Data Encryption Standard
DES란?
암호화에 표준으로 쓰이는 알고리즘을 말한다.
- 56-bit 길이의 대칭 키를 가진다.
- 64-bit 길이의 block을 가진다.
- 16라운드로 구성되어있다.
block cipher
비트를 block단위로 나뉘어서 암호화하는 방법을 block cipher라고 한다.
Confusion과 Diffusion
confusion: 키와 사이퍼텍스트 사이의 관계를 숨긴다. substitution으로 구현한다.
diffusion: 평문과 사이퍼텍스트 사이의 관계를 숨긴다. permutation으로 구현한다.
Product Cipher는 여러 단계의 라운드로 구성되어있고 각 라운드는 반복되는 substitution과 permutation으로 이루어져있다.
substitution, permutation
substitution은 기존의 값을 다른 값으로 치환하는 것이고, permutation은 순서를 바꿔서 암호화 규칙을 섞는 것이다.
product cipher
사이퍼텍스트를 만들기 위해서는 여러 번의 라운드를 반복해야 한다. DES에서는 16회로 정해져있다.
각 라운드 안에서는 subtitution과 permutation이 이뤄지며 이러한 과정을 cipher(암호문)를 생성한다고 한다.
DES Structure
- 56-bit cipher key를 입력받는다.
- 여러 개의 subkey(48-bit)를 만들어서 각 라운드마다 하나씩 할당한다.
- 총 16라운드 진행한다.
- 라운드를 돌리기 전후로 initial/final permutation을 수행한다(별로 도움이 되지는 않는다고 한다).
Feistel Cipher
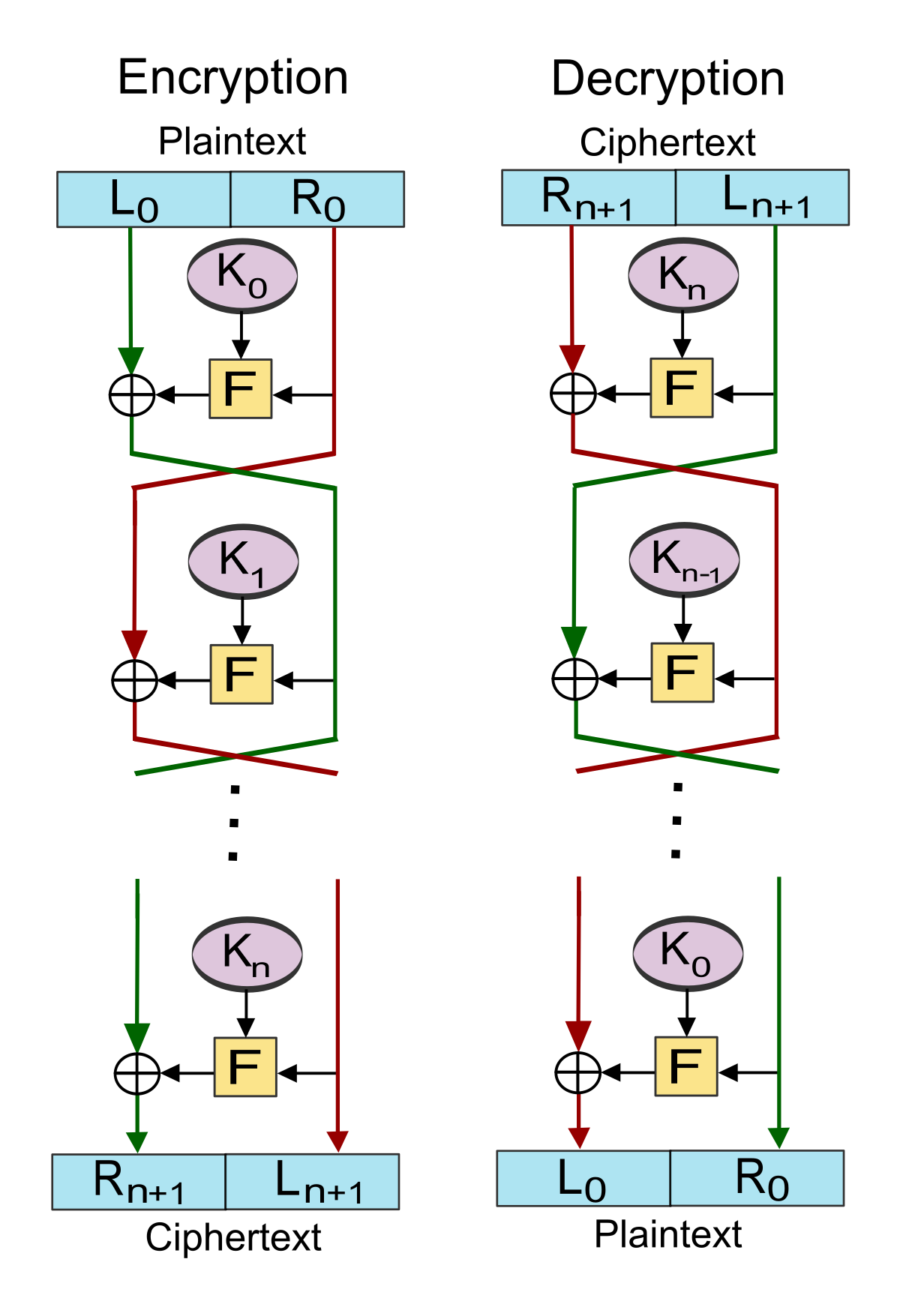
DES에서는 64비트 입력을 32비트씩 두 단위로 잘라서 서로 교차하며 암호화한다. 이렇게 구현하면 decryption을 안전하고 효율적으로 수행할 수 있다.
먼저 입력값을 L과 R로 나누고, 그 중 R값은 F함수(라운드 함수라고도 부른다)에 넘겨준다.
이 때 subkey인 K(48-bit)를 이용한다.
subkey가 48-bit인 이유
원래 키는 56비트지만, 같은 키를 계속 사용하면 안전하지 못하기 때문에 입력값 56비트로부터 48비트의 subkey를 만들어 각 라운드마다 하나씩 쓴다.
이후 R0은 별다른 과정을 거치지 않고 다음 라운드의 L1이 된다.
L의 경우, K와 R0를 F함수에 넣어 나온 산출값과 XOR을 수행한 후 R1이 된다.
❗ 마지막 라운드에서는 교차하지 않는다.
Encryption & Decryption
F함수에 K1, K2를 순서대로 넣을 시
L'0 = L2 = L1 XOR F(K2, R1)
R2 = L0 XOR F(K1, R2)
R'0 = R2 = R1
F함수에 K2, K1을 역순으로 넣을 시
L'1 = R'0
R'1 = L'0 XOR F(K2, R'0) = L1
이유 : L'0 = L1 XOR F(K2, R1) 인데 R'0=R1이므로 XOR에서 같은 걸로 사라짐
L1 = R0이므로 R'2 = R'1 = R0
결론 : Feistel Cipher에서 F함수에 키를 역순으로 넣으면 decryption된다.
F함수는 invertable하지 않지만, feistel network 전체적으로 보면 invertable한 알고리즘이다.
Permutation
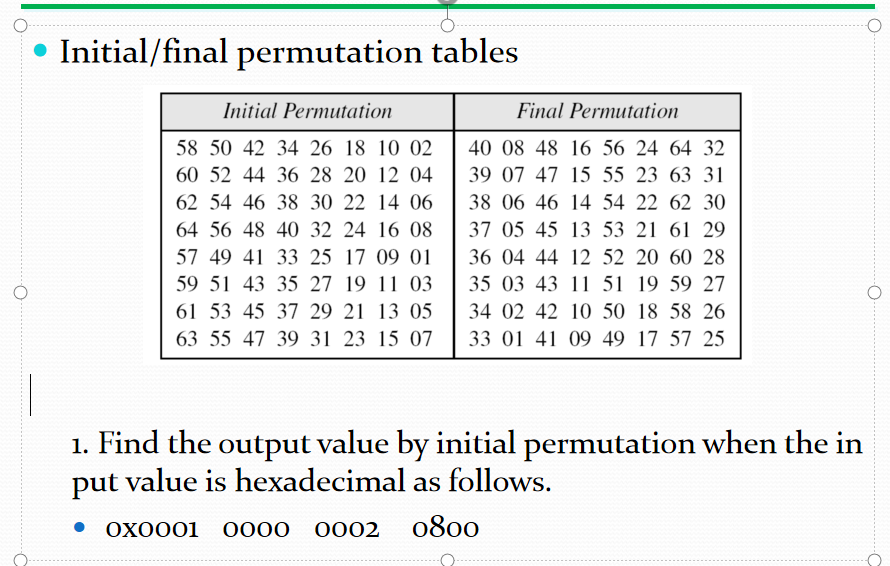
initial permutation table 테이블의 n번째 비트가 몇 번째에서 왔는지 표시한다.
final permutation table 테이블에 명시된 숫자대로 비트를 위치시켜준다.
Permutation은 F함수에서 일어난다.
Round Function
Feistel network구조를 보면 key를 이용해서 F함수에 입력값을 넣거나 XOR을 수행하는 부분이 있고, L과 R의 자리를 바꿔서 다음 라운드로 전달해주는 부분이 있다.
이렇게 함수를 수행하는 부분을 Mixer 라고 하고 키의 위치를 바꾸는 부분을 Swapper 라고 한다.
Round에서 쓰는 함수를 간략하게 F함수라고도 부른다. F함수 구성 요소는 다음과 같다.
- expansion P-box
- XOR
- S-box
- straight permutation
Expansion P-box
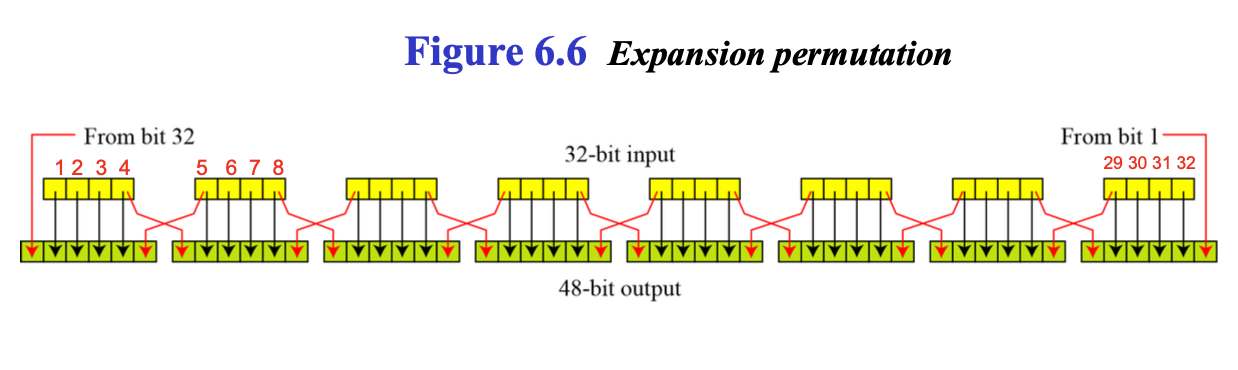
F함수에서 R값은 32비트, 키는 48비트인데 어떻게 XOR을 수행할까?
32비트 입력값을 48비트로 확장하는 작업이 필요하다. 이 작업을 Expansion P-box가 수행한다.
P box의 확장 방법은 PPT DES 부분 참고
양옆 블록의 마지막/첫 번째 비트를 하나씩 가져온다.
S-box
48비트를 6개씩 묶어서 8비트로 S-box에 투입한다. 이후 48비트로 확장했던 입력값을 다시 32비트로 줄여서 output으로 출력한다.
S-box는 8개의 테이블로 이루어져있고 각 테이블에는 숫자가 나열되어있다.
예를 들어 6비트가 110010 이라고 하면 맨 끝 1+0 -> 10(=2), 가운데 1001(=9)를 이용해서 2행 9열에 있는 1100(=12)를 산출한다.
이렇게 구성한 이유는?
보안을 향상하기 위해 비선형적 연산(f(x+y)!=f(x)+f(y))을 이용했다.
입력값과 산출값의 선형적 관계를 무너뜨려 값을 유추하기 어렵게 만들 수 있다.
따라서 S-box의 핵심 기능은 48비트 입력값을 32비트로 줄여주는 것이 아니라 입력값을 선형분석으로 알아낼 수 없게 감추는 것이라고 할 수 있다.
Straight permutation
평문 전체 중 1bit에 변화가 생기면 key값도 1bit만 바뀐다. 이유는 32비트 입력값을 4비트로 끊으면 총 8세트가 생길 텐데 이 4비트 단위가 서로 영향을 주고받지 않고 내부에서만 변경되기 때문이다.
Straight permutation은 단위로 묶인 비트가 고착되지 않고 다른 block과 잘 섞이게 하기 위해 필요한 기술이다.
key generation
DES에서 subkey를 만드는 과정을 살펴보자.
- 초기 64비트에서 permuted choice1 (PC1) 테이블을 활용하여 56비트를 고른다.
- 56비트를 28비트 데이터 두 개로 나눈다.
- 라운드에서 사용하기 전에 left rotate한다. 한 비트나 두 비트 로테이션하는데, 이 사항은 각 라운드마다 명시되어있다.
- PC2 테이블을 활용하여 56비트를 48비트로 축소한다.
PC1
7*8 테이블이다. 입력값을 보고 각 칸에 쓰인 위치에서 비트를 가져와 나열한다.
테이블 안에는 숫자가 56개밖에 없기 때문에 여기에서 64비트->56비트로 축소가 일어난다.
PC2
8*6 테이블이다. PC1과 동일한 방식으로 56비트를 48비트로 축소한다.
Double DES
컴퓨터 사양이 좋아지면서 56비트 키는 어렵지 않게 해석할 수 있게 되었다..
그래서 두 개의 키를 사용해 총 112비트로 암호를 구성하자는 아이디어가 Double DES이다.
그래서 brute force로 최대 2^112번 계산해야 double DES를 뚫을 수 있을 것으로 기대하였는데 실제로는 2^57번만의 연산으로 키를 알아내는 방법이 등장했다.
Meet-in-the-Middle Attack
임의의 key k1과 k2에 대해 전수조사를 진행하다 보면,
평문을 k1으로 암호화한 결과와 암호문을 k2로 해독한 결과가 동일한 부분이 존재할 것이다.
이것을 알아내기 위해 평문을 암호화한 값 + 암호문을 복구한 값을 각각 구해 중복값을 찾는다.
Triple DES
double DES가 뚫리고 나서 key를 세 개로 늘려 암호화하기 시작했는데 이것을 triple DES 라고 부른다.
키를 3개 사용하면 관리가 힘들기 때문에 k1 -> k2 -> k1으로 키를 바꿔가며 사용한다.
