
📍 강의 자료 출처 : LG Aimers
3. 트랜스포머 기반의 다변량 시계열 데이터 회귀모형
overview
- 합성곱 신경망
: 이미지 데이터를 처리하기 위해 제안된 방법으로, 시계열 데이터에도 활용될 수 있다. - 순환 신경망
: 원래부터 시계열 데이터, 순차 데이터를 처리하기 위해 만들어진 방법론
Transformer
: NLP를 위해 만들어진 Language Model로, 특정 문장(= 단어의 나열)이 등장할 확률을 계산해주는 모델
: Attention의 병렬적 사용을 통해 효율적인 학습이 가능한 구조의 언어 모델
Transformer는 내부에 Encoder 파트와 Decoder 파트가 존재하며 이 둘 사이를 이어주는 연결고리가 존재한다.
Encoder 작동 원리
1. 입력 임베딩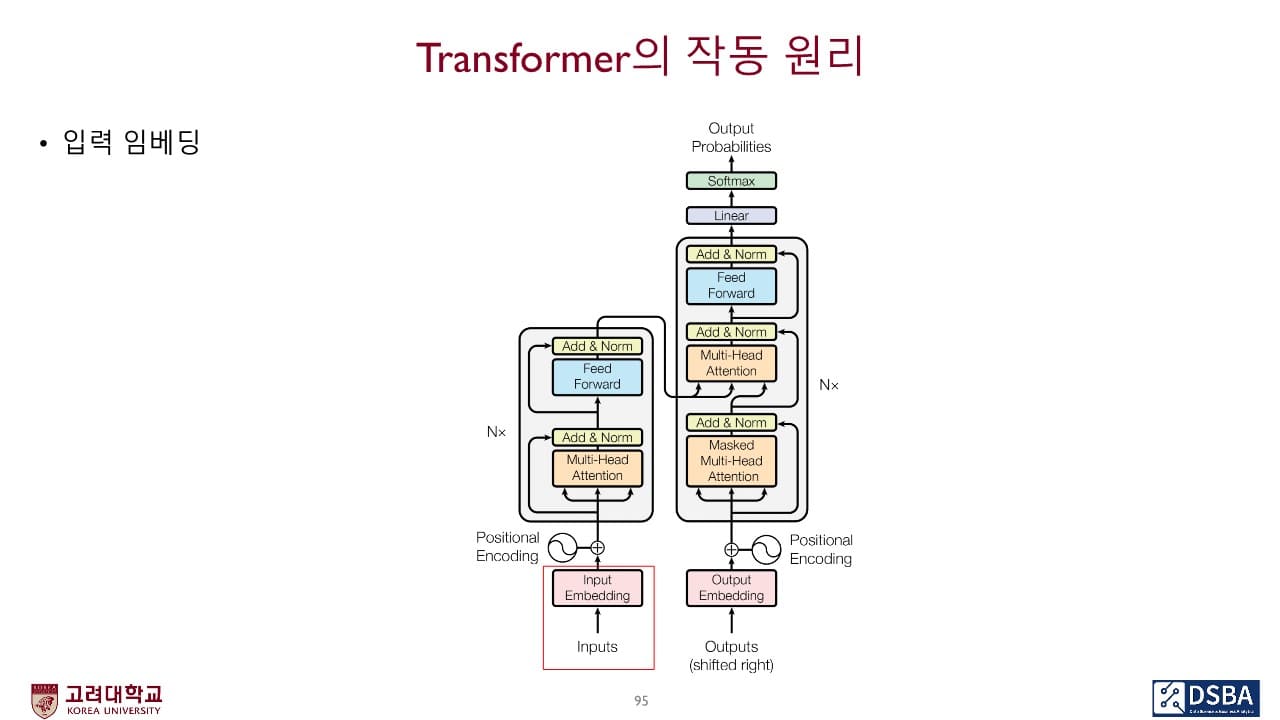
단어 임베딩은 가장 아래에 위치한 첫번째 encoder에서만 입력으로 1회 사용된다.
나머지 인코더들은 하위 인코더에서 출력된 결과물을 입력으로 사용한다.
단어 임베딩
: 컴퓨터가 입력된 단어 벡터를 인식할 수 있도록 Word2Vec, GloVe, Fast Text 등의 방법을 통해 512 차원의 연속적인 숫자들의 벡터로 표현하는 과정
두 단어가 의미적으로 유사하다면 공간상에서도 유사하도록 학습을 시켜가는 메커니즘이 있다.
⇒ semantic relationship (의미론적 관계가 최대한 보존되도록하는 특정한 벡터로 단어를 표현하는 방식)
2. 포지션 인코딩
순환신경망은 순차적으로 데이터를 입력 받지만,
Transformer는 한 번에 전체 데이터를 입력받기 때문에 입력 시퀀스에 대해 위치 관계를 표현해줘야 한다.
→ 이러한 역할을 수행하도록 설계된 벡터를 포지션 인코딩이라고 하며, 모든 단어 임베딩에 포지션 인코딩을 더해서 입력 벡터를 구성한다.
3. 멀티 헤드 어텐션
: 일정한 토큰들(= 문서)를 입력 받았을 때 그 문서 안에서 단어들이 서로 어떠한 연관관계를 가지고 있는지에 대한 해석을 하는 과정
→ 한 query 토큰에 대해 다양한 관점으로 표현할 수 있는 능력을 제공한다.
예) "The animal didn't cross the street because it was too tired."라는 문장에서 한 번의 Attention 블럭은 지시대명사 it이 가리키는게 무엇인지에 대한 답을 주고, 두 번째 Attention 블럭은 왜 it이 길을 건너지 않았는지에 대한 답을 준다.
⇒ Encoder
포지션 인코딩이 더해진 단어 임베딩은 첫번째 encoding 블럭에서 self-attention과 FFNN을 거친다.
+) 특정 위치의 단어는 해당 위치를 유지하면서 연산이 수행된다. self-attention은 이 경로 간 의존성이 존재한다.
self-attention
: 한꺼번에 들어온 입력 시퀀스에서 단어 간 서로 어떤 관계가 있는지를 스스로 학습할 수 있는 구조
이때 , , 가 데이터를 통해 학습을 하는 대상이다.
→ Transformer를 학습한다 = , , 를 학습한다
⇒ attention score가 계산되면 기존에 가지고 있는 value vector와 선형결합하여 라는 출력을 만든다.
이때 입력 와 출력 는 서로 연결되어 있다 = 순차적인 위치를 그대로 유지한다
- 예시를 통한 절차
- 실제 연산 절차








Decoder 작동 원리
1. Masked Multi-Head Attention
decoding은 encoding과는 달리 순차적으로 일어난다.
예) "I love you"를 "나는 너를 사랑해"로 번역할 때, 입력인 "I love you"는 전체 문장이 한꺼번에 들어오지만 출력 시에는 "너를"이 "사랑해"보다 먼저 처리되기 때문에 "사랑해"를 "너를"을 구하는 과정에 사용할 수 없다.
→ decoding 단계에서 self-attention은 query 토큰보다 뒤에 위치한 토큰들에 대한 정보가 가용하지 않다고 가정하고 해당 부분을 모두 masking 처리한다.
2. The Final Linear Layer and Softmax Layer
- Linear layer
: 단순 FFNN 형태로서 마지막 decoder의 출력 결과물을 이용하여 모든 단어들의 출력 확률을 산출하기 위해 차원을 늘리는 역할 - Softmax layer
: 개별 단어들의 출력 확률을 반환하는 역할
Time-Series Transformer (TST)
Transformer의 encoder 구조만 사용하고 Pre-training, Fine-tuning 과정을 거친다.
개의 변수와 개의 time window를 갖는 원본 입력 데이터 X가 있을 때, Pre-training, Fine-tuning 과정에서 각각 변환이 이루어진다.
Pre-training
: 데이터를 통해 Transformer의 구조를 미리 학습하는 것 (사전 학습 단계)
⇒ data를 일부러 훼손시킨 다음 모델에 입력하고 학습을 통해 완전한 data를 맞춰라
변환 : 원본 입력 데이터 → 일부를 masking한 뒤 Transformer의 input이 되는 차원으로 ()
masking을 하는 이유
Transformer의 사전 학습 목적 : masking된 부분을 정확하게 예측하는 것으로 설계됨
+) Masking의 길이가 평균 이 되는 기하분포를 따르도록 Markov Chain을 적용하여 Masking 여부를 결정한다.
( masking 여부를 독립적으로 결정하게 되면 크기가 작은 입력 데이터의 경우 trivial한 solution으로도 문제를 잘 맞추는 상황이 발생)

+) TST도 포지션 인코딩을 거치고 이후에는 NLP의 Transformer와 동일한 과정을 거친다.
cf> NLP의 Transformer vs. TST
- NLP의 Transformer
- 6개의 Encoder 블록 사용
- Batch Normalization
- TST
- 3개의 Encoder 블록 사용
- Layer Normalization
Fine-tuning

: 원하는 task를 잘 풀 수 있도록 고도화하는 것 (미세 조정 단계)
⇒ 사전학습을 마친 data를 이용하여 최종적으로 가 무엇인지 예측하라
변환 : 원본 입력 데이터 → masking 과정 없이 차원으로

+) 고려대학교 산업경영공학부 강필성 교수 강의
+) 고려대학교 DSBA 연구실 김동화 박사 세미나
+) 고려대학교 DSBA 연구실 최희정 박사과정 세미나
