Dependability
제품의 서비스가 중단된 경우 복구해서 정상화하는 과정에 대해 알아보자.
용어
MTTF : mean time to failure, 고장나는 데 걸리는 평균 시간
MTTR : mean time to repair, 고치는 데 걸리는 평균 시간
MTBF : mean time between failures, 고장나고 고치는 시간을 더한 값
디스크의 MTTF
만약 고장나는 데 백만 시간이 걸리는 디스크가 있다면, 하루 동안 5만 개의 서버를 구동할 때 하루에 몇 개의 디스크가 고장나는가?
24h * 50,000 servers / 1,000,000 MTTF = 1.2HDDs/day
여기에서 확인할 수 있는 점은 개별 하드 디스크의 MTTF가 길다고 하더라도 장치를 여러 개 사용하면 고장이 증가한다는 점이다. 따라서 장치의 MTTF를 줄이는 것이 중요하다.
Hamming SEC Code
메모리에 문제가 생겼을 때 수복하기 위해서 Error Correction Code(ECC)를 사용한다.
SEC는 Single-bit Error Correction의 약자이다.
이를 이해하려면 Hamming distance 에 대해 알아야 한다.
Hamming distance란?
두 개의 비트 패턴 사이에서 일치하지 않는 비트가 몇 개인지를 따져보는 것이다.
출처 : http://alanclements.org/hammingcodes.html
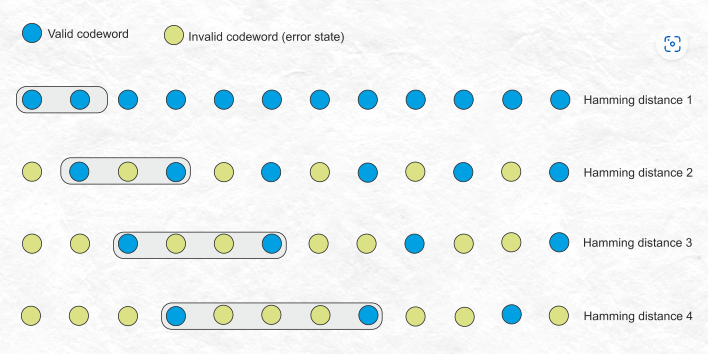
hamming distance가 멀다 = valid한 코드 사이의 거리가 멀다
거리가 4인 경우 1비트 error correction, 2비트 error detection이 가능하다.
이렇게 거리가 계속 멀어지는 경우 check bit라는 것이 필요하다.
예를 들어 ECC DRAM에서는 64비트 데이터에 추가로 체크 비트 8비트를 함께 쓴다.
I/O 성능 개선
큰 디스크를 사용하기보다 여러 개의 작은 디스크를 사용하면 성능을 개선할 수 있을 것이라는 아이디어가 있다. 하지만 이 경우 디스크가 고장날 확률이 증가하게 된다.
따라서 여러 개의 디스크를 리스크 없이 사용하려면 데이터를 중복해서 저장해야 한다.
RAID
redundant arrays of inexpensive disks의 줄임말이다.
- RAID 0
중복 데이터가 없는 상태이다. 성능은 좋지만 디스크가 고장날 시 데이터를 잃는다. - RAID 1
두 개의 디스크에 같은 데이터를 작성하는Mirroring을 수행한다. 디스크가 두 개로 필요하기 때문에 가격이 비싸다. - RAID 3/4
RAID 3/4는 데이터를 체크하는 패리티 디스크를 추가해서 디스크 고장 시 해당 데이터를 복구한다. 3은 bit level, 4는 block level 패리티를 쓴다.
단점은 데이터를 작성할 때마다 패리티를 수정해야 한다는 점이다. - RAID 5
분산 패리티로 데이터를 저장하는 디스크에 패리티를 조금씩 나눠서 저장한다. - RAID 6
분산 패리티를 이중으로 활용한다. 2개의 오류도 잡아낼 수 있지만 RAID 5에 비해 패리티 오버헤드가 증가한다.
SSD와 HDD는 특성이 달라 혼합 RAID를 구성할 수 없다.
메모리 계층 구조
모든 레벨의 메모리 계층 구조에서 유사한 원칙을 적용하고 있다.
Block placement
DRAM에 블록을 배치하는 방법은 associativity 를 기준으로 정한다.
- Direct mapped (1-way associative)
블록을 캐시 블록의 크기 모듈 안에 넣는다. 한 가지 방법 뿐이다. - n-way set associative
세트 안에서 n개의 선택지를 가진다. - fully associative
아무 위치에나 블록을 배치할 수 있다.
Finding a block
블록을 찾을 때도 associativity 를 따른다.
- Direct mapped
인덱스를 기준으로 찾는다. tag comparison은 한 번만 하면 된다. - n-way set associative
set의 인덱스 안에서 n개의 엔트리를 상대로 tag comparison을 진행한다. - fully associative
모든 공간을 대상으로 태그를 비교한다. 엔트리 개수가 작은 장치에서 활용할 수 있다.
이 때 페이지 테이블을 lookup 용도로 활용하면 탐색 시간을 줄일 수 있다.
L1 -> L2 -> page -> TLB 순서로 크기도 크고 associativity도 커진다.
DRAM page와 TLB 배치의 탐색 차이점
page의 경우 page table을 사용하기 때문에 탐색 속도가 빠르다.
하지만 page table 자체가 오버헤드 요인이 될 수도 있다.
Replacement
하위 메모리에서 데이터를 가져올 때 상위 메모리에서 어떤 것을 내보낼지 알고리즘을 정한다.
- LRU(least recently used)
associativity가 클수록 덜 사용한 데이터를 고르는 행위 자체가 부담이 된다. - Random
디스크 크기가 클 때는 랜덤으로 구현하는 것이 간편한 경우도 있다. - 가상 메모리
레퍼런스 비트를 기반으로 한 LRU를 수행한다.
Write policy
- Write-through
상위, 하위 레벨을 모두 업데이트한다.
replacement가 간편하지만 write buffer가 필요하다. - Write-back
상위 레벨만 업데이트한다. 하위 레벨은 블록이 replace되었을 때 업데이트한다. - Virtual memory
비용 상 write-back만 사용해야 한다.
