Pipelining
작업에서 동시에 수행할 수 있는 부분을 병렬적으로 수행함으로써 총 실행 시간을 줄이는 기법이다. 총 다섯 개의 스테이지가 있다.
- IF : 메모리 상의 명령어에 접근(instruction fetch)
- ID : 메모리 해석(instruction decode)
- EX : 명령어 수행(execute operation)
- MEM : 메모리 오퍼랜드 접근(access memory)
- WB : 결과 레지스터에 저장(write back)
여러 개의 프로세스가 위의 작업을 거친다고 할 때, A프로세스가 IF를 수행하고 이어서 ID를 수행하는 동안 B프로세스가 IF를 수행하는 것을 파이프라이닝 이라고 한다.
모든 stage의 시간을 균등하게 나눌 수 있다면 instruction이 아주 많다고 가정할 때, 파이프라인을 적용한 이후의 실행시간은 전체 실행시간/스테이지 개수 이다.
하지만 실제로는 stage끼리 시간 배분이 다르기 때문에 정확히 n배로 빨라지지는 않는다.
만약 IF가 200ps 걸리고 전체 명령어는 800ps 걸린다고 해보자.
파이프라인 없이는 5개의 명령어를 수행하는 데 4000ps가 걸릴 것이다.
하지만 파이프라인을 도입하면 첫 번째 명령어의 IF가 끝나자마자 두 번째 명령어를 시작할 수 있다.
따라서 5개의 명령어를 수행하는 데 200ps*4 + 800ps, 즉 1600ps가 걸린다.
파이프라인을 쓰면 실행시간이 적게 드나?
그렇지 않다. 시간당 처리되는 명령어 개수(throughput)가 늘어나는 것이지, instruction fetch 때문에 오히려 하나의 명령어 당 수행 시간은 늘어날 수도 있다.
clock cycle time 구하기
-
single cycle 프로세서인 경우
가장 긴 명령어를 기준으로 구한다.
보통 load가 제일 오래 걸리는데, 5개 스테이지 모두 load를 활용하므로 전체 스테이지 시간의 총합을 구하면 된다. -
pipeline을 적용한 프로세스인 경우
1사이클 시간을 정할 때 가장 시간이 오래 걸리는 스테이지를 기준으로 한다.
pipeline registers
데이터패스에서 스테이지 별로 한 사이클을 취하고, 사이클 사이사이에 데이터를 전달해줄 필요가 있는데 이 때 레지스터를 사용한다.
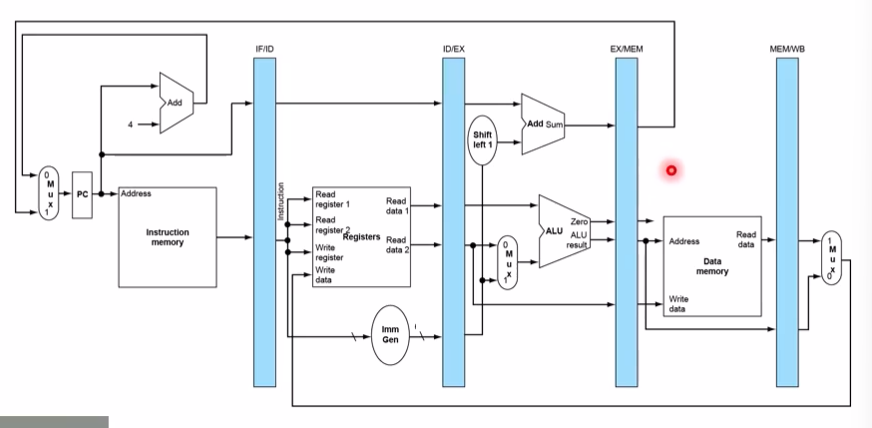
Hazard
파이프라인의 hazard란?
파이프라인으로 프로세스 구현 시 다음 사이클의 다음 명령어를 시작하는 데 있어서 방해가 되는 상황을 말한다.
Structual hazards
리소스가 부족해서 발행하는 해저드이다.
여러 개의 리소스가 제한된 하드웨어를 사용하려고 할 때 문제가 발생한다.
해결 방법은 하드웨어를 여러 개 만드는 것이다. 혹은 멀티플렉서 등을 이용해서 입력값마다 가능한 분기를 나눠주는 방법도 있다.
Data hazards
명령어를 수행하려고 하는데 필요한 데이터가 없을 때 발생하는 해저드이다.
예를 들어 add명령어와 sub명령어가 연달아 있는 데, add 명령어의 rd를 sub 명령어에서 오퍼랜드로 사용하는 경우 아직 write back이 완료되지 않은 상황에 레지스터를 참조하면 해저드가 발생한다.
그러면 레지스터가 로드되는 동안 기다리기 위해 bubble 명령어를 넣어야 하는데, 이 동안 하드웨어가 쉬기 때문에 효율이 떨어진다.
해결 방법은 EX에서 처리된 연산 결과를 곧바로 다음 EX로 전달하는 것이다. 이것을 forwarding 이라고 한다.
Forwarding(또는 bypassing)
이전 명령어의 EX의 산출값을 다음 명령어의 EX의 입력값으로 곧바로 넣어주는 것을 말한다.
데이터패스에 새로운 connection을 만들어줘야 한다는 단점이 있다. 하지만 수행시간을 늘리지 않고 data hazard를 해결할 수 있다.
Forwarding의 종류
데이터를 전송하는 시점에 따라 입력 신호가 달라진다.
- EX/MEM 과 ID/EX 가 일치 - ex hazard
- MEM/WB과 ID/EX가 일치 - data hazard
Forwarding unit
forwardA, forwardB 신호를 만드는 유닛이다. 이를 통해 mux를 선택하여 ALU unit이 레지스터 값을 어디서 받아올지 정할 수 있다.
ex hazard - 10
data hazard - 01
해저드 발생하지 않음 - 00
Load-Use data hazard
lw등 메모리에 접근하는 명령어를 사용하는 경우 MEM stage에서 데이터를 불러온다. 이 때 forwarding을 해봤자 다음 사이클에서 EX에 필요한 데이터를 전달해줄 수는 없다. 이전 명령어의 MEM과 다음 명령어의 EX가 동시에 발생하기 때문이다.
이것을 Load-Use hazard 라고 부른다.
코드 스케줄링 바꾸기
순서를 바꾸어도 영향을 주지 않는 명령어를 움직여서 버블이 들어갈 자리에 넣어주는 방식으로 해저드를 해결할 수 있다.
code reordering 이라고 부르며, 하드웨어 코스트 없이 stall을 줄일 수 있다.
Control hazard
명령어의 컨트롤 신호가 유실되어 수행하지 못하는 상황이다. 데이터패스의 구조 상 원하는 브랜치가 뒤에 위치해있으면 명령어를 처리할 수 없는 경우가 생긴다.
예를 들어 브랜치 명령을 수행할 때 기존 PC값 + 브랜치 연산 결과 오프셋을 다음 명령어로 전달해주는데, 브랜치 연산이 MEM 스테이지에 있기 때문에 다음 명령어에 전달하기까지 시간이 오래 걸린다. 이 경우 브랜치 연산값이 없어서 control hazard 이다.
Branch prediction
브랜치 결과를 빠르게 가져오는 것에 한계가 있다. 그래서 브랜치 연산 결과를 예상해서 다음 행동을 정하는 방식이 등장하였다.
branch prediction 이란 브랜치의 결과를 예측해서 다음 명령어를 수행하는 것을 말한다. 이 경우 예상이 틀릴 수도 있는데, 이 때 가져온 데이터를 버리고 새로 시작한다.
Static prediction
평균적인 브랜치의 행동에 따라 다음 결과를 예측하는 방법이다. 예를 들어 루프문이라면 높은 확률로 비슷한 브랜치의 명령어가 반복될 것이라고 예측할 수 있다.
Dynamic prediction
그때그때 달라지는 브랜치 활동 기록에 따라 예측을 바꾸는 방법이다.
ex) 지난번에 일어났고 그 전에도 일어났으니까 다음 번에도 일어날 것이다.
Data hazard를 해결하는 하드웨어
모든 데이터 해저드를 개발자가 직접 해결할 수 없으므로 어느 정도는 하드웨어에서 자동으로 처리하게 되는데, 이 과정을 알아보자.
이전 / 이후 명령어라고 가정할 때
- EX/MEM의 rd = ID/EX의 rs1
- EX/MEM의 rd = ID/EX의 rs2
- MEM/WB의 rd = ID/EX의 rs1
- MEM/WB의 rd = ID/EX의 rs2
위의 네 가지 조건 중 하나를 만족할 경우 하드웨어는 data hazard가 일어날 수 있다고 판단한다.
ForwardA, ForwardB
EX 스테이지에서 받을 수 있는 입력값의 종류는 3가지이다.
- 지난 명령어의 EX결과
- 지난 명령어의 MEM stage 결과
- 그냥 레지스터에서 가져오는 경우
따라서 3:1 멀티플렉서를 사용하는데, 이 때 멀티플렉서에서 쓸 select 신호가 필요하다.
이 신호를 rs1의 경우 forwardA, rs2의 경우 forwardB 라고 부른다.
두 신호를 만드는 유닛을 forwarding unit 이라고 부른다.
forwarding unit
포워딩을 하드웨어가 자동으로 하기 위해 설치한 유닛이다.
데이터 해저드의 발생 여부를 알기 위해 이전/이후 명령어에서 사용하는 레지스터 번호를 입력받아 forward 신호를 결정한다.
위에서 설명한 3가지 입력값마다 해당 신호를 전송한다.
- 지난 명령어의 EX결과 : 10
- 지난 명령어의 MEM stage 결과 : 01
- 그냥 레지스터에서 가져오는 경우 : 00
아래는 forwardA 값을 만드는 유닛의 코드 예시이다.

이전 명령어의 rd를 다음 명령어의 rs1과 비교하는 것을 확인할 수 있다.
Double data hazard
특정 명령어에 ex hazard, mem hazard가 동시에 발생할 수 있다.
이 경우 ex hazard를 우선시한다.
Load-use stall
load-use 때문에 stall이 발생하면 MEM 스테이지 접근에 걸리는 시간이 필요하기 때문에 기존 명령어를 bubble로 만들고 다음 사이클에서 다시 수행한다.
Reducing branch delay
브랜치 연산을 앞당겨서 control hazard 발생 시 딜레이를 줄이는 방법이다.
- 브랜치 주소 연산을 ID 스테이지로 옮긴다.
- 레지스터 비교(뺄셈 연산)를 ID스테이지로 옮긴다.
즉, 브랜치 비교 연산을 ID스테이지에서 수행하는 것이다.
이렇게 구성해도 1개의 stall이 남지만 branch prediction을 통해 딜레이를 더 줄일 수 있다.
