
텍스트 마이닝이란?
= 텍스트 데이터 + 데이터 마이닝
: 문서 집합(Corpus)로부터 새로운 정보를 확인하는 프로세스
- 텍스트 데이터를 정형 데이터로 변환하면 다양한 분석 방법론의 활용 가능
ex) 군집분석, 토픽모델링, 감성분석, 연관어분석 등
- 분석 품질의 향상
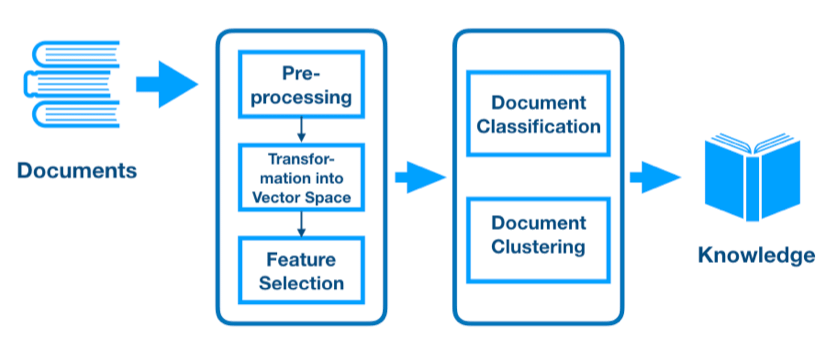
텍스트 분석 활용 영역
- 단어 빈도에 기반한 분석
ex) 뉴욕타임즈에 실린 미국 대통령 연설문 단어 빈도 분석 - 의미망 분석
: 점과 선을 활용해 텍스트 데이터의 의미 파악 - 지도학습 기법의 활용
ex) 고객 리뷰, 웹사이트 포럼, 이메일, 트위퉈 메세지 등을 활용한 이탈 고객 예측 / 의료기록지를 활용한 입원 여부 판단 / 보험 사기 탐지 / 감성 분석 - 음성 인식, 언어 모형, 기계 번역, 요약 등
텍스트 가공
- 단어 표현의 카테고리
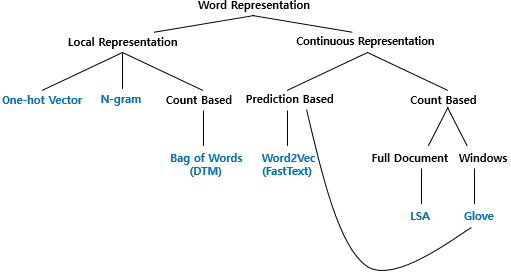
국소 표현 (Local representation) 방법
: 해당 단어 그 자체만 보고, 특정값을 맵핑하여 단어를 표현하는 방법
ex) puppy, cute, lovely라는 단어가 있을 때 각 단어에 1번, 2번, 3번 등과 같은 숫자를 맵핑(Mapping)- 단어의 의미, 늬앙스를 표현할 수 없음
- One-hot vector, N-gram, (카운트 기반)Bag of word, TDM, TF-IDF
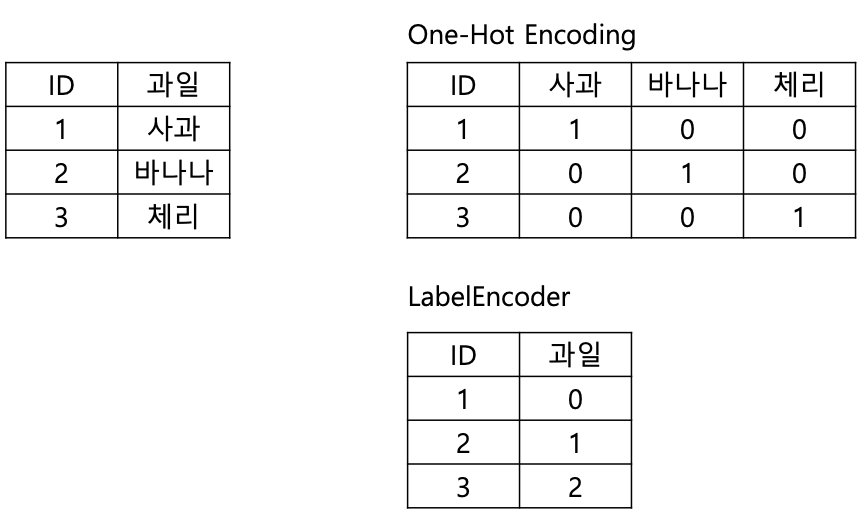
One-hot encoding
- 문자를 숫자로 표현하는 기법 중 가장 기본적인 표현 방식
- 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스는 1 / 다른 단어들의 인덱스에는 0을 부여함
Bag-of-Words(BoW)
- 텍스트에서 사용된 단어의 종류와 빈도만을 바탕으로 분석
- 전체 문장 구조를 보지 않고 사용된 단어만 보더라도 대략의 의미 파악이 가능함
장점 VS. 단점- 전처리가 단순함
- 단어들의 빈도를 간단히 수치화할 수 있고 통계 방법 적용이 가능함
- 분석 결과의 해석이 용이함
- 문장 구조를 무시하기 때문에 어순 상의 차이 파악이 불가능함
- 동음이의어의 구별이 어려움
단어 문서 행렬 Term-by-Document Matrix(TDM)

- 문서별로 나타난 단어의 빈도를 표 형태로 나타낸 것
한계 - 희소 행렬 (Sparse Matrix)
: 문서 군내에서 사용되는 단어의 수가 많지만 하나의 문장이나 문서에서 사용되는 단어의 수가 제한적임에 따라 대부분의 칸이 0값일 수 있음
→ 사례 수에 비해 변수의 수가 많아 분석이 어려움 - 단순 빈도 수 기반
→ 중요한 단어와 불필요한 단어들이 혼재되어 있음
단어 빈도-역 문서 빈도 TF-IDF (Term Frequency-Inverse Document Frequency)
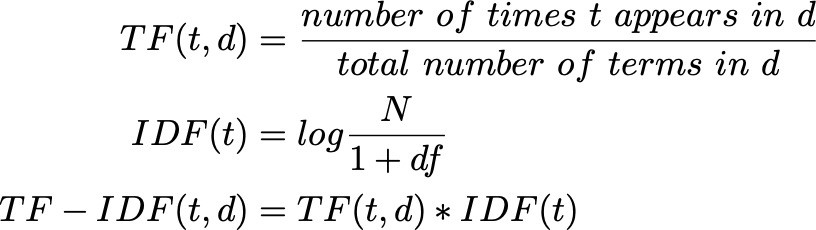
- 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)을 사용하여 TDM 내의 각 단어들마다 중요한 정도에 가중치를 주는 방법
- 문서의 유사도, 검색 결과의 중요도, 문서 내에서 특정 단어의 중요도 확인

 → 많은 문서에서 자주 등장하는 단어 : 중요도가 낮다
→ 많은 문서에서 자주 등장하는 단어 : 중요도가 낮다
→ 특정 문서에서만 자주 등장하는 단어 : 중요도가 높다
- 연속 표현 (Continuous Representation) 방법
: 그 단어를 표현하고자 주변을 참고하여 단어를 표현하는 방법
ex) puppy라는 단어 근처에 주로 cute, lovely 등 단어가 자주 등장한다면, "puppy라는 단어는 cute, lovely한 느낌이다"로 정의- 단어의 늬앙스를 표현할 수 있음 → 학습 성능이 높아짐
- (예측 기반)Word2Vec, FastText, (카운트 기반)LSA, (예측, 카운트 기반)Glove
→ 단어 임베딩(Word Embedding)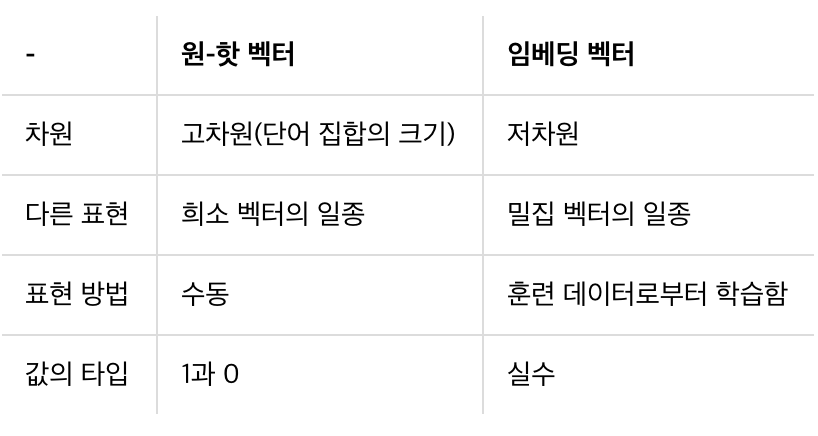 - 단어의 의미를 고려하여 좀 더 조밀한 차원에 단어를 벡터로 표현
- 단어의 의미를 고려하여 좀 더 조밀한 차원에 단어를 벡터로 표현
- 벡터의 차원을 단어 집합의 크기로 정하지 않으며, 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춤
- 벡터 공간에서의 연간 가능Word2Vec
 +) Word2Vec 사이트
+) Word2Vec 사이트
= 비지도학습으로 임베딩 공간의 밀도를 높이는 방법
목표 : 단어들을 벡터 공간에 두고 유사한 단어들을 서로 가깝게 하고자 함
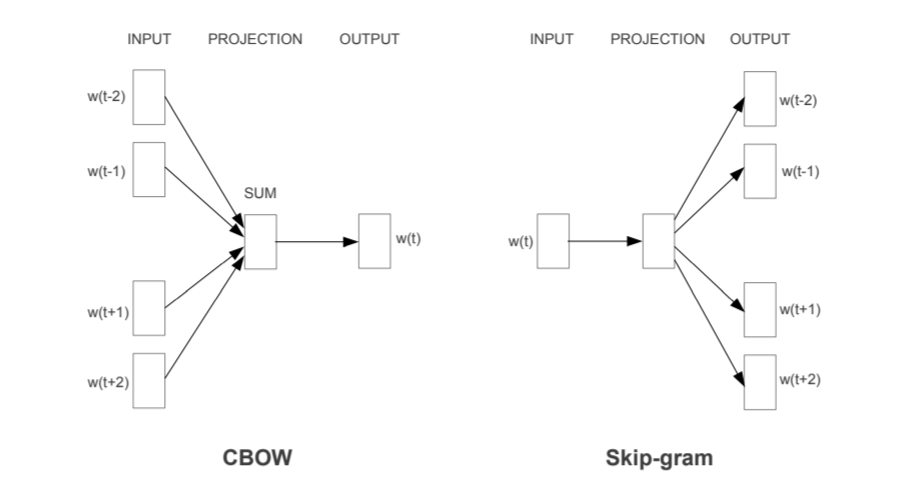
- CBOW (Continuous Bag of Word)
+) CBOW 개념 정리
: 주변에 있는 단어들을 가지고 중간에 있는 단어들을 예측하는 방법
: 문백 단어의 순서는 예측에 영향을 주지 않음
- Skip-gram
+) Skip-gram 개념 정리
: 중간에 있는 단어로 주변 단어를 예측
- CBOW (Continuous Bag of Word)
