Vanishing Gradient
- Backpropagation에서 layer 수가 많아지면, Chain-rule과 Sigmoid에 의해 1보다 작은 값을 계속 곱하게 되어 최종 미분값이 0에 가까워짐
=> 많은 layer를 이용해도 정확도가 높아지지 않음
Geoffery Hinton이 발견한 문제점과 해결법
- "We used the wrong type of non-linearity." => ReLU
- "We initialized the weights in a stupid way." => weight 초기화
solution 1) ReLU (Rectified Linear Unit)
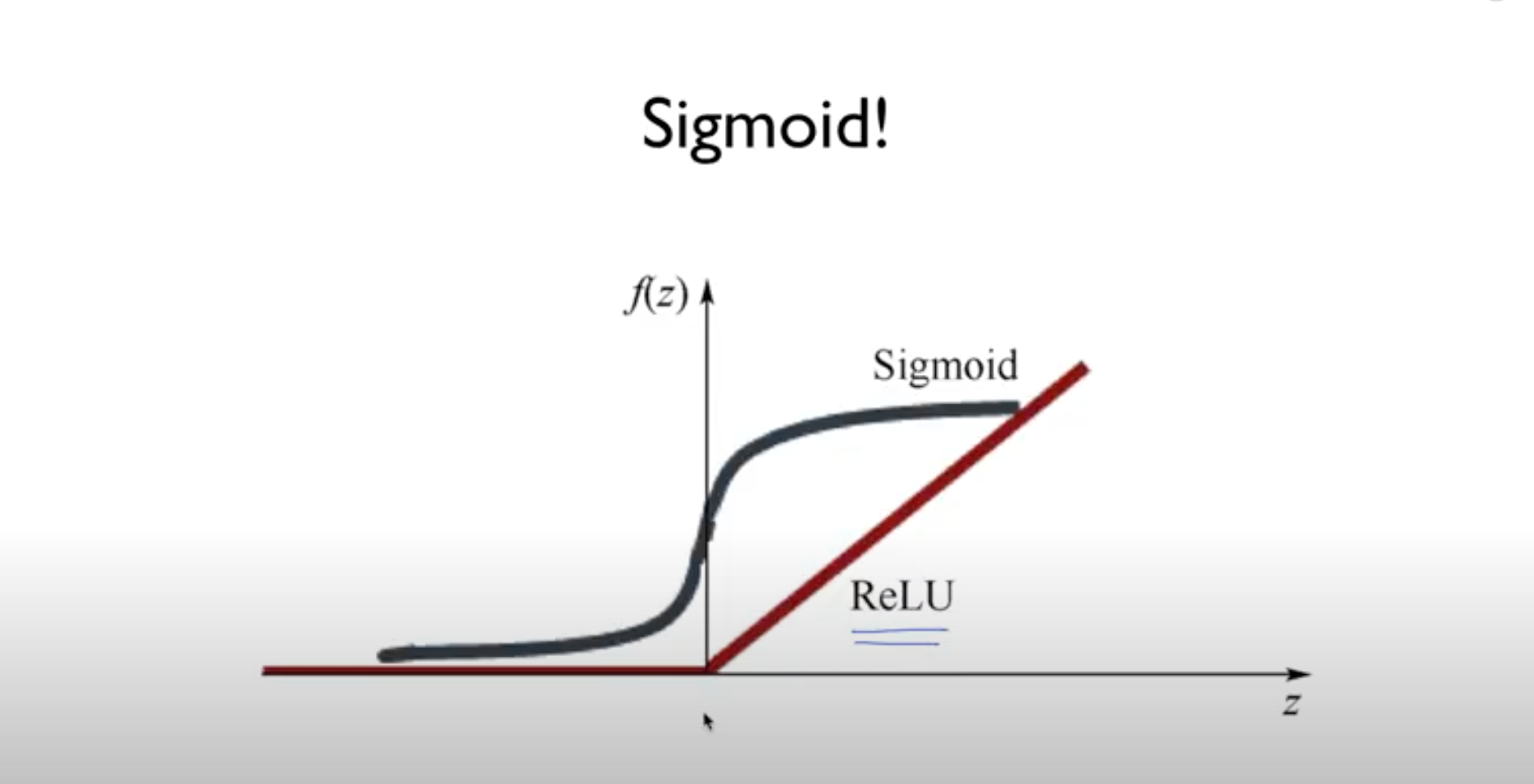
-
Sigmoid를 대신해서 Activation function으로 사용됨
=> tf.sigmoid() -> tf.nn.relu() -
단, 가장 마지막 출력에서는 Sigmoid 사용해야 함
+) ReLU에서 파생된 다른 Activation function로는 Leaky ReLU, Maxout, ELU 등이 있고 Sigmoid를 보완한 Activation function로는 tanh가 있음
solution 2) Weight 초기화
-
문제 상황 : W를 random 값으로 설정했기 때문에 ReLU를 사용한 같은 코드여도 서로 다른 cost function 그래프를 얻게 됨
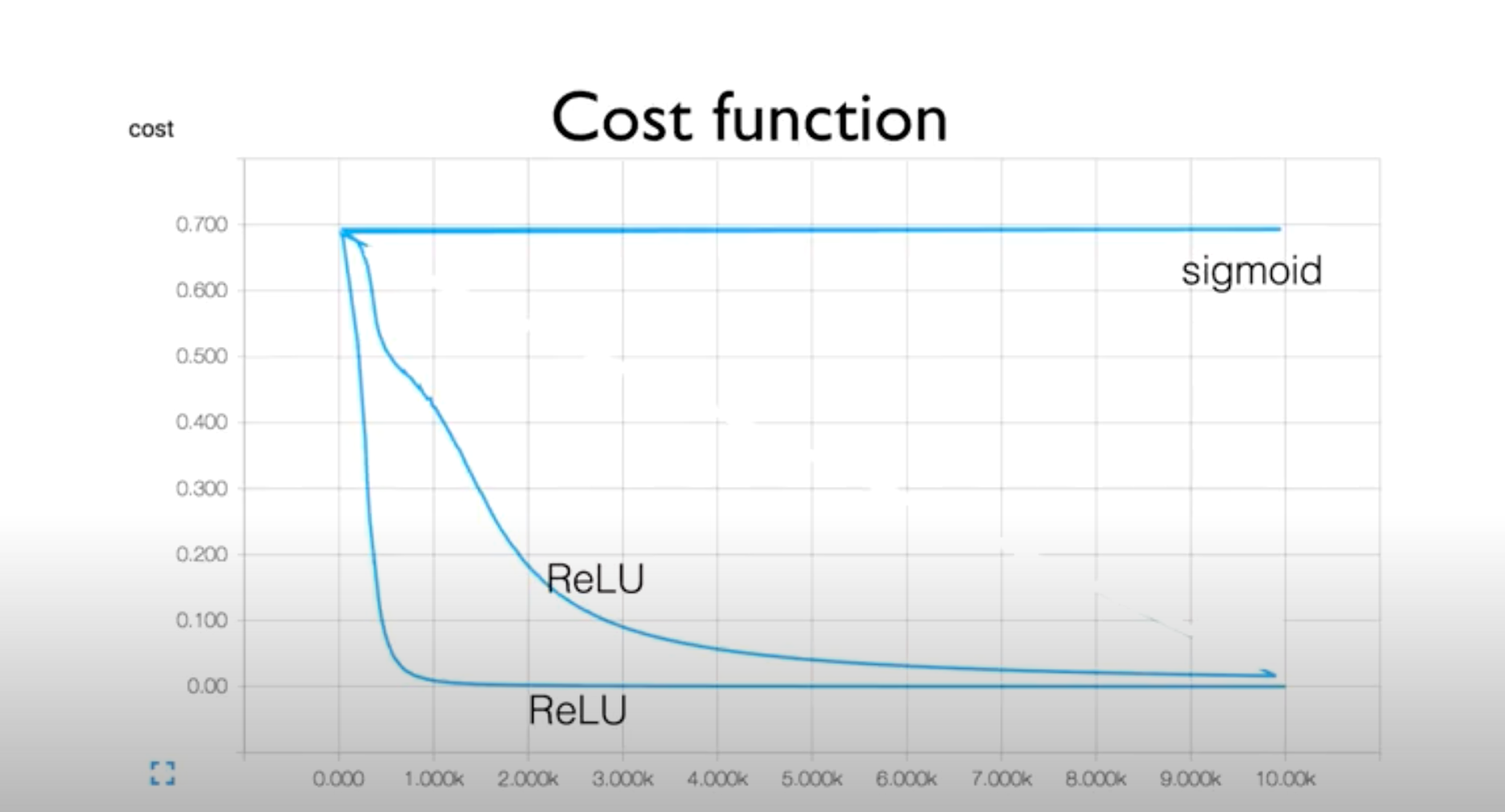
-
if> W를 항상 0으로 초기화한다면?
--> 미분값도 0이 되어 gradient가 사라지는 문제가 발생하므로 절대 w의 초기값을 0으로 설정해선 안됨
1. RBM(Restricted Boatman Machine) (2006)
-
"A Fast Learning Algorithm for Deep Belief Nets"에서 소개된 학습법으로, RBM을 통해 초기화된 모델을 DBN(Deep Belief Nets)이라 함
-
목적 : recreate input
-
진행 순서 :
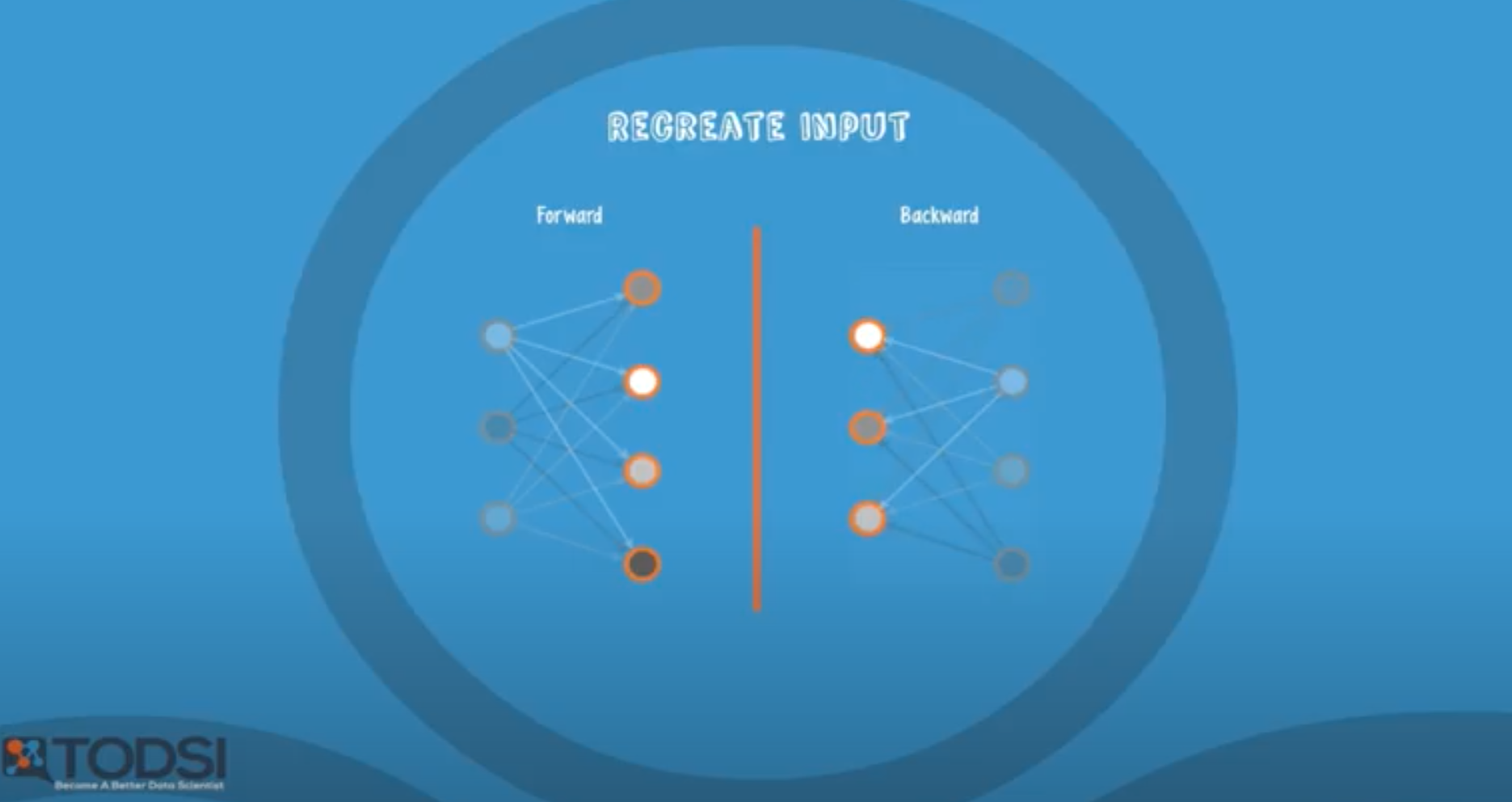
1. forward(encode) : 기존의 X라는 데이터셋에 W를 곱해 값을 만들어 냄
2. backward(decode) : forward의 역방향으로 똑같은 과정 진행
3. 1에서의 기존 X와 2에서 얻은 새로운 값을 비교하여 둘의 차이가 가장 작아지도록 W 조절
2. Xavier initialization (2010)
3. He's initialization (2015)
입력값(fan-in)과 출력값(fan-out)의 개수에 비례하게 weight 초기화
=> 입력값을 랜덤하게 주되 input과 output 개수 사이의 랜덤한 숫자를 sqrt(input)값으로 나눈 값으로 초기화
- xavier : 입력값과 출력값 사이의 난수를 선택해서 입력값의 제곱근으로 나눔
- he's : 입력값을 반으로 나눈 재곱근 사용. 분모가 작아지기 때문에 xavier보다 넓은 범위의 난수 생성
