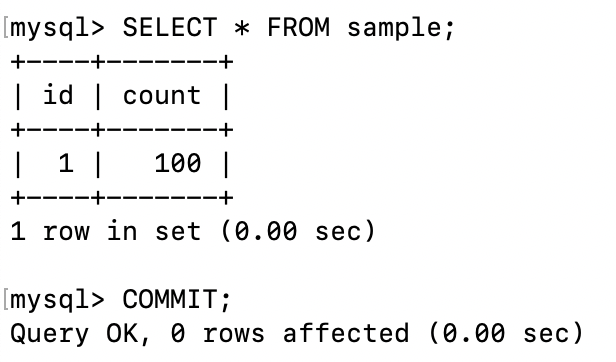
T2의 INSERT 문의 hang이 풀리고 바로 잘 실행된다.

T1의 COMMIT과 동시에 shared lock이 풀려서, T2의 작업이 가능해졌기 때문이다. 자, 이번엔 작업 순서를 반대로 해보자. 자, 새로운 T1을 시작해보자.

어? 그런데 이번에는 T1의 SELECT 문에서 hang이 걸린다. 왜 그럴까? 그건 바로 SELECT ... FOR SHARE 문은 다른 트랜잭션이 완벽하게 커밋되기까지 기다렸다가 작업을 수행하기 때문이다.

T2를 커밋해주면
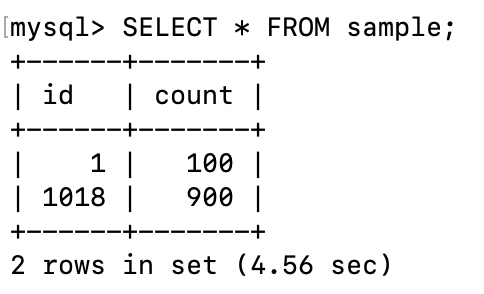
SELECT 문이 잘 실행됩니다.
이렇듯 SERIALIZABLE 레벨은 모든 작업이 각 트랜잭션이 순서대로 하나씩 순차 수행될 수 있도록 해주는 가장 완벽한 고립화 레벨입니다. 두 트랜잭션에서 둘다 SELECT를 하는 경우를 제외하고는 먼저 lock을 획득한 쪽이 트랜잭션을 다 마친 후, 그 다음 다른 트랜잭션이 수행될 수 있기 때문에 신뢰성이 중요한 비지니스 환경에서는 SERIALIZALBE 레벨을 사용해야 합니다.
