
수업 정리
강의 목록
[Python Basic for AI] File / Exception / Log Handling
- Exception
- 예상 가능한 예외
- 발생 여부를 사전에 인지할 수 있는 예외
- 사용자의 잘못된 입력, 파일 호출 시 파일 없음
- 개발자가 반드시 명시적으로 정의 해야함
- 예상이 불가능한 예외
- 인터프리터 과정에서 발생하는 예외, 개발자 실수
- 리스트의 범위를 넘어가는 값 호출, 정수 0으로 나눔
- 수행 불가시 인터프리터가 자동 호출
- 예외 처리 (Exception Handling) : 예외가 발생할 경우 후속 조치 등 대처 필요
- 없는 파일 호출 → 파일 없음을 알림
- 게임 이상 종료 → 게임 정보 저장
- 프로그램 = 제품, 모든 잘못된 상황에 대처가 필요
- exception의 종류
- Built-in Exception: 기본적으로 제공하는 예외
- IndexError : List의 Index 범위를 넘어갈 때
- NameError : 존재하지 않은 변수를 호출 할 때
- ZeroDivisionError : 0으로 숫자를 나눌 때
- ValueError : 변환할 수 없는 문자/숫자를 변환할 때
- FileNotFoundError : 존재하지 않는 파일을 호출할 때
- try ~ except
- try ~ except ~ else
- try ~ except ~ finally
- raise 구문 : 필요에 따라 강제로 Exception을 발생
- assert 구문 : 특정 조건에 만족하지 않을 경우 예외 발생
- 파일 (File)
- 컴퓨터에서 정보를 저장하는 논리적인 단위
- 파일은 파일명과 확장자로 식별됨
- 실행, 쓰기, 읽기 등을 할 수 있음
- 파일의 종류
- 기본적인 파일 종류로 text 파일과 binary 파일로 나눔
- 컴퓨터는 text 파일을 처리하기 위해 binary 파일로 변환시킴
- 모든 text 파일도 실제는 binary 파일, ASCII/Unicode 문자열 집합으로 저장되어 사람이 읽을 수 있음
- Python File I/O : 파이썬은 파일 처리를 위해 “open” 키워드를 사용함
- r(read) : 읽기모드 - 파일을 읽기만 할 때 사용
- w(write) : 쓰기모드 - 파일에 내용을 쓸 때 사용
- a(append) : 추가모드 - 파일의 마지막에 새로운 내용을 추가 시킬 때 사용
- Pickle
- 파이썬의 객체를 영속화(persistence)하는 built-in 객체
- 데이터, object 등 실행중 정보를 저장 → 불러와서 사용
- 저장해야하는 정보, 계산 결과(모델) 등 활용이 많음
- 로그 남기기 - Logging
- 프로그램이 실행되는 동안 일어나는 정보를 기록을 남기기
- 유저의 접근, 프로그램의 Exception, 특정 함수의 사용
- Console 화면에 출력, 파일에 남기기, DB에 남기기 등등
- 기록된 로그를 분석하여 의미있는 결과를 도출 할 수 있음
- 실행시점에서 남겨야 하는 기록, 개발시점에서 남겨야하는 기록
- print vs logging
- 기록을 print로 남기는 것도 가능함
- 그러나 Console 창에만 남기는 기록은 분석시 사용불가
- 때로는 레벨별(개발, 운영)로 기록을 남길 필요도 있음
- 모듈별로 별도의 logging을 남길 필요도 있음
- 이러한 기능을 체계적으로 지원하는 모듈이 필요함 (logging 모듈)
- logging level
- 프로그램 진행 상황에 따라 다른 Level의 Log를 출력함
- 개발 시점, 운영 시점 마다 다른 Log가 남을 수 있도록 지원함
- DEBUG > INFO > WARNING > ERROR > Critical
- Log 관리시 가장 기본이 되는 설정 정보
- debug : 개발시 처리 기록을 남겨야하는 로그 정보를 남김
- info : 처리가 진행되는 동안의 정보를 알림
- warning : 사용자가 잘못 입력한 정보나 처리는 가능하나 원래 개 발시 의도치 않는 정보가 들어왔을 때 알림
- error : 잘못된 처리로 인해 에러가 났으나, 프로그램은 동작할 수 있음을 알림
- critical : 잘못된 처리로 데이터 손실이나 더이상 프로그램이 동 작할 수 없음을 알림
- configparser
- 프로그램의 실행 설정을 file에 저장함
- Section, Key, Value 값의 형태로 설정된 설정 파일을 사용
- 설정파일을 Dict Type으로 호출후 사용
- argparser
- Console 창에서 프로그램 실행시 Setting 정보를 저장함
- 거의 모든 Console 기반 Python 프로그램 기본으로 제공
- 특수 모듈도 많이 존재하지만(TF), 일반적으로 argparse를 사용
- Command-Line Option 이라고 부름
[Python Basic for AI] Python data handling
- Comma Separate Value
- CSV, 필드를 쉼표(,)로 구분한 텍스트 파일
- 엑셀 양식의 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식이라고 생각하면 쉬움
- 탭(TSV), 빈칸(SSV) 등으로 구분해서 만들기도 함
- 통칭하여 character-separated values (CSV) 부름
- 엑셀에서는 “다름 이름 저장” 기능으로 사용 가능
- Text파일 형태로 데이터 처리시 문장 내에 들어가 있는 “,” 등에 대해 전처리 과정이 필요
- 파이썬에서는 간단히 CSV파일을 처리하기 위해 csv 객체를 제공함
- CSV 객체 활용
- delimiter (default = ,) : 글자를 나누는 기준
- lineterminator (default = \r\n) : 줄 바꿈 기준
- quotechar (default = ") : 문자열을 둘러싸는 신호 문자
- quoting (default = QUOTE_MINIMAL) : 데이터 나누는 기준이 quotechar에 의해 둘러싸인 레벨
- Web
- World Wide Web(WWW), 줄여서 웹이라고 부름
- 우리가 늘 쓰는 인터넷 공간의 정식 명칭
- 팀 버너스리에 의해 1989년 처음 제안되었으며, 원래는 물리학자들간 정보 교환을 위해 사용됨
- 데이터 송수신을 위한 HTTP 프로토콜 사용, 데이터를 표시하기 위해 HTML 형식을 사용
- Web은 어떻게 동작하는가?
1) 요청 : 웹주소, From, Header 등
2) 처리 : Database 처리 등 요청 대응
3) 응답 : HTML, XML 등으로 결과 반환
4) 렌더링 : HTML, XML 표시- HTML(Hyper Text Markup Language)
- 웹 상의 정보를 구조적으로 표현하기 위한 언어
- 제목, 단락, 링크 등 요소 표시를 위해 Tag를 사용
- 모든 요소들은 꺾쇠 괄호 안에 둘러 쌓여 있음
- 모든 HTML은 트리 모양의 포함관계를 가짐
- 일반적으로 웹 페이지의 HTML 소스파일은 컴퓨터가 다운로드 받은 후 웹 브라우저가 해석/표시
- 왜 웹을 알아야 하는가?
- 정보의 보고, 많은 데이터들이 웹을 통해 공유됨
- HTML도 일종의 프로그램, 페이지 생성 규칙이 있음 : 규칙을 분석하여 데이터의 추출이 가능
- 추출된 데이터를 바탕으로 하여 다양한 분석이 가능
- 정규식 (regular expression)
- 정규 표현식, regexp 또는 regex 등으로 불림
- 복잡한 문자열 패턴을 정의하는 문자 표현 공식
- 특정한 규칙을 가진 문자열의 집합을 추출
- 문법 자체는 매우 방대, 스스로 찾아서 하는 공부 필요
- 필요한 것들은 인터넷 검색을 통해 찾을 수 있음
- 기본적인 것을 공부 한 후 넓게 적용하는 것이 중요
- XML
- 데이터의 구조와 의미를 설명하는 TAG(MarkUp)를 사용하여 표시하는 언어
- TAG와 TAG사이에 값이 표시되고, 구조적인 정보를 표현할 수 있음
- HTML과 문법이 비슷, 대표적인 데이터 저장 방식
- 정보의 구조에 대한 정보인 스키마와 DTD 등으로 정보에 대한 정보(메타정보)가 표현되며, 용도에 따라 다양한 형태로 변경가능
- XML은 컴퓨터(예: PC ↔ 스마트폰)간에 정보를 주고받기 매우 유용한 저장 방식으로 쓰이고 있음
- XML도 HTML과 같이 구조적 markup 언어
- 정규표현식으로 Parsing이 가능함
- 그러나 좀 더 손쉬운 도구들이 개발되어 있음
- 가장 많이 쓰이는 parser인 beautifulsoup으로 파싱
- BeautifulSoup
- HTML, XML등 Markup 언어 Scraping을 위한 대표적인 도구
- lxml 과 html5lib 과 같은 Parser를 사용함
- 속도는 상대적으로 느리나 간편히 사용할 수 있음
- JSON
- JavaScript Object Notation
- 원래 웹 언어인 Java Script의 데이터 객체 표현 방식
- 간결성으로 기계/인간이 모두 이해하기 편함
- 데이터 용량이 적고, Code로의 전환이 쉬움
- 이로 인해 XML의 대체제로 많이 활용되고 있음
- Python의 Dict Type과 유사, key:value 쌍으로 데이터 표시
- json 모듈을 사용하여 손 쉽게 파싱 및 저장 가능
- 데이터 저장 및 읽기는 dict type과 상호 호환 가능
- 웹에서 제공하는 API는 대부분 정보 교환 시 JSON 활용
- 페이스북, 트위터, Github 등 거의 모든 사이트
- 각 사이트 마다 Developer API의 활용법을 찾아 사용
- JSON 파일의 구조를 확인 → 읽어온 후 → Dict Type처럼 처리
- Dict Type으로 데이터 저장 → josn모듈로 Write
[Python Basic for AI] numpy
- numpy
- Numerical Python
- 파이썬의 고성능 과학 계산용 패키지
- Matric와 Vector와 같은 Array 연산의 사실상의 표준
- 한글에서는 넘파이로 주로 통칭
- 누군가는 넘피/늄파이라고 부르기도 함
- 일반 List에 비해 빠르고, 메모리 효율적
- 반복문 없이 데이터 배열에 대한 처리를 지원함
- 선형대수와 관련된 다양한 기능을 제공함
- C, C++, 포트란 등의 언어와 통합 가능
- import numpy as np
- numpy의 호출 방법
- 일반적으로 numpy는 np라는 alias(별칭)를 이용해서 호출함
- 특별한 이유는 없음, 세계적인 약속같은 것
- numpy는 np.array 함수를 활용하여 배열을 생성함 -> ndarray
- numpy는 하나의 데이터 type만 배열에 넣을 수 있음
- List와 가장 큰 차이점 -> dynamic typing not supported
- C의 Array를 사용하여 배열을 생성함
- shape : numpy array의 dimension 구성을 반환함
- dtype : numpy array의 데이터 type을 반환함
- array의 RANK에 따라 불리는 이름이 있음
- 0 Rank : scalar
- 1 Rank : vector
- 2 Rank : matrix
- 3 Rank : 3-tensor
- n Rank : n-tensor
- C의 data type과 compatible
- nbytes : ndarray object의 메모리 크기를 반환함
- reshape : Array의 shape의 크기를 변경함, element의 갯수는 동일
- flatten : 다차원 array를 1차원 array로 변환
- indexing for numpy array
- list와 달리 이차원 배열에서 [0,0] 표기법을 제공함
- matrix일 경우, 앞은 row 뒤는 column을 의미함
- slicing for numpy array
- list와 달리 행과 열 부분을 나눠서 slicing이 가능함
- matrix의 부분 집합을 추출할 때 유용함
- arange : array의 범위를 지정하여, 값의 list를 생성하는 명령어
- zeros : 0으로 가득찬 ndarray 생성
- ones : 1로 가득찬 ndarray 생성
- empty : shape만 주어지고 비어있는 ndarray 생성 (memory initialization이 되지 않음)
- something_like : 기존 ndarray의 shape 크기 만큼 1, 0 또는 empty array를 반환
- identity : 단위 행렬(i 행렬)를 생성함
- eye : 대각선인 1인 행렬, k값의 시작 index의 변경이 가능
- diag : 대각 행렬의 값을 추출함
- random : 데이터 분포에 따른 sampling으로 array를 생성
- sum : ndarray의 element들 간의 합을 구함, list의 sum 기능과 동일
- axis : 모든 operation function을 실행할 때, 기준이 되는 dimension 축
- mean : ndarray의 element들 간의 평균 반환
- std : ndarray의 element들 간의 표준 편차를 반환
- mathemarical functions : 그 외에도 다양한 수학 연산자를 제공함 (np.something 호출)
- concatenate : numpy array를 합치는 (붙이는) 함수
- Dot product : Matrix의 기본 연산, dot 함수 사용
- transpose : transpose 또는 T attribute 사용
- broadcasting : Shape이 다른 배열 간의 연산을 지원하는 기능
- timeit : jupyter 환경에서 코드의 퍼포먼스를 체크하는 함수
- 일반적으로 속도는 for loop < list comprehension< numpy이다.
- 100,000,000번의 loop가 돌 때, 약 4배 이상의 성능 차이를 보임
- Numpy는 C로 구현되어 있어, 성능을 확보하는 대신 파이썬의 가장 큰 특징인 dynamix typing을 포기함
- 대용량 계산에서는 가장 흔히 사용됨
- Concatenate처럼 계산이 아닌, 할당에서는 연상 속도의 이점이 없음
- any : 하나라도 조건에 만족한다면 True
- all : 모두가 조건에 만족한다면 True
- >, <, == : numpy가 배열의 크기가 동일 할 때, element 간의 비교의 결과를 배열의 크기만큼 Boolean type으로 반환
- np.logical_and, np.logical_or, : Boolean type의 두 배열의 element 간 연산 결과
- np.logical_not : Boolean type의 배열의 element에 not 적용
- np.where : 조건에 만족하는 index 반환, True인 index의 값들 변환, False인 index의 값들 변환
- argmax & argmin : array 내 최댓값 또는 최솟값의 index를 반환함
- boolean index : 특정 조건에 따른 값을 배열 형태로 추출, Comparison operation 함수들도 모두 사용 가능
- fancy index : numpy는 array를 index value로 사용해서 값 추출, matrix 형태의 데이터도 가능
- loadtxt & savetxt : text type의 데이터를 읽고, 저장하는 기능
[AI Math] 통계학 맛보기
- 모수가 뭐에요?
- 통계적 모델링은 적절한 가정 위에서 확률분포를 추정(inference)하는 것이 목표이며, 기계학습과 통계학이 공통적으로 추구하는 목표입니다.
- 그러나 유한한 개수의 데이터만 관찰해서 모집단의 분포를 정확하게 알아낸다는 것은 불가능하므로, 근사적으로 확률분포를 추정할 수 밖에 없습니다.
- 데이터가 특정 확률분포를 따른다고 선험적으로(a priori) 가정한 후 그 분포를 결정하는 모수(parameter)를 추정하는 방법을 모수적(parametric) 방 법론이라 합니다.
- 특정 확률분포를 가정하지 않고 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌면 비모수(nonparametric) 방법론이라 부릅니다.
- 확률분포 가정하기: 예제
- 확률분포를 가정하는 방법: 우선 히스토그램을 통해 모양을 관찰합니다.
- 데이터가 2개의 값(0 또는 1)만 가지는 경우 → 베르누이분포
- 데이터가 개의 이산적인 값을 가지는 경우 → 카테고리분포
- 데이터가 [0,1] 사이에서 값을 가지는 경우 → 베타분포
- 데이터가 0 이상의 값을 가지는 경우 → 감마분포, 로그정규분포 등
- 데이터가 ℝ 전체에서 값을 가지는 경우 → 정규분포, 라플라스분포 등
- 기계적으로 확률분포를 가정해서는 안 되며, 데이터를 생성하는 원리를 먼저 고려하는 것이 원칙입니다.
- 각 분포마다 검정하는 방법들이 있으므로 모수를 추정한 후에는 반드시 검정을 해야 한다.
- 데이터로 모수를 추정해보자!
- 데이터의 확률분포를 가정했다면 모수를 추정해볼 수 있습니다.
- 정규분포의 모수는 평균 과 분산 으로 이를 추정하는 통계량(statistic)은 다음과 같다.
- 통계량의 확률분포를 표집분포(sampling distribution)라 부르며, 특히 표본평균의 표집분포는 이 커질수록 정규분포 를 따릅니다.
- 최대가능도 추정법
- 표본평균이나 표본분산은 중요한 통계량이지만 확률분포마다 사용하는 모수가 다르므로 적절한 통계량이 달라지게 됩니다.
- 이론적으로 가장 가능성이 높은 모수를 추정하는 방법 중 하나는 최대가능도 추정법(maximum likelihood estimation, MLE)입니다.
- 가능도(liklihood) 함수는 모수 를 따라는 분포가 를 관찰할 가능성을 뜻하지만 확률로 해석하면 안됩니다.
- 데이터 집합 가 독립적으로 추출되었을 경우 로그가능도를 최적화합니다.
- 왜 로그가능도를 사용하나요?
- 로그가능도를 최적화하는 모수 는 가능도를 최적화하는 MLE 가 됩니다.
- 데이터의 숫자가 적으면 상관없지만 만일 데이터의 숫자가 수억 단위가 된다면 컴퓨터의 정확도로는 가능도를 계산하는 것은 불가능합니다.
- 데이터가 독립일 경우, 로그를 사용하면 가능도의 곱셈을 로그가능도의 덧셈으로 바꿀 수 있기 때문에 컴퓨터로 연산이 가능해집니다.
- 경사하강법으로 가능도를 최적화할 때 미분 연산을 사용하게 되는데, 로그가능도를 사용하면 연산량을 에서 으로 줄여줍니다.
- 대게의 손실함수의 경우 경사하강법을 사용하므로 음의 로그가능도(negative log-likelihood)를 최적화하게 됩니다.
- 딥러닝에서 최대가능도 추정법
- 최대가능도 추정법을 이용해서 기계학습 모델을 학습할 수 있습니다.
- 딥러닝 모델의 가중치를 라 표기했을 때 분류 문제에서 소프트맥스 벡터는 카테고리분포의 모수 를 모델링합니다.
- 원핫벡터로 표현한 정답레이블 을 관찰데이터로 이용해 확률분포인 소프트맥스 벡터의 로그가능도를 최적화할 수 있습니다.
- 확률분포의 거리를 구해보자
- 기계학습에서 사용되는 손실함수들은 모델이 학습하는 확률분포와 데이터에서 관찰되는 확률분포의 거리를 통해 유도합니다.
- 데이터공간에 두 개의 확률분포 가 있을 경우 두 확률분포 사이의 거리(distance)를 계산할 때 다음과 같은 함수들을 이용합니다.
- 총변동 거리 (Total Variation Distance, TV)
- 쿨백-라이블러 발산 (Kullback-Leibler Divergence, KL)
- 바슈타인 거리 (Wasserstein Distance)
[AI Math] 베이즈 통계학 맛보기
- 조건부 확률이란?
- 베이즈 통계학을 이해하기 위해선 조건부확률의 개념을 이해해야 합니다.
- 조건부확률 는 사건 가 일어난 상황에서 사건 가 발생할 확률을 의미한다.
- 베이즈 정리는 조건부확률을 이용하여 정보를 갱신하는 방법을 알려줍니다.
- 라는 새로운 정보가 주어졌을 때 로 부터 를 계산하는 방법을 제공한다.
- 베이즈 정리: 예제
- COVID-99의 발병률이 10% 로 알려져있다. COVID-99에 실제로 걸렸을 때 검진될 확률은 99%, 실제로 걸리지 않았을 때 오검진될 확률이 1%라고 할때, 어떤사람이 질병에 걸렸다고 검진결과가 나왔을 때 정말로 COVID-99에 감염되었을 확률은?
- 사전확률, 민감도(Recall), 오탐률(False alarm)을 가지고 정밀도(Precision)를 계산하는 문제이다.
- 사전확률 : 발병률 10%, 가능도 : 제로 걸렸을 때 검진될 확률은 99%, 실제로 걸리지 않았을 때 오검진될 확률이 1%
- 를 COVID-99 발병 사건으로 정의(관찰 불가)하고, 𝒟를 테스트 결과라고 정의(관찰 가능)한다.
- 만일 오검진될 확률(1종 오류)이 10%라면 아래와 같다.
- 오탐율(False alarm)이 오르면 테스트의 정밀도(Precision)가 떨어진다.
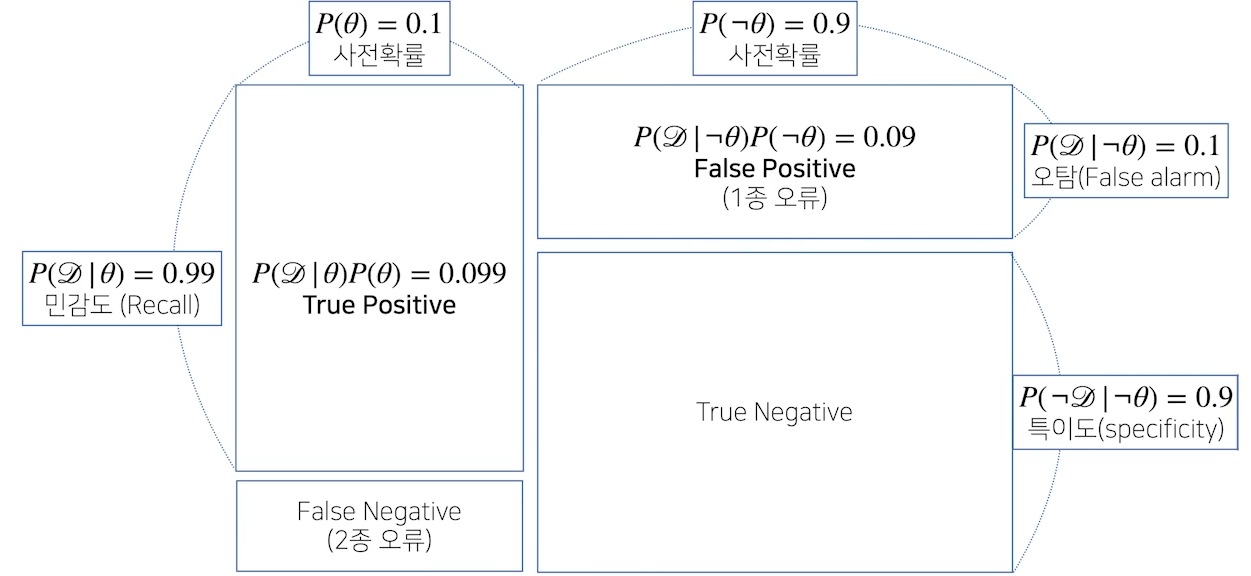
- 조건부 확률의 시각화
[AI Math] 첫걸음
- Convolution 연산 이해하기
- 지금까지 배운 다층신경망(MLP)은 각 뉴런들이 선형모델과 활성함수로 모두 연결된 (fully connected) 구조였습니다.
- Convolution 연산은 이와 달리 커널(kernel)을 입력벡터 상에서 움직여가 면서 선형모델과 합성함수가 적용되는 구조입니다.
- Convolution 연산의 수학적인 의미는 신호(signal)를 커널을 이용해 국소적 으로 증폭 또는 감소시켜서 정보를 추출 또는 필터링하는 것입니다.
- 커널은 정의역 내에서 움직여도 변하지 않고(translation invariant) 주어진 신호에 국소적(local)으로 적용합니다.
- Convolution 연산은 1차원뿐만 아니라 다양한 차원에서 계산 가능합니다.
- 2차원 Convolution 연산 이해하기
2D-Conv 연산은 이와 달리 커널(kernel)을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조입니다.- 입력 크기를 (H, W), 커널 크기를 (KH, KW), 출력 크기를 (OH, OW)라 하면 출력 크기는 다음과 같이 계산합니다.
- OH = H - KH + 1
- OW = W - KW + 1
- 3차원 Convolution 연산 이해하기
- 3차원 Convolution 의 경우 2차원 Convolution 을 3번 적용한다고 생각하면 됩니다.
- 텐서를 직육면체 블록으로 이해하면 좀 더 이해하기 쉽습니다.
- Convolution 연산의 역전파 이해하기
- Convolution 연산은 커널이 모든 입력데이터에 공통으로 적용되기 때문에 역전파를 계산할 때도 convolution 연산이 나오게 됩니다.
과제
- Gradient Descent
-- Backpropagation
-- Maximum Likelihood Estimate
-


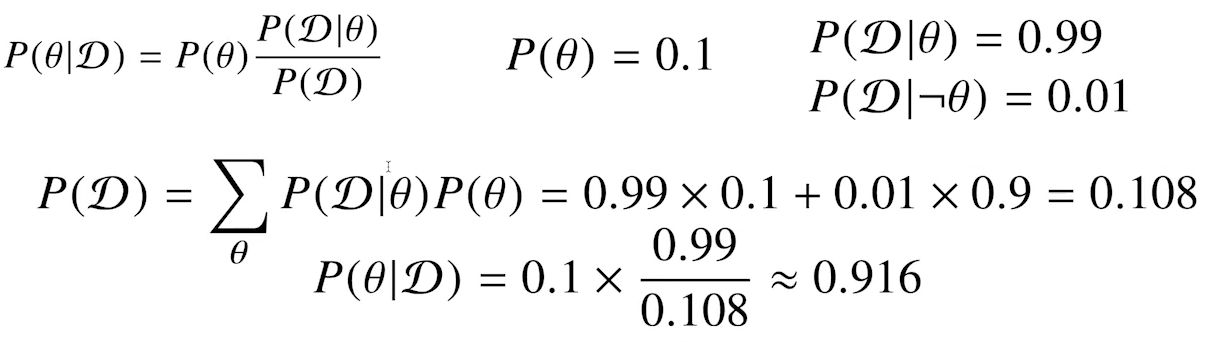
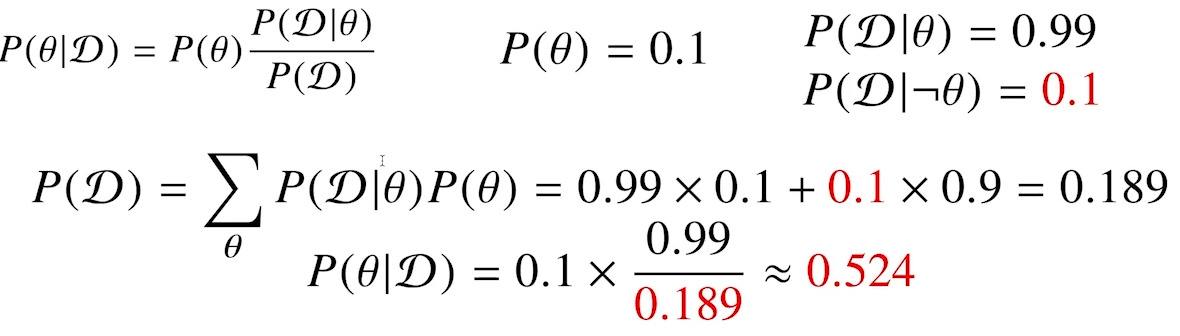
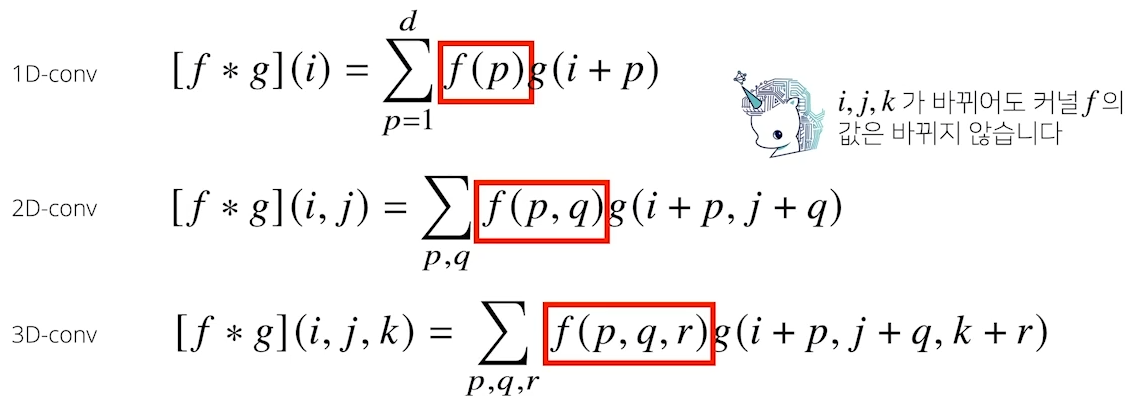
피어세션 정리
- Baseball 과제 코드 리뷰
- 회의록 작성 Notion -> Github wiki로 변경
느낀점
이미 알고 있고 공부한 내용이라 생각했지만, 깊게 들여다 보니 다시 공부하고 정리해야 할 것들이 많았습니다.
개인적으로 공부하다보니 피어세션에 나눌 지식과 생각들을 정리하는 것이 익숙하지는 않았지만, 오늘 처음으로 코드 리뷰를 하며 서로가 서로의 성장에 도움이 되고 있다는 걸 느낄 수 있었습니다:)
앞으로 33조 피어 분들과 무한 성장하겠습니다!!!!
