https://school.programmers.co.kr/learn/courses/30/lessons/92343
이진트리에 양과 늑대가 있고 탐색하면서 양과 늑대를 줍는데, 양의 수가 늑대를 항상 초과하게 주울 때 양을 최대 몇 마리 주울 수 있는지 구하는 문제이다.
Python
시도 1 - 실패
def solution(info, edges):
answer = [0]
adj = [[] for _ in range(len(info))]
for a, b in edges:
adj[a].append(b)
# adj[b].append(a)
dfs(0, adj, info, 1, 0, answer, [])
return answer[0]
def dfs(start, adj, info, sheep, wolves, answer, track):
if wolves >= sheep:
return -1
answer[0] = max(answer[0], sheep)
search = set(adj[start] + list(track))
visited = set()
while search:
next = search.pop()
chk = dfs(next, adj, info, sheep + abs(info[next] - 1), wolves + info[next], answer, search)
if chk == -1 and next not in visited:
search.add(next)
visited.add(next)먼저 단방향 인접 리스트를 만들고 dfs 함수를 만들었다.
dfs에서는 지금 주운 양과 늑대의 수를 비교하고 늑대가 양보다 크거나 같다면 -1을 반환하도록 했다.
그렇지 않다면 지금까지 주운 양과 answer를 비교해서 최대값을 업데이트 해주었다.
dfs의 파라미터로 track을 두었는데 이는 상위 노드에서 탐색하지 않았거나 늑대가 "그때 당시에는" 더 많아서 탐색에 실패한 노드를 저장하는 곳이다. 그래서 현재 노드와 연결된 곳 모두 탐색하고 상위 노드에서 탐색하지 않은 곳을 다시 가도록 하기 위해 track을 두었다. 그리고 search라는 집합에 인접노드와 미탐색 노드를 같이 저장하였다.
또한 한 번 실패한 노드는 재방문하고 또 방문하는 경우를 막기 위해서 visited를 두었고, 재방문에도 실패해서 chk가 -1이 나올 경우 visited에 next가 없을 때에만 search에 다시 추가하도록 했다.
그리고 실패했다. 정확성 72.2점이 나왔다.
시도 2
def solution(info, edges):
answer = [0]
adj = [[] for _ in range(len(info))]
for a, b in edges:
adj[a].append(b)
dfs(0, adj, info, 1, 0, answer, [])
return answer[0]
def dfs(start, adj, info, sheep, wolves, answer, track):
if wolves >= sheep:
return -1
answer[0] = max(answer[0], sheep)
search = adj[start] + track
visited = set()
while search:
next = search.pop()
chk = dfs(next, adj, info, sheep + abs(info[next] - 1), wolves + info[next], answer, search)
if chk == -1 and next not in search and next not in visited:
search.append(next)
visited.add(next)
search = adj[start] + track
visited = set()
while search:
next = search.pop(0)
chk = dfs(next, adj, info, sheep + abs(info[next] - 1), wolves + info[next], answer, search)
if chk == -1 and next not in search and next not in visited:
search.append(next)
visited.add(next)질문하기에서 주운
입력값 [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0], [[0, 1], [1, 2], [2, 3], [3, 4], [4, 5], [5, 6], [6, 7], [7, 8], [4, 9], [9, 10], [10, 11], [8, 12], [12, 13], [13, 14], [14, 15], [15, 16]]
기댓값 11
케이스에 대해서 그림을 그리면
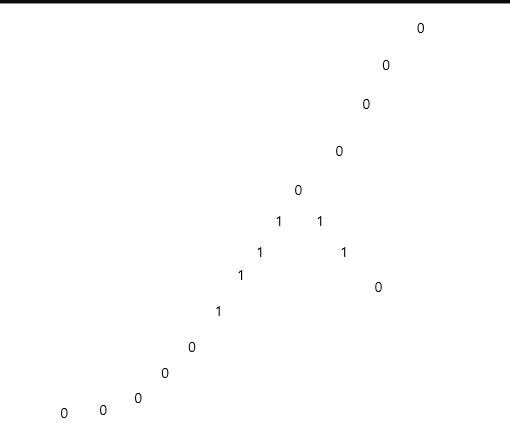
이런 모양이 나와서 자식이 두 개인 노드에 대해서 왼쪽 먼저 탐색하는 경우와 오른쪽 먼저 탐색하는 경우 두 가지를 모두 찾아봐야했다.
하지만 set은 순서가 없어서 항상 같은 방향으로만 탐색이 되어서 list로 변경하고, 노드의 개수가 최대 17이기에 next in search를 매번 호출해도 부담이 없어서 해당 조건을 주었더니 통과할 수 있었다.
