
📍 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
❗️개념을 정리하기 위해 작성한 글로, 내용상 잘못된 부분이 있을 수 있다는 점 참고 바랍니다.
논문에서는 순서가 아래와 같이 구성되어있다.
- Introduction
- Related Work
- Method
- Vision Transformer (ViT)
- Fine-Tuning and Higher Resolution
- Experiments
- SetUp
- Comparison to State Of The Art
- Pre-training data requirments
- Scaling Study
- Inspecting Vision Transformer
- Self-Supervision
- Conclusion
Meta-Transformer 논문을 읽던 중 backbone으로 ViT가 사용된다는 것을 알았고,
ViT가 기존 Transformer와 어떻게 다른 방식으로 작동하는지를 파악하고자 Method 위주로 논문을 읽었다.
이 글에서도 Method에 대해서만 간략하게 정리할 것이다.
Method
기존 Transformer는 자연어 기반의 모델로,
자연어 문장이 입력으로 들어오면 임베딩을 통해 하나의 시퀀스로 입력 형태를 바꿔주고, 시퀀스 내 각 토큰 간의 attention 정보를 기반으로 학습하였다.
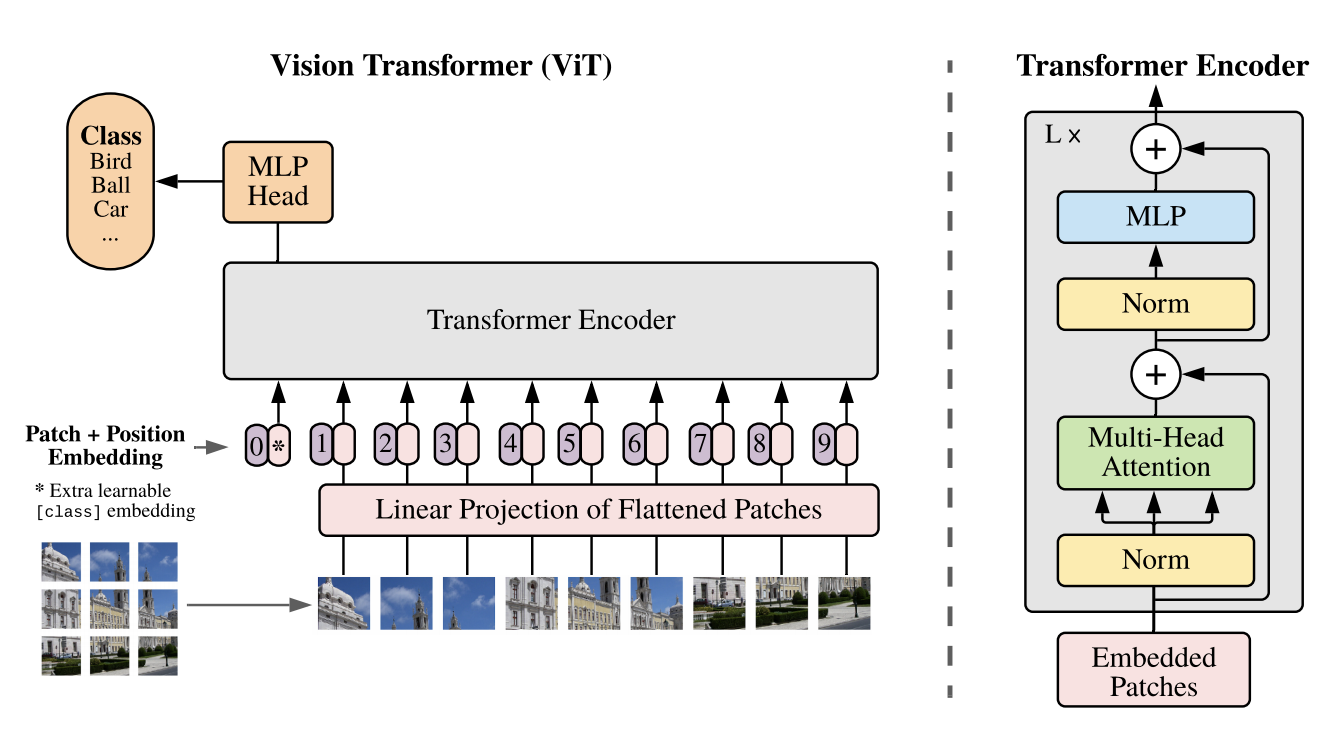
ViT는 Transformer 중 Encoder 부분만 사용한 모델로, Image Recognition을 목적으로 고안되었다.
Transformer의 Encoder는 하나의 시퀀스를 입력으로 넣어줘야 하기 때문에 2차원의 이미지를 적절하게 변환해주는 과정이 필요하다. 이에 대한 순서는 아래와 같다.
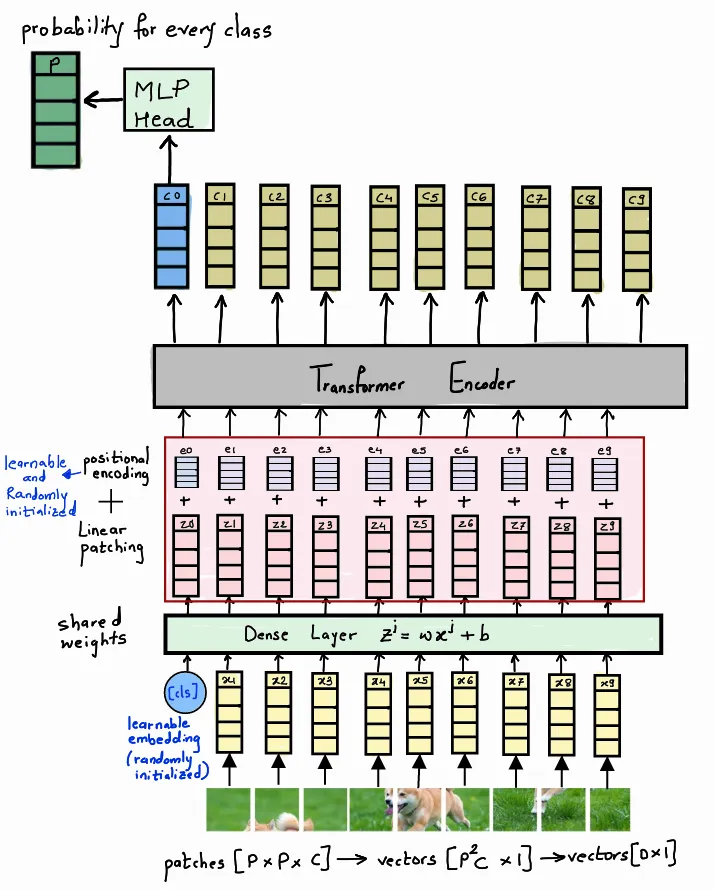
-
(H, W, C) 차원의 이미지를 P x P 크기의 패치로 잘라준다.
이때 패치의 크기인 P는 이미지가 표현할 수 있는 픽셀 수와 같다.(H, W, C) 이미지를 N개의 (P, P, C) 패치로 자르는 이유
: 전체 (H, W, C) 이미지에서 각 픽셀을 입력으로 사용하면 attention score 구할 때 계산량이 너무 많아진다는 문제가 발생한다. -
2차원 상에 존재하는 각 패치들을 1차원으로 Flatten 시킨다.
= 패치들을 한 줄로 나열한다.
= (P, P, C) → ( x C, 1)
내가 참고한 코드에서는 1번과 2번 과정을 하나로 합쳐 (H, W, C)를 바로 ( x C, 1)로reshape하였다. -
가장 첫번째로 오는 패치의 앞에 [CLS] 토큰을 붙여준다.
Transformer Encoder를 거쳐 나오는 이 토큰의 context vector는 모든 패치들끼리의 전반적인 관계 정보를 저장하고 있다. 따라서 이 토큰의 context vector를 최종 MLP Head의 입력으로 사용할 것이다. -
Dense layer를 거쳐 각 패치들을 D차원으로 임베딩시킨다.
이때 D는 Transformer에서 지정된 입력의 크기를 의미한다.
Dense layer를 거치면서 (N(이미지 패치들)+1([CLS] 토큰))개의 content vector들이 각각 D개의 픽셀 수를 갖는 벡터로 linear projection 된다. -
content vector에 위치 정보를 추가해준다.
앞서 이미지 패치들을 1차원으로 Flatten하는 과정에서 각 패치들의 순서 정보가 사라졌는데, 이 정보를 다시 포함시키기 위해 positional encoding vector를 4에서 구한 content vector에 element-wise하게 더해준다.기존 Transformer는 positional encoding vector를 구하기 위해 sin함수를 사용하였다.
하나의 책, 엄청 긴 문장이 입력으로 들어올 수 있다는 점에서
같은 단어가 입력되더라도 문장에 따라 각 토큰의 위치가 겹치지 않도록 하기 위해 sin, cos 함수를 이용한 것이다.반면 이미지는 (고해상도의 경우 일렬로 나열했을 때 시퀀스가 길어질 수는 있지만) 자연어에 비해 그 길이가 상대적으로 짧다. 따라서 one-hot encoding 방식으로도 큰 무리 없이 위치 정보를 나타낼 수 있었다.
ex) 이미지가 3 X 3개의 패치로 쪼개진 경우,
와 같이 각 패치별로 위치 번호를 지정하고 이 숫자를 one-hot encoding 해준다.
이렇게 임베딩된 이미지는 최종적으로 (N + 1) X D 형태로 Transformer의 Encoder에 입력되고 context vector를 얻게 된다.
이렇게 구한 [CLS]의 context vector를 MLP HEAD에 넣으면 각 라벨의 확률 분포를 구할 수 있어 가장 확률이 높은 라벨로 이미지를 분류할 수 있다.
이미지가 입력되다 보니 임베딩 과정이 자연어와 다르게 처리될 뿐, 전반적인 맥락은 비슷하다고 느꼈다. 자연어에서는 하나의 문장을 토큰화하듯, 이미지에서는 하나의 이미지를 패치로 쪼개주고 이를 한 줄로 나열해 시퀀스를 만든다.
또 논문에서 이미지에 CNN을 먼저 수행해 feature map을 얻고 이를 Transformer Encoder에 넣는 Hybrid 방식을 제시하였는데 졸업 프로젝트로 했던 CNN 기반 Transformer가 유사한 형태라 흥미로웠다.
References
📍 Transformers Everywhere - Patch Encoding Technique for Vision Transformers(ViT) Explained
📍 Vision Transformer (ViT) PyTorch 구현 코드 리뷰 - 1

많은 것을 배웠습니다, 감사합니다.