RNN
RNN : Recurrent Neural Network
- 사용 목적 : sequential data를 잘 다루기 위해
sequential data : data의 값뿐만 아니라 그 data의 순서도 중요한 의미를 가지는 데이터 (ex. 'hello'라는 단어)
cf> RNN 이전의 neural network로도 sequential data를 다룰 수 있으나 순서에 얽혀있는 굉장히 복잡한 구조를 파악하기 어려움 - RNN에서는 position index 대신 "입력하는 데이터의 순서를 model이 어떻게 하면 잘 이해할 수 있을지" 중심으로 설계함
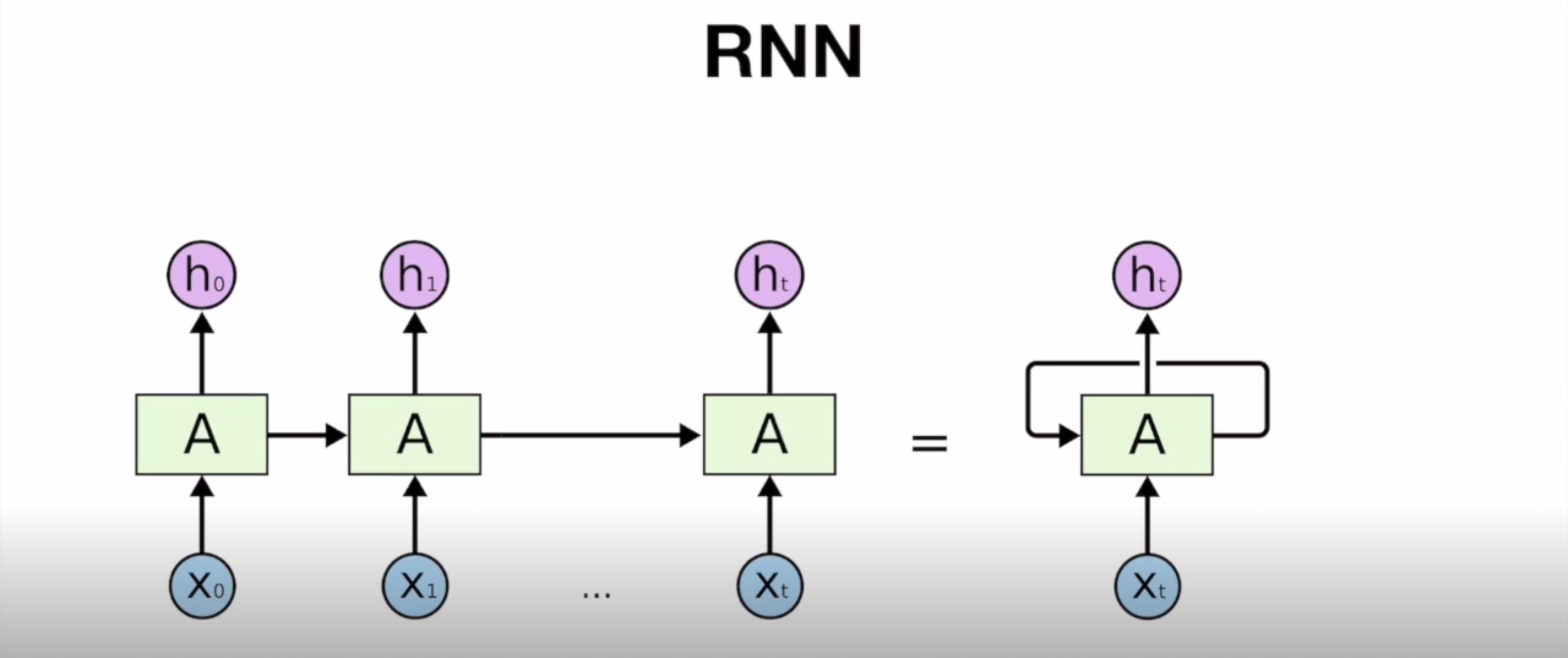
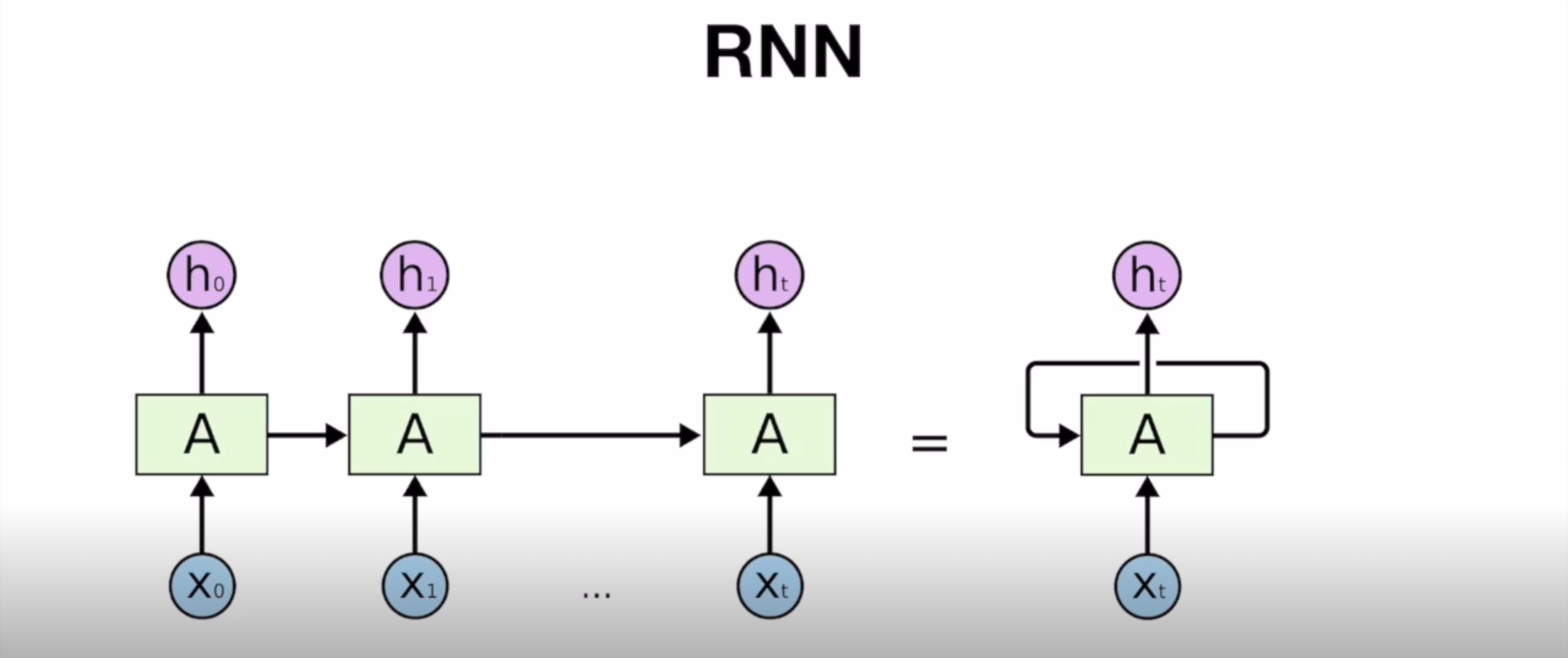
RNN의 구조
- 셀 A에 t번째 입력값이 들어가게 되면 t번째 출력값이 나오고 동시에 다른 출력값(hidden state) 하나가 다시 셀 A로 돌아 들어감
hidden state : 출력되지 않고 다음 셀로 전달되는 값 - hidden state가 전달됨에 따라 그 전의 입력값의 처리 결과를 반영할 수 있음
-> model이 data의 순서를 이해하게 됨 - RNN은 모든 셀이 전부 파라미터를 공유
= 긴 sequence가 들어와도 이를 처리하기 위한 A가 하나
= 어떤 단어가 들어와도 셀 A에 들어가는 파라미터만 알고 있으면 언제든지 다음 단어를 예측하는 model을 정상적으로 작동할 수 있음
셀 A에서의 연산
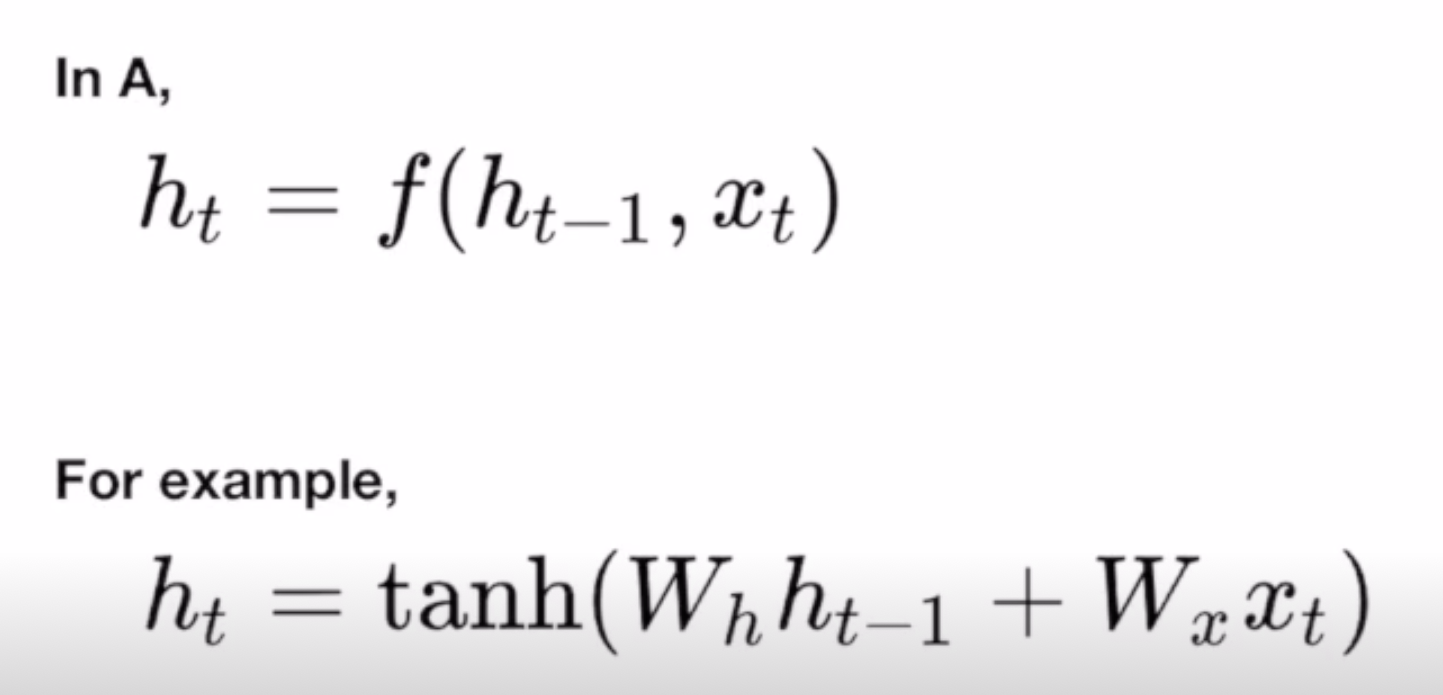

- hidden state 이전 단계의 hidden state와 지금 단계에서의 입력값의 함수 연산을 통해 출력값 h(t)를 얻음
- 함수 f는 모든 RNN에 대해 동일함
- 셀의 구조가 복잡해질수록 trainability(학습정도)가 감소함
=> 복잡한 셀을 쓰면 같은 수준의 학습에서는 좋은 성능을 낼 수 있지만 그 수준에 도달하기까지 더 많은 학습 자원이 필요함
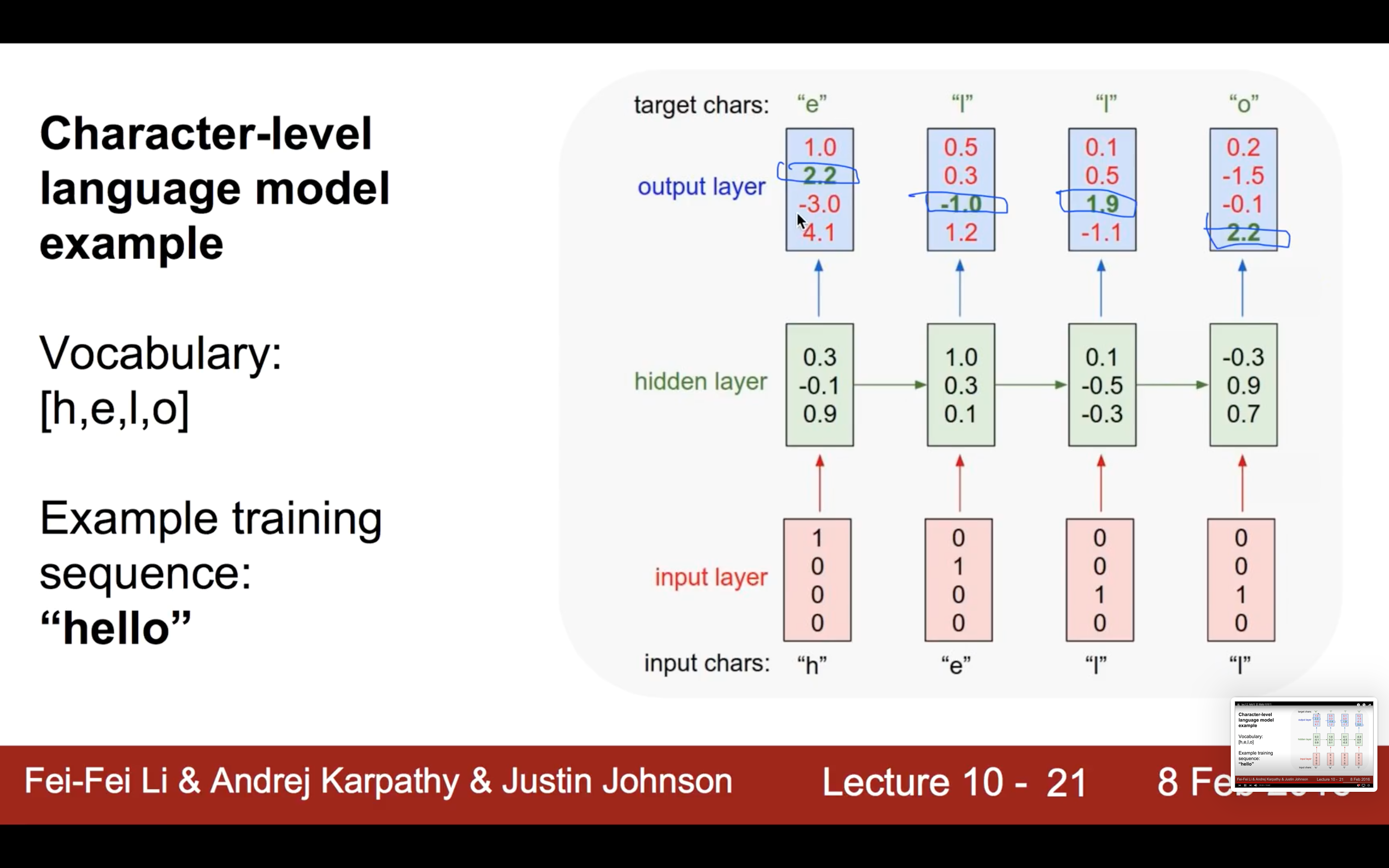
- softmax를 통해 cost 계산을 하고 입력된 데이터 수만큼 나눠 평균 내어 학습 가능하게 만듦
Usage of RNN
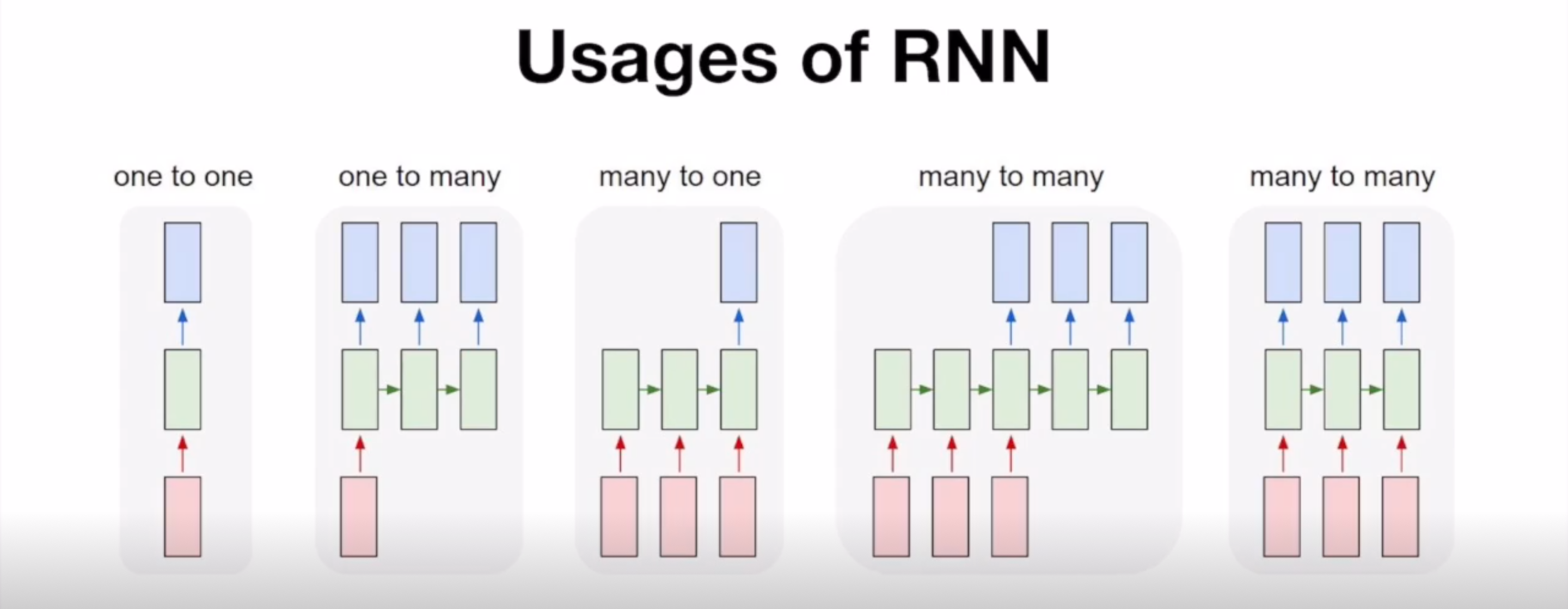
- one to one : RNN(X) neural network(O)
- one to many : 입력이 하나이고 출력이 여러 개인 경우
ex) image captioning task - many to one : 입력이 여러 개이고 출력이 하나인 경우
ex) sentiment classification
cf> 출력값이 여러 개가 나오긴 하지만 해당되는 출력값만 쓰겠다고 설계된 상황 - many to many : 입력과 출력 모두 여러 개인 경우
ex) Machine translation, Video classification on frame level
+) Language Modeling(ex.연관검색어), Speech Recognition, Conversation Modeling/Question Answering, Image/Video Captioning, Image/Music/Dance Generation 등
